【特訓 ver.6】 決定木分析スタート!!
※この記事では、決定木を用いた分類手法についてまとめます
▼学習の流れ
まずは決定木(分類)の基本を押さえ、具体的な分析例を通して理解を深める。
※なお、決定木は、回帰・分類それぞれに用いることができる手法(回帰→回帰木、分類→分類木と呼ぶ)。今回は、分類問題について扱っていきます。
■使用するデータ
Social_Network_Ads.csv
年齢とお給与をもとに、商品を「購入したかどうか」
※データセット:後日
■ 決定木分析について学習する
大まかな流れ)
① データ読み込みや前処理、分割
- 質的変数も適切に数値化(エンコーディング)すれば使用できる
② モデルの設定と訓練
- 「決定木」で実施する
③ モデルの精度の確認
- 精度について、以下6項目で確認していく
分類における「学習モデルの性能評価」について確認していく!
(1) 混同行列(confusion matrix)
(2) 正解率(accuracy)
(3) 適合率(precision)
(4) 再現率(recall)
(5) F1スコア(F1-score)
(6) AUC(曲線下面積)
▼復習
前回扱ったSVM分析に続き、分類手法をもう少し深めていく。
今回は、その中でもよく名前が出てくる、決定木についてみていく。
▼決定木分析とは?
データに基づいた意思決定を行うときに用いられる方法であり、非常にイメージがしやすいものである。
・意思決定とは?
→ 何らかの基準に従って物事を自分で判断すること
例)どのスマートフォンを購入するかを決める
・性能が高いスマートフォン
・価格が手頃なスマートフォン
・カメラ機能が優れているスマートフォン
・バッテリー持続時間が長いスマートフォン
・意思決定を自動化する
→ 自分に代わって誰かに物事を判断してもらうこと
例)コンサル系やショップの販売員がそのお仕事に近い
現状のお悩みや、大切にしたい価値観(「しょっちゅう充電しないといけないのが面倒」「綺麗な写真を撮りたいのに画質がイマイチ」など。)を伝えた上で、提案を受ける(店員さんに判断してもらう)。
上記のようなものを、データに基づいて意思決定を行いたい際に、決定木分析を用いることがある。
▼決定木の特徴
赤か青かを分割したい時。
Yes or No で答えられる条件によって分類をしていく。

ちなみに、これらの条件設定は決定木が自動でしてくれるため、人間が行わなくてよい。
<具体例>
勉強時間、睡眠時間、過去問を解いたかどうかをもとにテストに「合格」するか「不合格」になるかを分類。

実際のデータをもとに用いながら、決定木の理解をさらに深めていく。
特に、条件分岐を増やしすぎると過学習につながることもあるため、条件数を適切に選ぶことを意識する。
それでは実際に使ってみよう!!
【決定木(分類木)】
大まかな流れ
① データ読み込みや前処理、分割
- 質的変数も適切に数値化(エンコーディング)すれば使用できる
② モデルの設定と訓練
- 「決定木分析」で実施する
- その1)枝刈りなし ver.
- その2)枝刈りあり ver.
③ モデルの精度の確認
- 精度について、以下6項目で確認していく
(1) 混同行列(confusion matrix)
(2) 正解率(accuracy)
(3) 適合率(precision)
(4) 再現率(recall)
(5) F1スコア(F1-score)
(6) AUC(曲線下面積)
① データ読み込みや前処理、分割
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# データの読み込み
df = pd.read_csv("/content/Social_Network_Ads.csv")
df.head()
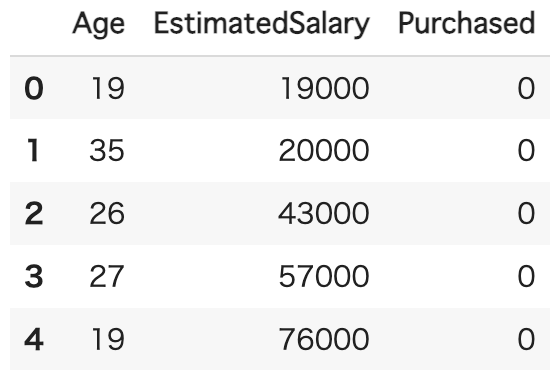
〔説明変数〕
・Age(年齢)、EstimatedSalary(お給与)
〔目的変数〕
・Purchased・・・1=購入する、0=購入しない
#説明変数と目的変数に分ける
x = df[["Age","EstimatedSalary"]]
y = df["Purchased"]
#データを学習用と検証用に分割
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(
x,y,train_size=0.7,random_state=0)
決定木分析をする際には、標準化を行わなくてよいことが非常に魅力的✨
そのため、データの準備はこれにて終了!
まずは、枝刈りなしで決定木分析
② モデルの設定と訓練
#決定木
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=10)
model.fit(x_train,y_train)
パラメータについて

max_depthが大事。
#決定木の可視化
from sklearn.tree import export_graphviz
import pydotplus
from io import StringIO
from IPython.display import Image
dot_data = StringIO()
feature_names = ["Age", "EstimatedSalary"]
export_graphviz(model, out_file=dot_data,
feature_names=feature_names,
class_names=["No", "Yes"],
filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())

※参照:特徴量の可視化(何が分岐条件に影響を与えているか)
#特徴量の可視化
feature_names = ["Age", "EstimatedSalary"]
n_features = len(feature_names)
plt.barh(range(n_features), model.feature_importances_, align="center")
plt.yticks(np.arange(n_features), feature_names)
plt.xlabel("Feature Importance")
plt.ylabel("Features")

③ モデルの精度を確認
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score,roc_auc_score
# 混同行列の出力
print("Confusion Matrix:")
print(confusion_matrix(y_true=y_test, y_pred=model.predict(x_test)))
# 性能指標の計算と表示
print("正解率(train) =", model.score(x_train, y_train))
print("正解率(test) =", model.score(x_test, y_test))
print("適合率 =", precision_score(y_true=y_test, y_pred=model.predict(x_test)))
print("再現率 =", recall_score(y_true=y_test, y_pred=model.predict(x_test)))
print("F1スコア =", f1_score(y_true=y_test, y_pred=model.predict(x_test)))
print("AUC =", roc_auc_score(y_true=y_test, y_score=model.predict_proba(x_test)[:, 1]))
▼ 回帰式の精度を確認
(1) 混同行列(confusion matrix)
(2) 正解率(accuracy)
(3) 適合率(precision)
(4) 再現率(recall)
(5) F1スコア(F1-score)
(6) AUC(曲線下面積)

今回の学習結果を見てみると、正解率(train)と正解率(test)の結果に、大きく差があることがわかる。これは、過学習の傾向であり、trainデータにフィットし過ぎてしまっていることが原因である。
max_depth=10で設定していたため、枝分かれ多すぎており、よい学習モデルが出来上がらなかったと言える。
実際、農家でも、枝分かれが多すぎると必要な養分が果物に行かないため、全体の味が落ちる傾向があるとのことで、多すぎる枝をカットするらしい。

これを剪定といい、決定木分析でも同じように剪定を行うことが大切で、これをすることでモデルの精度の向上が見込める。
次に、枝刈りありで決定木分析
① データ読み込みや前処理、分割

ここまでは同じ。
② モデルの設定と訓練
#決定木
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=4)
model.fit(x_train,y_train)
先ほどはmax_depth=10で設定していたのに対して、今回はmax_depth=4で設定。
#決定木の可視化
from sklearn.tree import export_graphviz
import pydotplus
from io import StringIO
from IPython.display import Image
dot_data = StringIO()
feature_names = ["Age", "EstimatedSalary"]
export_graphviz(model, out_file=dot_data,
feature_names=feature_names,
class_names=["No", "Yes"],
filled=True, rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())

※参照:特徴量の可視化(何が分岐条件に影響を与えているか)
#特徴量の可視化
feature_names = ["Age", "EstimatedSalary"]
n_features = len(feature_names)
plt.barh(range(n_features), model.feature_importances_, align="center")
plt.yticks(np.arange(n_features), feature_names)
plt.xlabel("Feature Importance")
plt.ylabel("Features")

③ モデルの精度を確認
from sklearn.metrics import confusion_matrix,precision_score,recall_score,f1_score,roc_auc_score
# 混同行列の出力
print("Confusion Matrix:")
print(confusion_matrix(y_true=y_test, y_pred=model.predict(x_test)))
# 性能指標の計算と表示
print("正解率(train) =", model.score(x_train, y_train))
print("正解率(test) =", model.score(x_test, y_test))
print("適合率 =", precision_score(y_true=y_test, y_pred=model.predict(x_test)))
print("再現率 =", recall_score(y_true=y_test, y_pred=model.predict(x_test)))
print("F1スコア =", f1_score(y_true=y_test, y_pred=model.predict(x_test)))
print("AUC =", roc_auc_score(y_true=y_test, y_score=model.predict_proba(x_test)[:, 1]))
▼ 回帰式の精度を確認
(1) 混同行列(confusion matrix)
(2) 正解率(accuracy)
(3) 適合率(precision)
(4) 再現率(recall)
(5) F1スコア(F1-score)
(6) AUC(曲線下面積)


今回の学習結果を見てみると、正解率(train)と正解率(test)の結果に、大きく差があることがわかる。これは、右図は、過学習の傾向であり、max_depthは適切に設定する必要がある。
<まとめ>
決定木の特徴して以下がわかった。
・メリット
学習結果の解釈がしやすい、図示のイメージがわかりやすい
データの前処理が少ない、標準化などが必要ない。
・デメリット
条件分岐が複雑になりすぎると、過学習になりやすい。
→ 剪定(枝刈り)で回避する
精度が非常に高いわけではない
→アンサンブル学習や、ランダムフォレストを使うと精度の向上が見込める。
以上。
続いては、 アンサンブル学習へGO!!!