本記事はNutanix Advent Calendar 2022 12/24 分の記事です。
昨年はプライベートが忙しすぎてお休みしましたが、
今年はAdvent Calendar復帰です。
以前に引き続き、on AWSな感じの投稿です。
1.今回やってみたこと
smzkstsさんの記事でNutanix Cloud Clusters on AWS(NC2A)でノード追加&削除してみたは既に投稿あったので、
同じじゃ面白くないと思案したところで、
クラウド上の環境でもLCMで簡単Upgradeできるよね?という検証と、
最近サポートされるようになったヘテロジニアスなClusterとHibernateをやってみました。
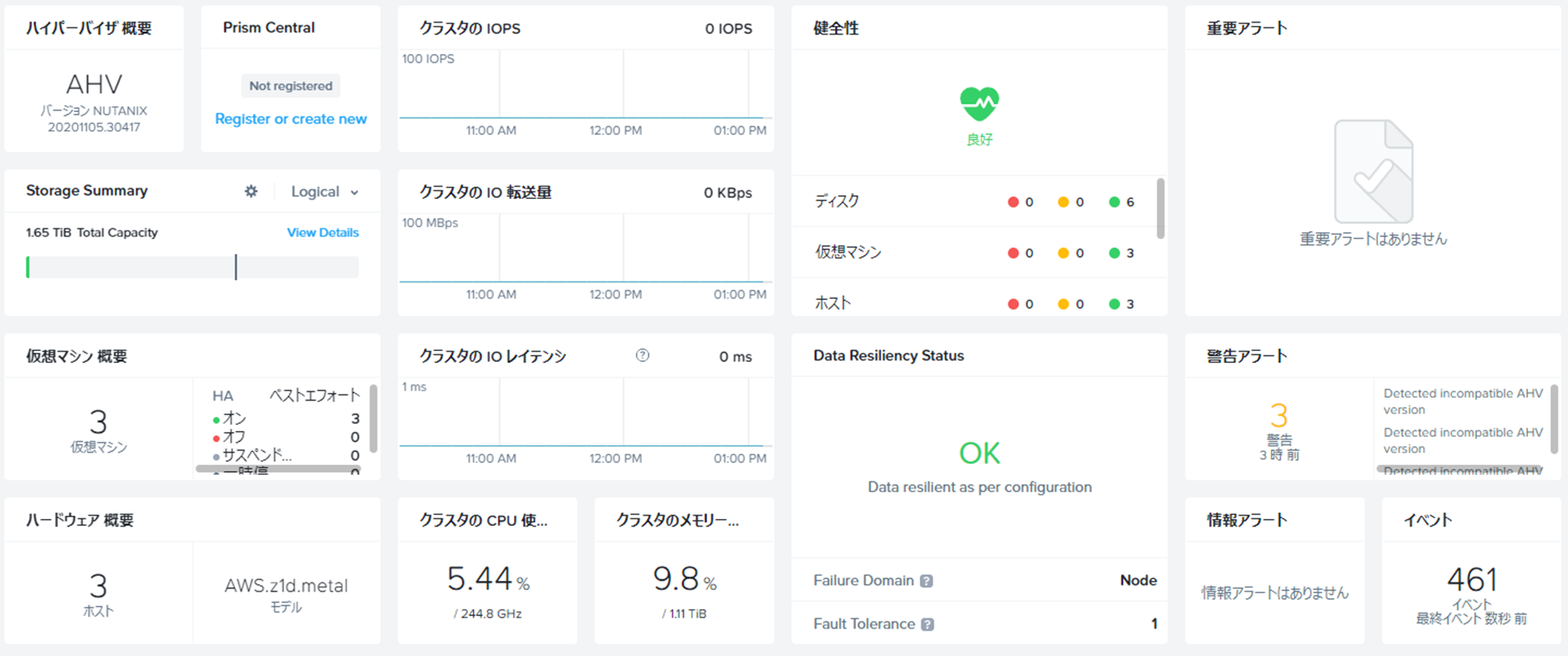
2.LCMによるUpgradeやってみた
今回用意したのはこちらの環境。
AOS6.5ベースで、AWS上にz1d.metalを利用した3Nodeクラスタを作っています。

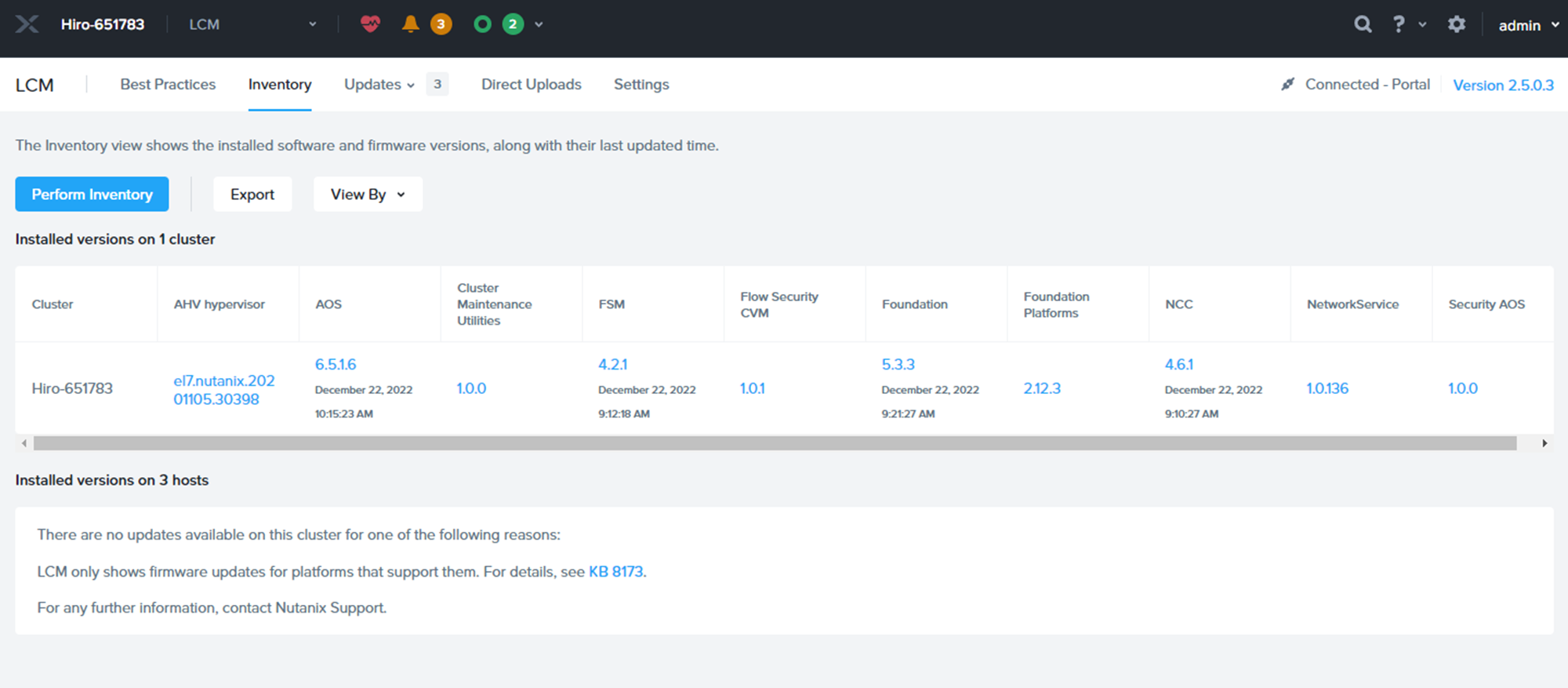
オンプレ環境と同じように、まずはLCMを実行。
インターフェースも含め、オンプレ環境と全く変わりありません。
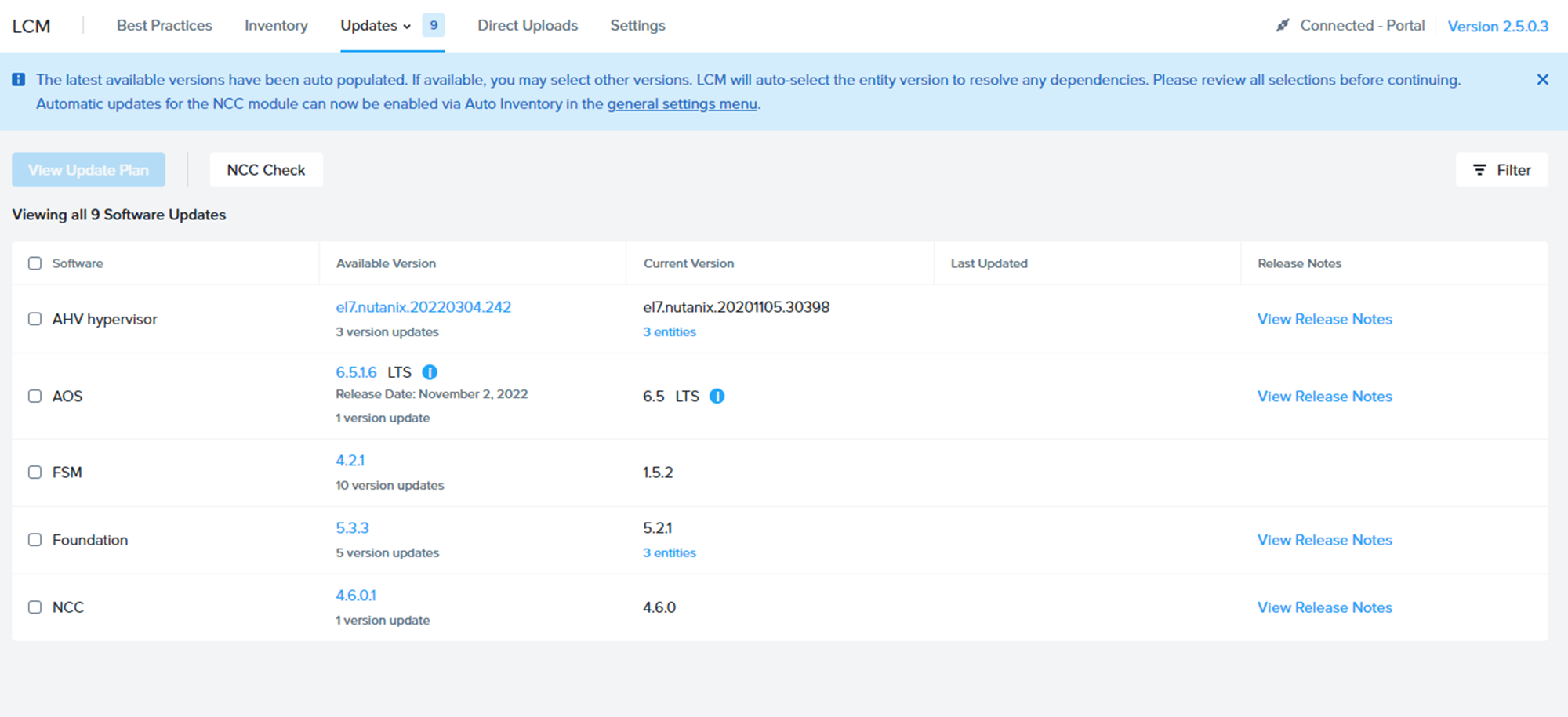
LCMでUpgrade可能なソフトウェアの確認が終わった図。
こちらもオンプレ環境と違いがなさ過ぎて、すり替えてるんじゃないかと疑われるレベル。
まずは無難なモジュール系のみを実行。
これはまあ当然、あっさりと終わりました。
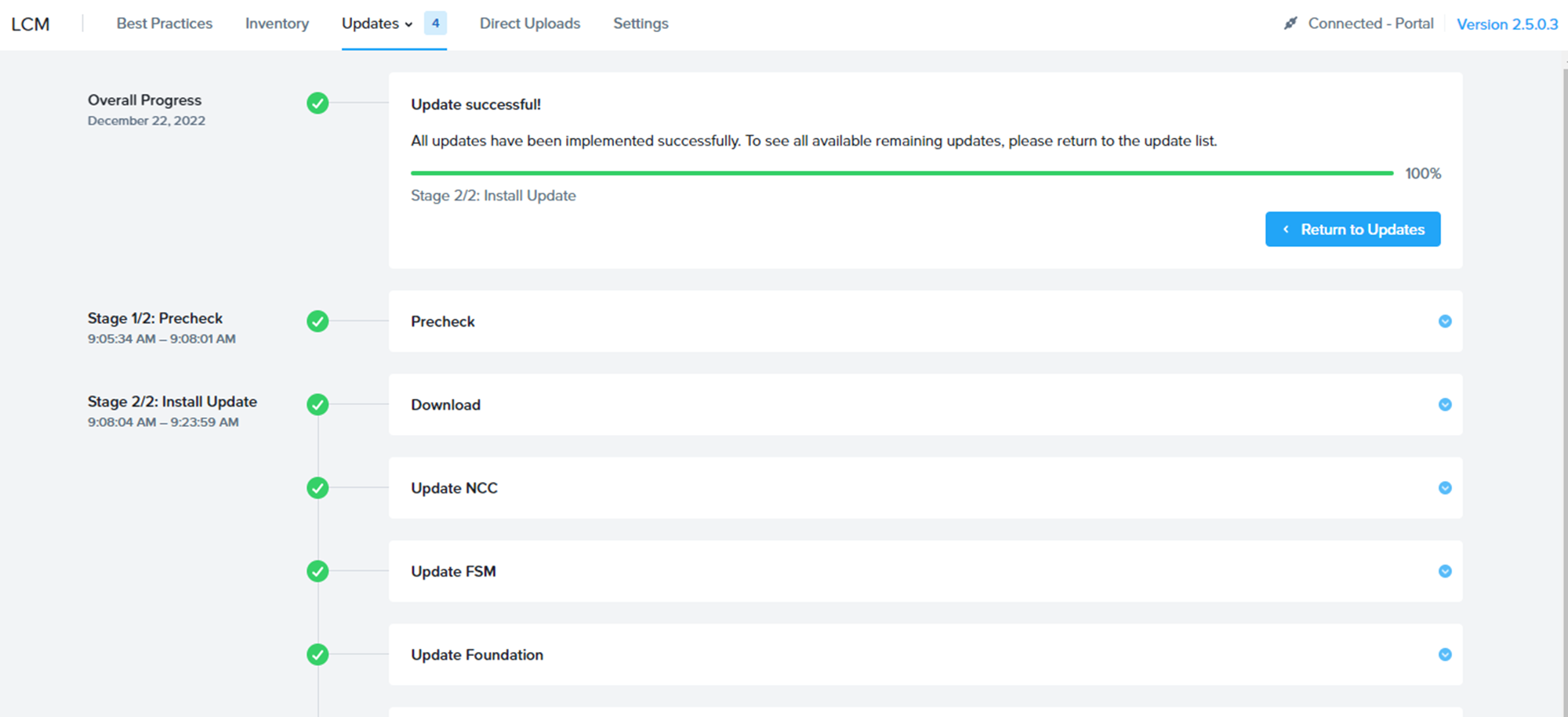
次はAOSのUpgradeに挑戦です。
こちらはCVMの再起動も伴うので、スムーズにいくか。
確認画面もいつも通り。(注 ちゃんとAWS上の環境でやってます)
Prism Centralを先に上げてねの警告もいつも通り。(注 ちゃんとAWS上の環境でやってます)
レッツスタート。
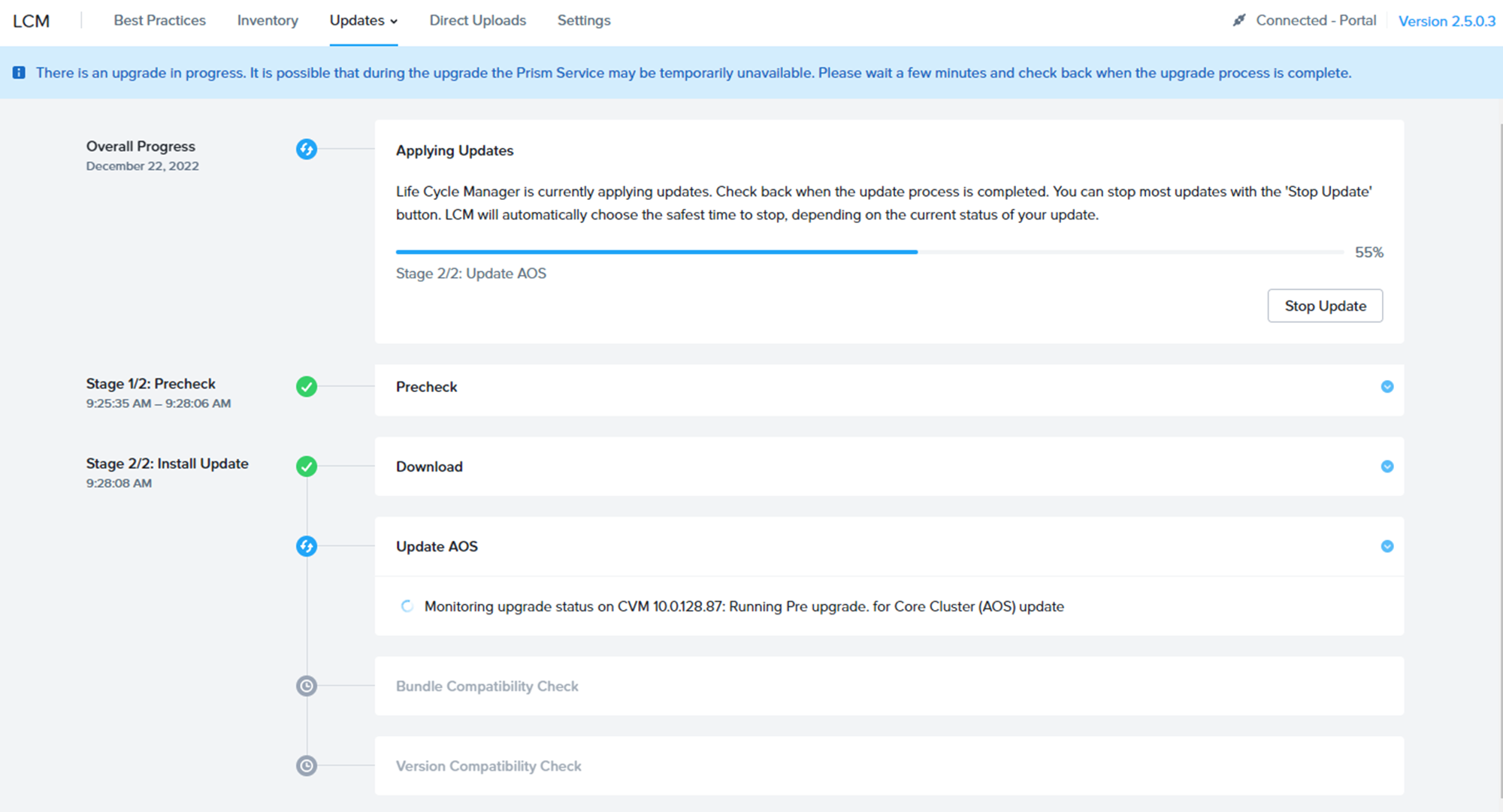
見慣れたUpgrade画面が進んでいきます。
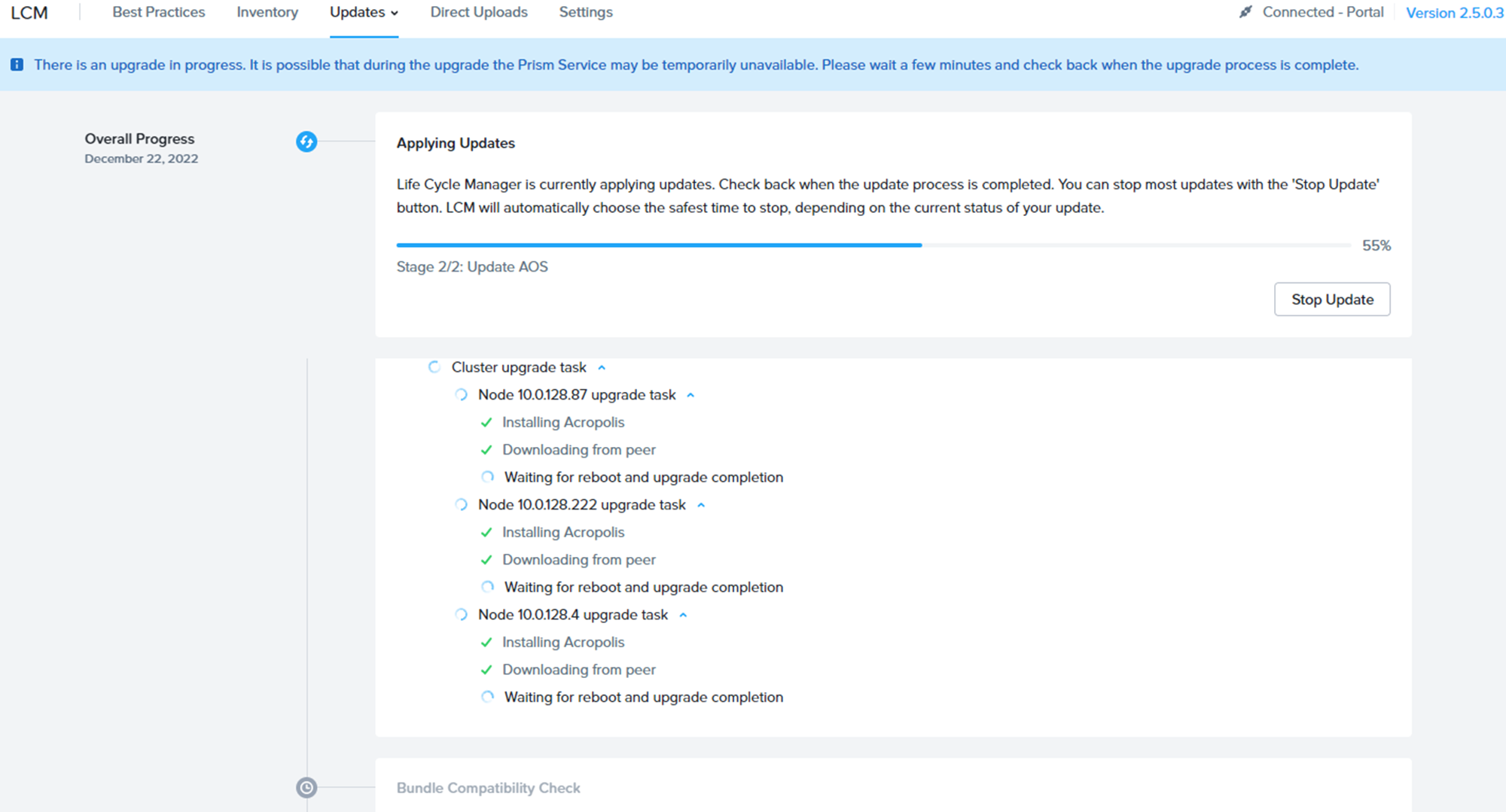
メールなど打っている間に終わってしまった(汗
LCMの完了画面をSS取り損ねましたが、無事6.5.1.6にUpgradeが完了しました。
まあNodeの中のことなので、想定通りです。
今度はAHVの方を上げます。確認画面は前と同じなので割愛。
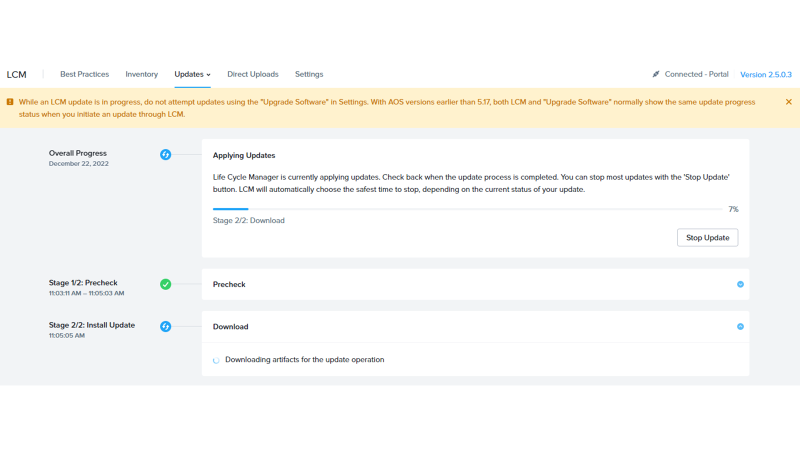
オンプレ環境と同じように1Nodeずつタスクが走っていきます。

こちらもローリングUpgradeで特に何も起こることなく無事終了。(注 ちゃんとAWS上の環境でやってます)
途中、Nodeの再起動が走りますが、そのタイミングでMCMコンソールに登録されているメール宛に、
「Host Agent running on AHV node did not respond to Nutanix Orchestrator for more than 120.0 seconds」
と書かれたメールが来ていました。
Node障害時も含め、こういった監視をMCM側でもしてくれているようです。
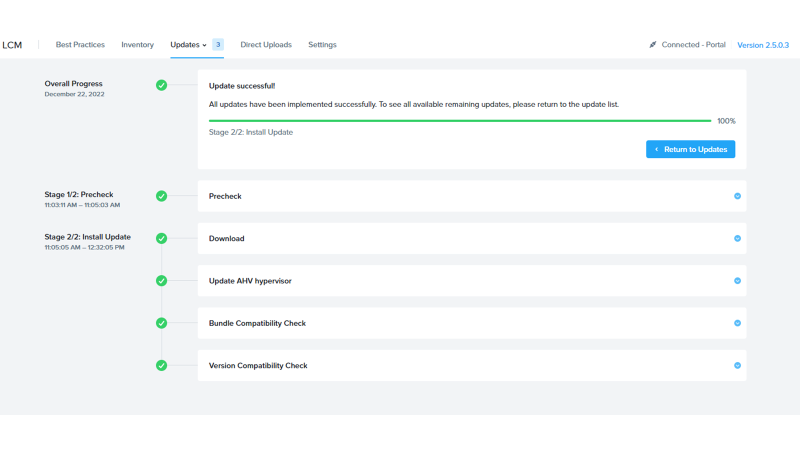
ということで、記事だから割愛している訳ではなく、
途中でエラーやらなにやら起こることもなく、スムーズにUpgrade完了しました。
個別で様々なカスタマイズしているオンプレ環境よりも、
変動要素が少ないため、むしろよりスムーズなのかもしれません。
今回、最新のLTSであるAOS6.5系で試しましたが、
AOS5.20系でもNC2Aの利用は可能ですので、
コンパチビリティも確認の上、ご利用ください。
3.ヘテロジニアスクラスタやってみた
さて今度はヘテロジニアスクラスタです。
冒頭掲載の様に、ベース環境はz1d.metalを3Nodeで構成しています。
単なるNode拡張はsmzkstsさんの記事を参照いただくとして、
ここではスペックの異なるNodeの拡張を実施してみたいと思います。
まずNC2Aでは以下のインスタンスが利用可能です。
z1d.metal
m5d.metal
i3.metal
i3en.metal
g4dn.metal(GPU搭載)
このうち、混ぜることが可能なインスタンスタイプが決まっています。
次の2グループが単一クラスタの中で混在可能なインスタンスであり、
現在このグループを超えて混ぜることはできないです。
【グループ1】
z1d.metal
m5d.metal
【グループ2】
i3.metal
i3en.metal
見てわかるようにGPU搭載Nodeはいずれとも混在不可というのが、
本投稿執筆時点の状況です。
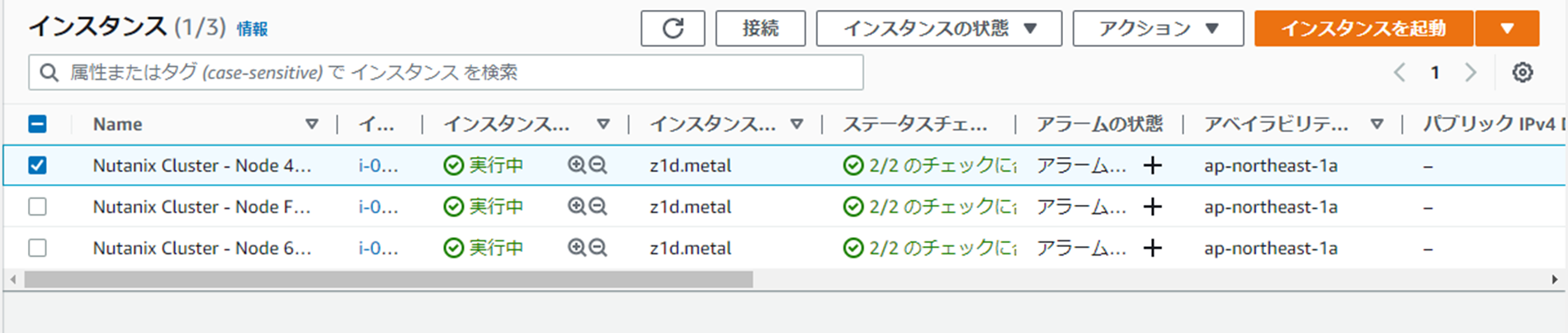
今回はz1d.metalをベースにクラスタを作っていましたので、m5d.metalを追加することになります。
AWSマネジメントコンソール側で見るとこんな感じ。
Node拡張というと、Prismのハードウェア画面でやるのがオンプレ環境の定石ですが、
NC2A環境では、下図の通りここで操作できないようになっています。
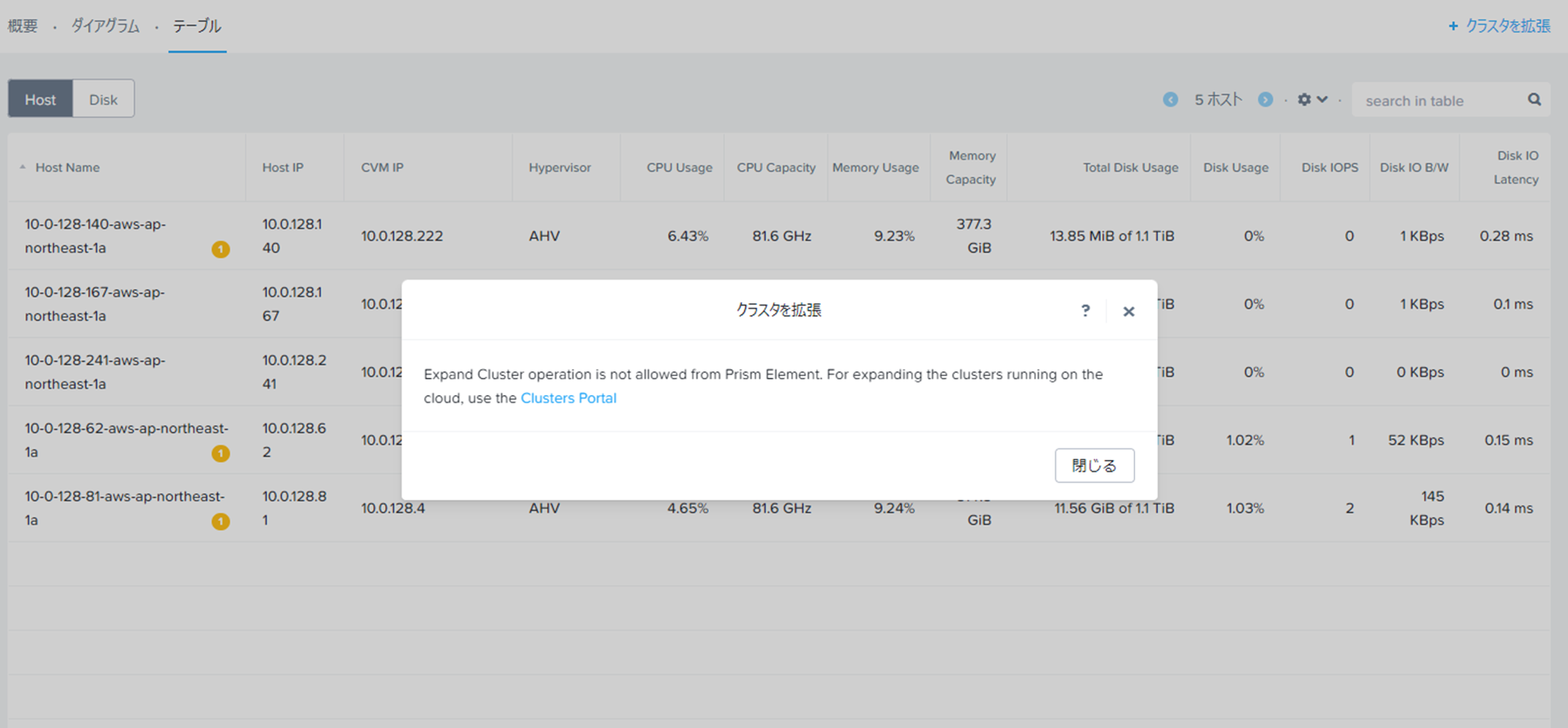
ではどこでやるかですが、MCMコンソールというNC2環境を管理するためのポータルサイト側です。
アクセスはMy Nutanixの方からどうぞ。
そちらのクラスタ管理メニューからCapacityのUpdateを行う画面にくると、下図のようになっています。
見てわかる通り、拡張可能なインスタンスが初めから書いてあるので、拡張できるものの選択で迷うことはないですね。
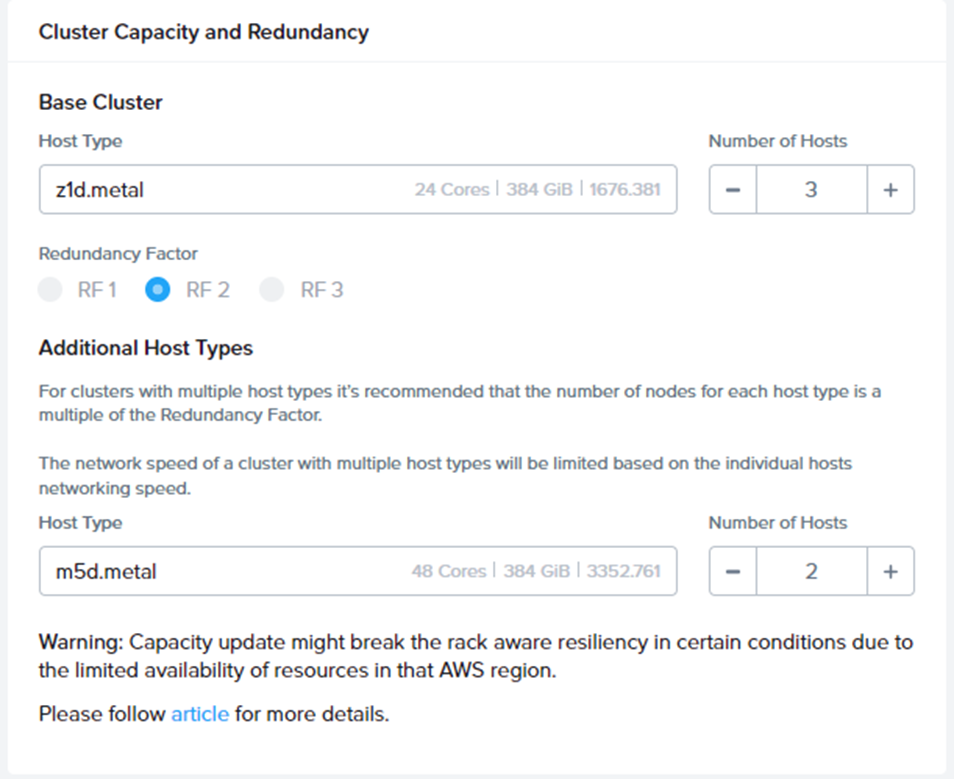
ここではm5d.metalを2Node追加してみたいと思います。
ちなみに異なるNodeタイプを拡張する場合は、2Node以上をお勧めされます。
Node間で持ってるDISK量が違うので、Failover時のことを考えた処置ということになります。
ということで、2Node追加の指示をしてみます。
数字を画面の様に2にしてSaveするだけで、自動的に追加が実行されます。
Prismの方で待ち構えていると・・・タスクが始まりました。
順次Node追加が実行されていきます。
この辺のコントロールはMCMコンソールが良しなにやってくれるので簡単です。
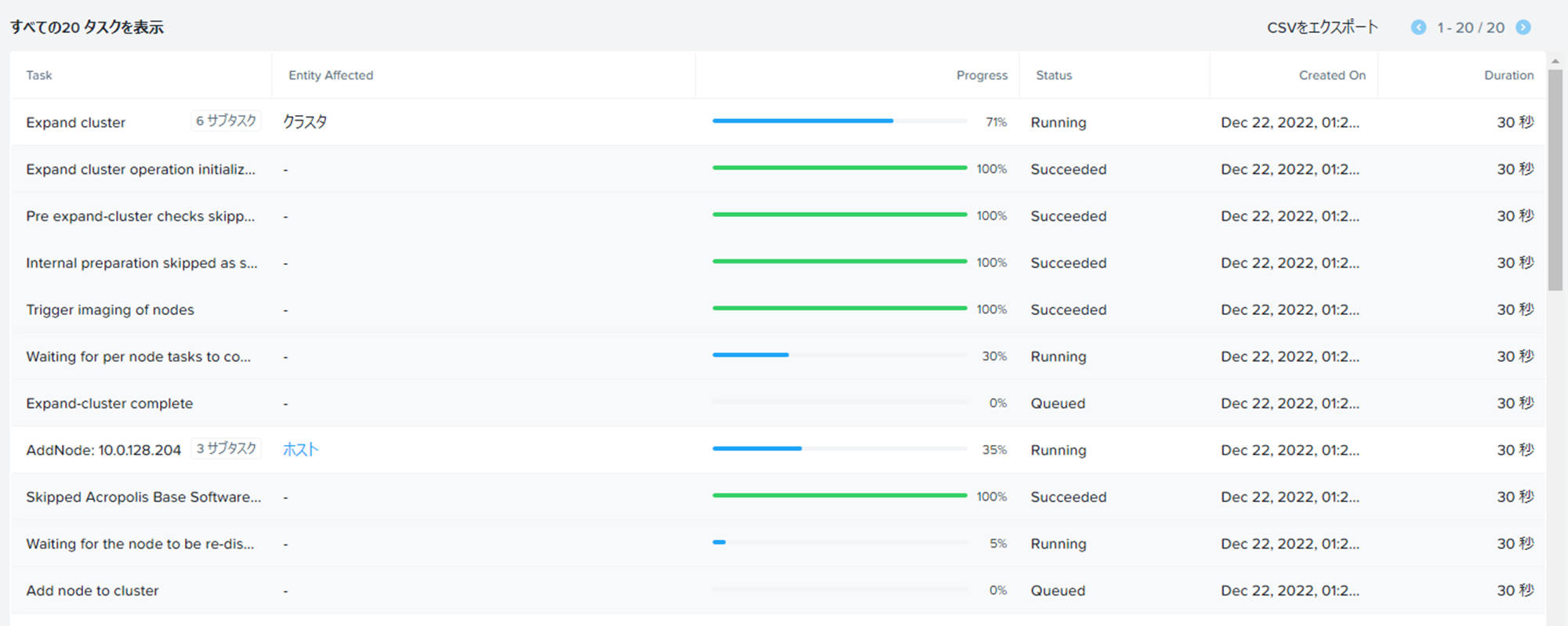
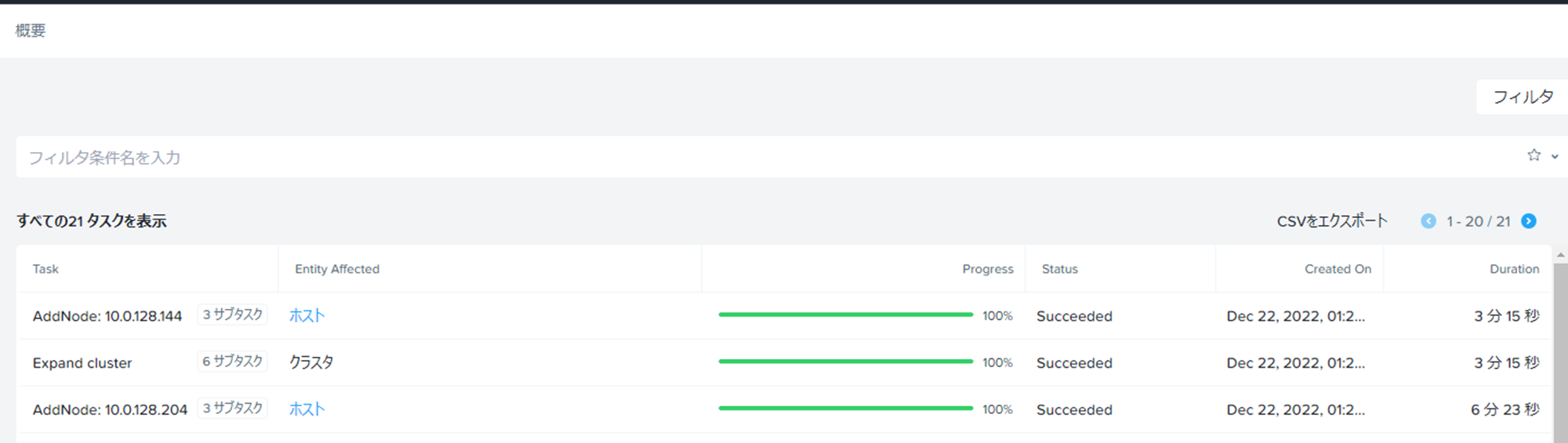
しばらく待っているとNodeが無事追加されました。
オンプレ環境同様でPrism側のタスクが始まってから1Node5分前後で追加できています。
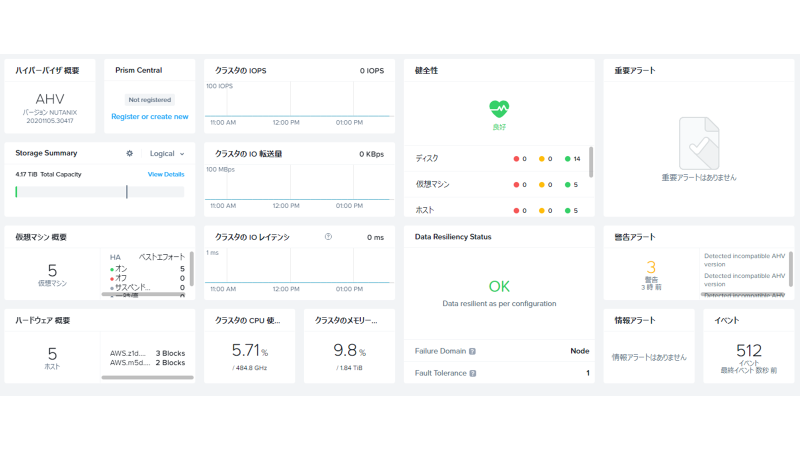
Prismのダッシュボード参照すると計5Nodeになっているのが確認できました。
4.Hibernateやってみた
ここまで検証をやってきましたが、
AWSは使えば使った分だけお金がかかります・・・ということで、
ひとまず検証を休止したい場合もこのままではガッツリ課金されてしまいます。
通常の仮想マシンのEC2インスタンスであれば停止すればよいのですが、
HCIをベースにしている弊社のNC2やVMCなどはそう簡単にはいきません。
何故ならばデータの実態をベアメタルインスタンスのおなかの中のDISKに保存しているので、
インスタンスを停止してそのインスタンスが仮に再利用できなかった場合、
データはどっかに行ってしまうからです。
で、どうしようもないのかと言うと、NC2では対策を実装しています。
それがHibernate機能です。
このHibernate機能がどういうものかというと、
クラスタ内のデータをS3に保存することで、
安全にインスタンスを止めることができるというもの。
インスタンスを止められればコンピューティングに対する課金を停止できるわけです。
実際にやってみましょう。
また再びMCMコンソールの出番です。
当該のクラスタのActionでHibernateを選択します。
なお、実行の前に予めクラスタ内の仮想マシン達は停止しておくのをお忘れなく。
(オンプレ環境でいう、停電対応と同じ状況になりますので)
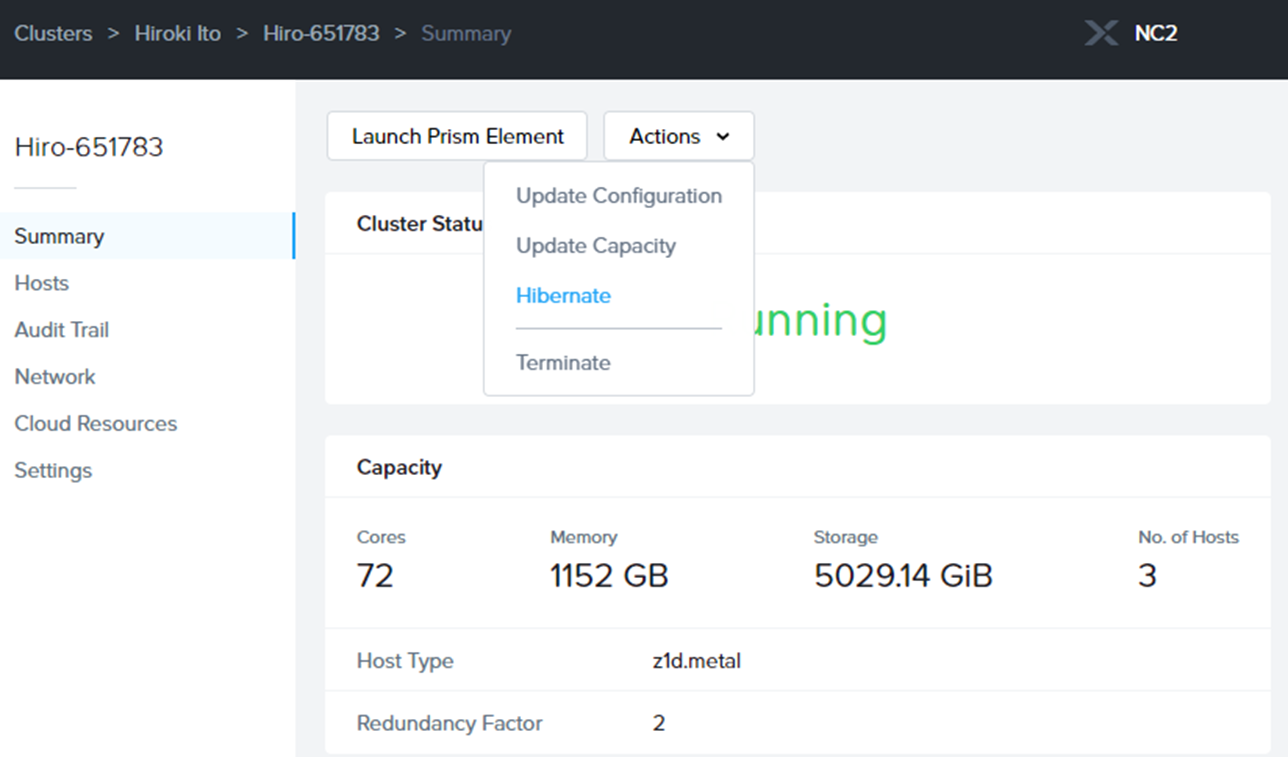
こんな感じで処理が始まります。
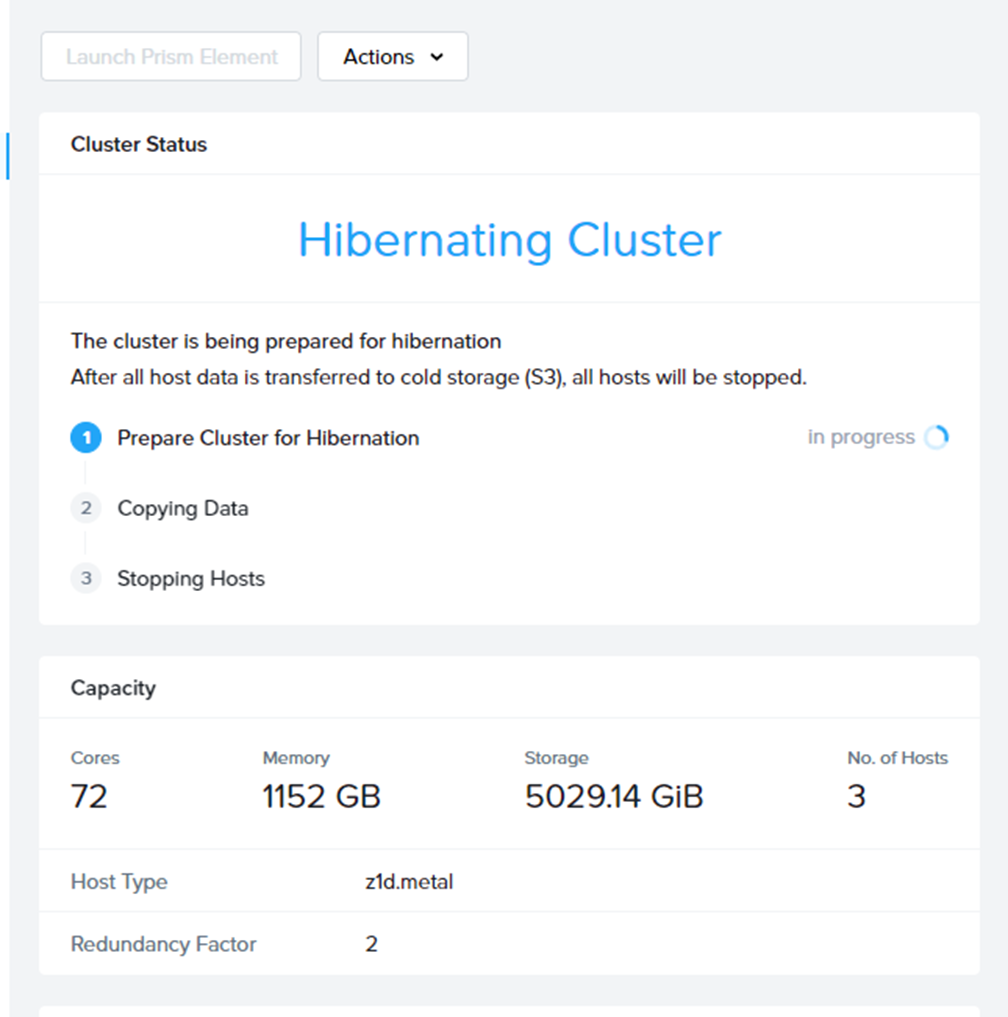
処理の最初にS3にバケットが作られ、データの退避先が用意されます。
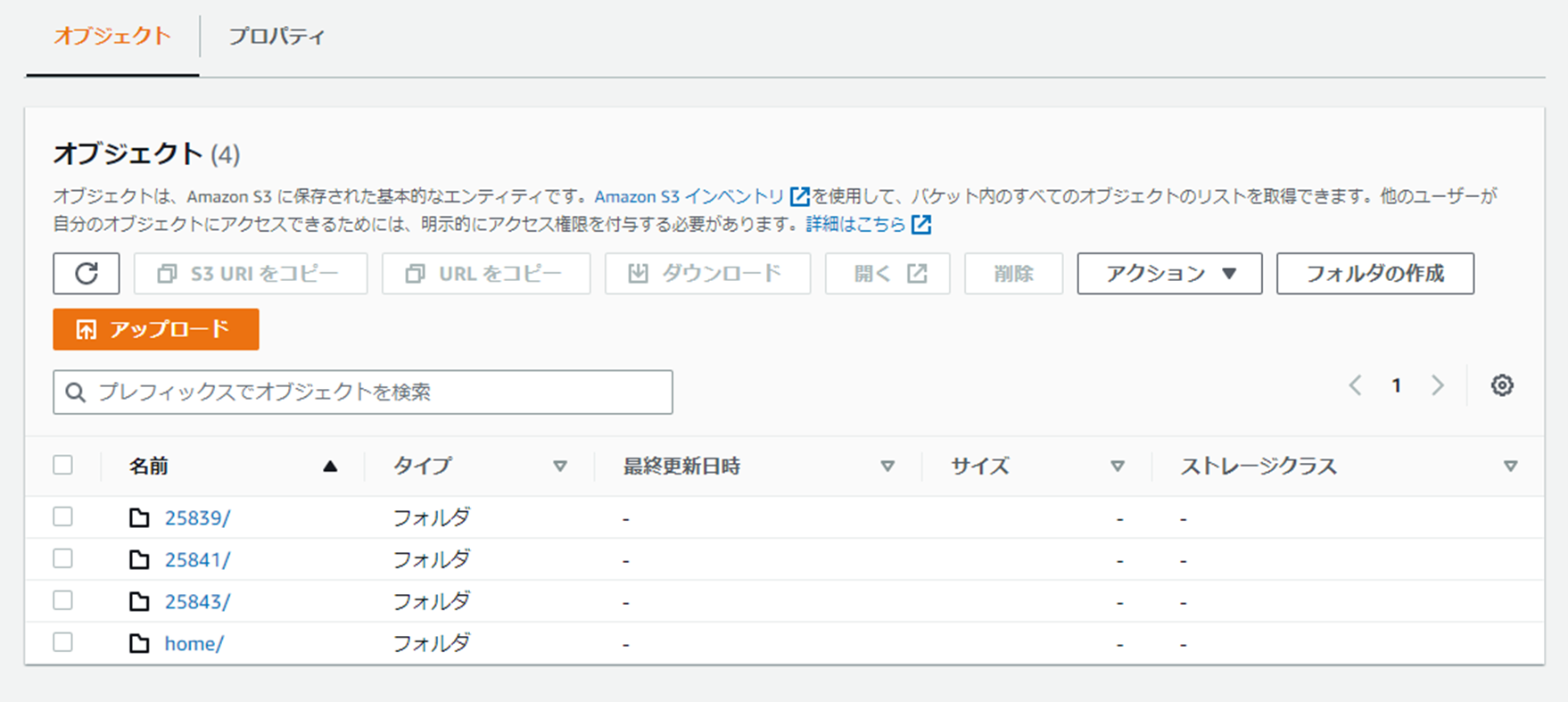
その後、S3バケットに対して、データのコピーが走ります。
かかる時間はクラスタ内のデータ量次第です。
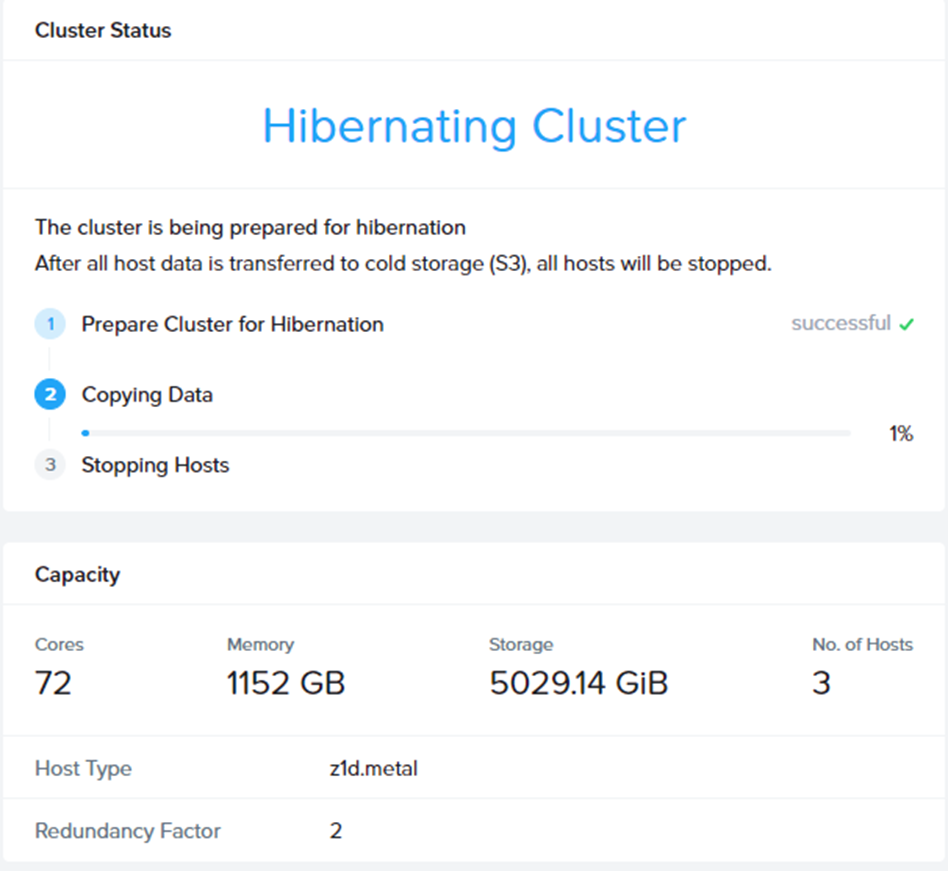
コピー作業が完了したら、最後にインスタンス(Node)の停止が実行されます。
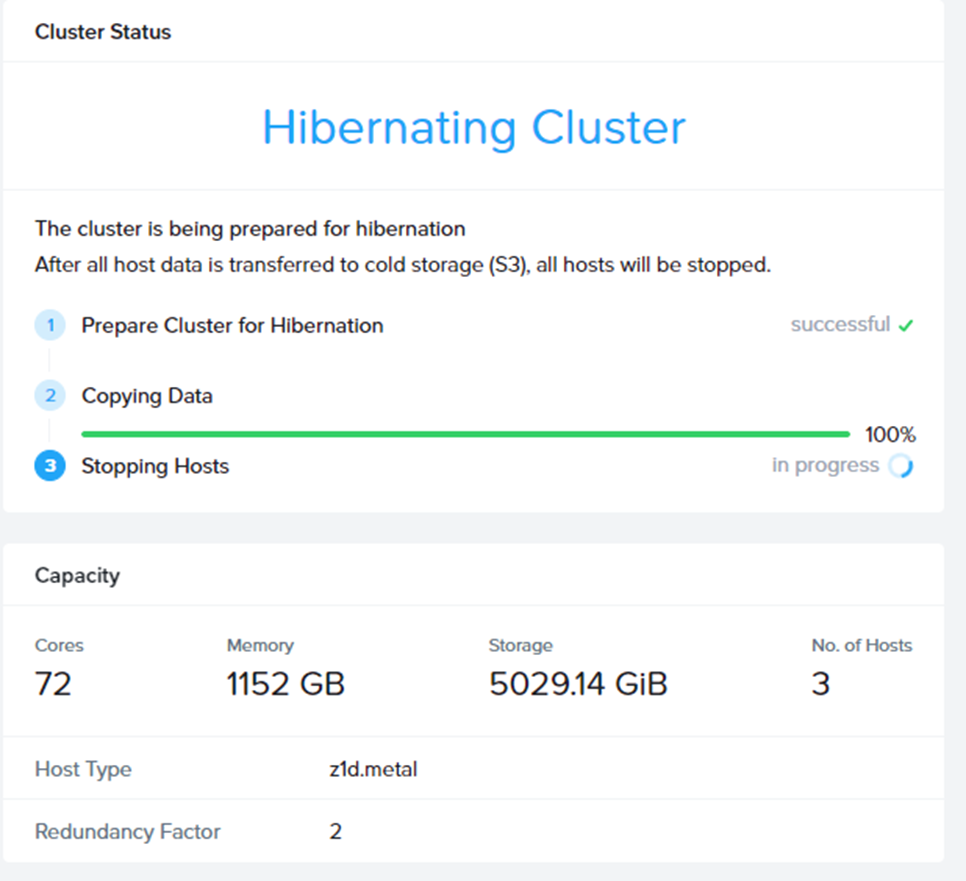
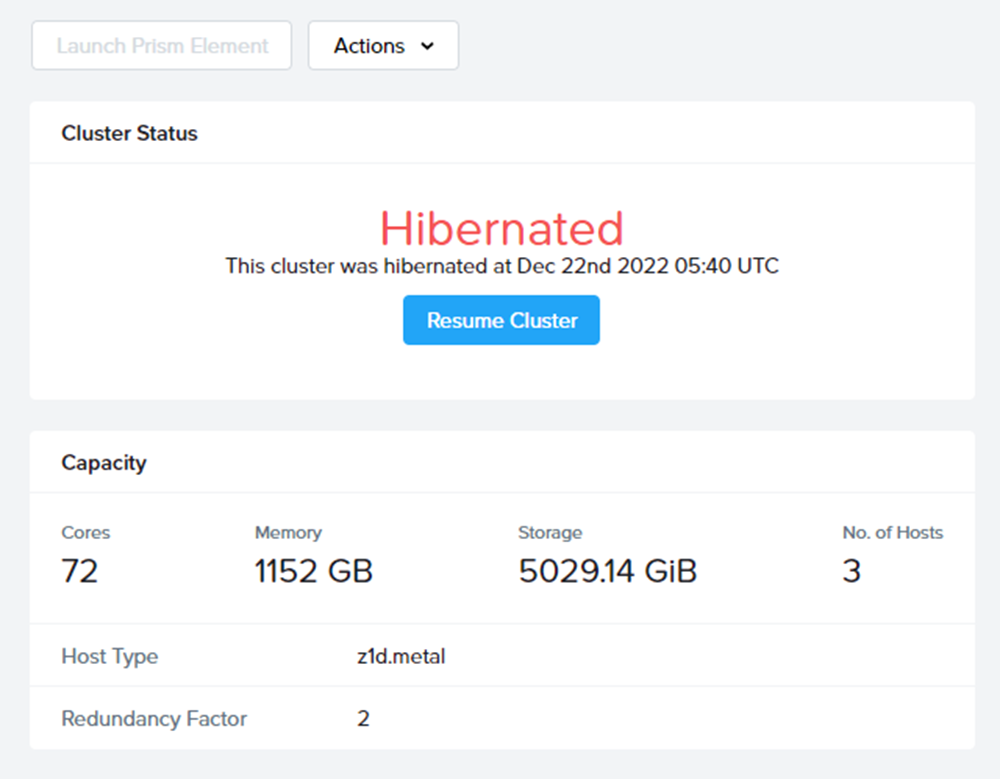
インスタンスが停止完了すると、MCMコンソール上の表記が変わり、
無事Hibernateが終わったことがわかります。
次回再開時は画面上のResumeを押してあげれば、クラスタが再開します。
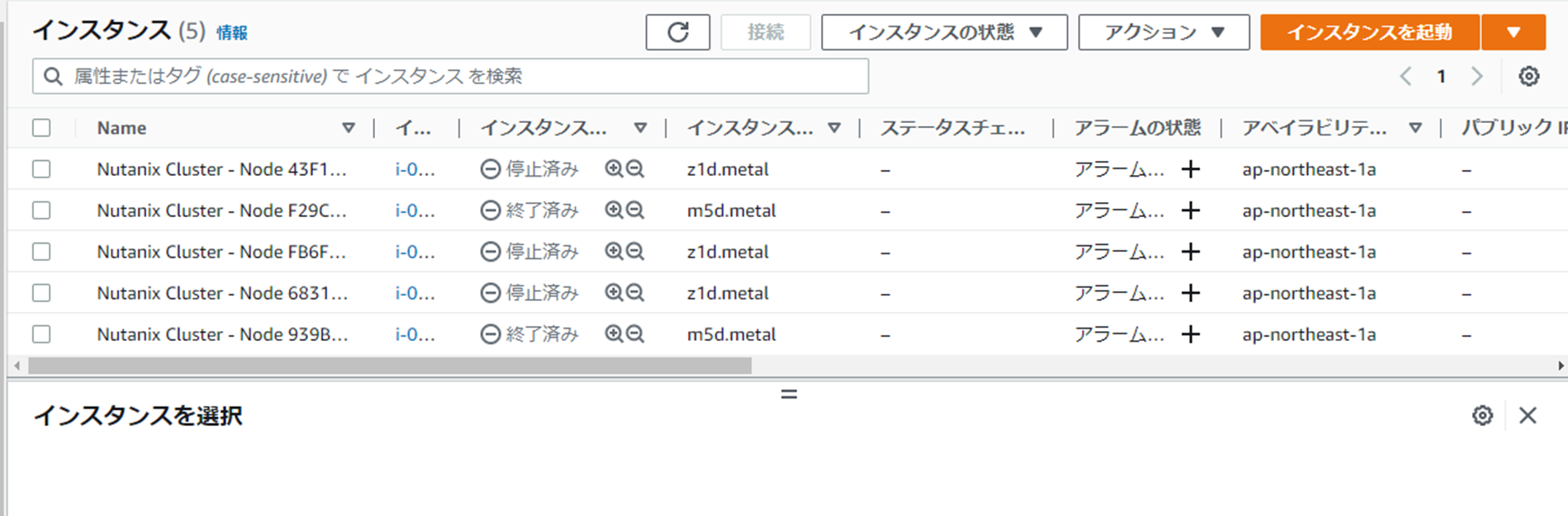
なお、AWSコンソール上で見ても、
各z1dのインスタンスが停止状態になっているのがわかりますね。
これで検証していない間の高額な課金を抑えることができました。
課金に怯えて削除→後日にまた一から環境作成、
ということをしなくともよいので、検証や保守開発時に持ってこいの機能ですね。
今回は以上となります。
明日はNutanix Advent Calendar 2022最終回。
トリはUnno Wataruさんの投稿です。
お楽しみに!
以上、現場からお伝えしました。