はじめに
Kaggleの登竜門と言われる、タイタニック号の生存者予測を終えました。その経験を活かして、腕試し、かつ、全体の流れを知るべく、住宅価格予測(「House Prices - Advanced Regression Techniques」)にチャレンジしてみました!
【意気込み】
初めて1ヶ月目で荒削りな部分も多いですが、頑張ります💪
▼ゴール
アイオワ州エイムズの住宅のほぼすべての特徴を表す79種類のデータを用いて、各住宅の価格を予測するというコンペです。
▼最終的なアウトプット
1行目にヘッダ(Id,SalePrice)、2行目以降にIdと販売価格を載せます。
▼データ項目
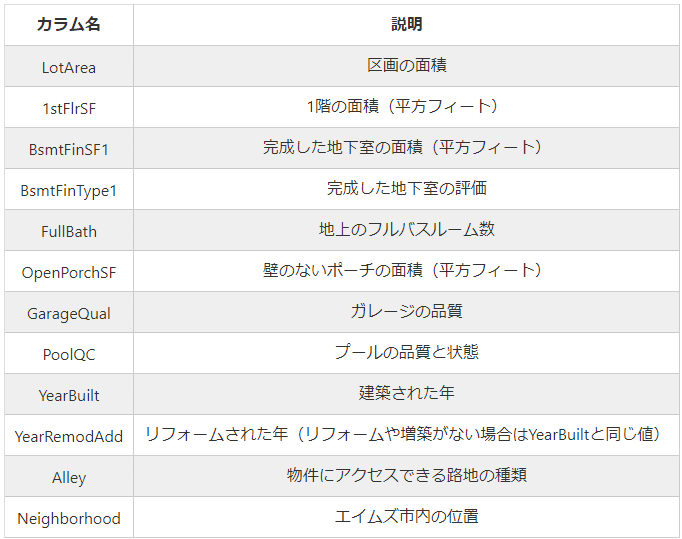
79種類ものデータがあるのですが、その一部を載せておきます。
※タイタニック号の後に、これだけの種類の問題を扱うのは無謀な気しかしない・・・。
それでは戦っていきます!!
大まかな流れ
① 初期段階
↓
② データの理解
↓
③ データの加工
↓
④ モデルの作成
↓
⑤ レポーティング・csvファイル化
▼ ① 初期段階
train = pd.read_csv("/content/train.csv")
test = pd.read_csv("/content/test.csv")
trainデータ、testデータの中身を見て差分に注目(目的変数が入っていないことに注目)
今回の場合は、「SalePrice」がtestデータに含まれていない。
▼ ② データの理解
train.describe()
test.describe()

LotFrontageが他のものより数が少ない=欠損値がある!
▼ ③ データの加工
〔どのカラムを選択するか〕
全部で79種類もあるから選択をどうしよう・・・。
方針として、「Sale Price」と関係のありそうなものは引っ張ってきたい。
・「Sale Price」と相関関係の高そうなものをピックアップ。
train.corr(numeric_only=True)

ChatGPT曰く、0.7くらいを超えると相関関係が高そうとのこと。
0.7を超えており、かつ、住宅価格にも関係のありそうな以下を選定しました!
・OverallQual:材料と仕上がりの品質
・LotFrontage:住宅が面する通りや道路の前面の長さ
・GrLivArea:居住面積
・MasVnrArea:外壁に使用されている石材やレンガのベニアの面積
・ただし、ピックアップしたもの同士が相関関係が高ければあまり意味がない(多重共線性だっけ??)可能性もあるため以下も実行しながら選んでみる。
先ほどの4つに相関関係がなかったかどうかを確認。
train[["OverallQual","LotFrontage","GrLivArea","MasVnrArea"]].corr()

高くはないはず・・・!このまま進めます!!
〔欠損値処理をどうするか〕
選んだ4つに欠損値がないかを確認していきます。
方針:
(欠損値処理)数値であれば「中央値」で埋めて、文字列であれば「最頻値」で埋める。
※文字列には中央値など存在しないため。
まずは欠損値の確認(trainデータ)
train[["OverallQual","LotFrontage","GrLivArea","MasVnrArea"]].isnull().sum()

※LotFrontage・MasVnrAreaはどちらも数字で構成されている。
次に、欠損値の確認(testデータ)
test[["OverallQual","LotFrontage","GrLivArea","MasVnrArea"]].isnull().sum()

どちらも方針に従って埋めていく〜〜!!
train["LotFrontage"] = train["LotFrontage"].fillna(train["LotFrontage"].mean())
train["MasVnrArea"] = train["MasVnrArea"].fillna(train["MasVnrArea"].mean())
test["LotFrontage"] = test["LotFrontage"].fillna(test["LotFrontage"].mean())
test["MasVnrArea"] = test["MasVnrArea"].fillna(test["MasVnrArea"].mean())
無事、どちらも欠損値は無くなっていました!!
〔文字列の有無〕
train.dtypes
test.dtypes
いずれもfloat・int型のみだったため今回は対応不要。
〔外れ値の有無 & 該当データの除外〕
箱ひげ図でそれぞれの項目に外れ値がないかを確認。
plt.boxplot(train[["LotFrontage"]])
plt.show()
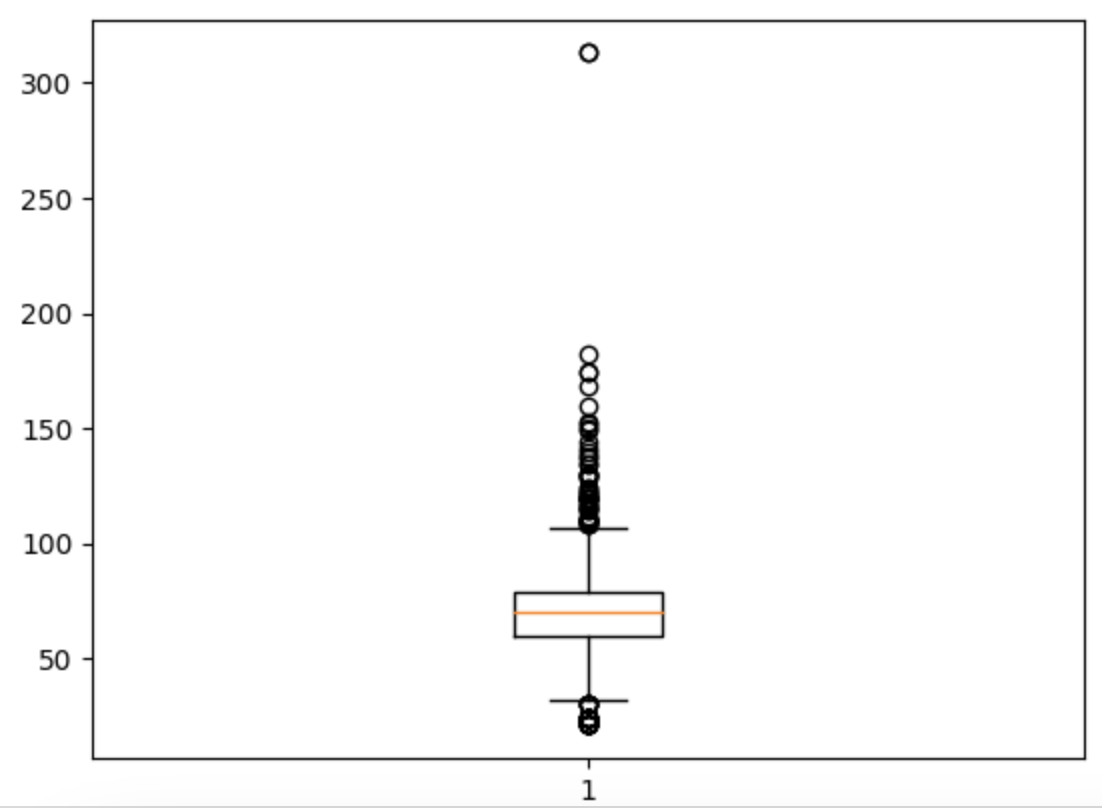
1つずつ確認して行ったところ、「LotFrontage」はあまりに気になったため300以上の列は削除。
train = train[train["LotFrontage"]<=300]
これにて一旦完了!!!
※この先に進む前に、使用データを見ていると「YearBuilt(建っている年数)」は取り入れたほうがいいだろうと思い、入れました。
▼ ④ モデルの作成
ntrain = train[["Id","OverallQual","LotFrontage","GrLivArea","YearBuilt","SalePrice"]]
ntest = test[["Id","OverallQual","LotFrontage","GrLivArea","YearBuilt"]]
使うデータを上記にまとめました。
あとはいつもの流れ、trainデータとtestデータを分けていきます!
from sklearn.tree import DecisionTreeRegressor
X = ntrain[['OverallQual','LotFrontage','GrLivArea','YearBuilt']]
y = ntrain["SalePrice"]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
〔備考〕タイタニックの時と違う点
・DecisionTreeRegressorは回帰
→予測する時に使用するモデル
DecisionTreeClassifierは分類(タイタニックはこっち!!)
→A or Bに分類する時に使用するモデル
▼ ⑤ モデルの評価
model = DecisionTreeRegressor(random_state=0)
model.fit(X_train,y_train)
X_test = ntest[['OverallQual',
'LotFrontage',
'GrLivArea',
'YearBuilt']]
pred_y_test = model.predict(X_test)
pred_y_test
▼ ⑥ レポーティング・csvファイル化
submission = pd.DataFrame({"Id": ntest["Id"],
"SalePrice": pred_y_test})
submission.to_csv("submission.csv", index=False)
▼ 提出 & 結果

0.24834!!(この数字が何を表しているのかわからん・・・)
上位、84.9%😂
センスが垣間見えない😭😭😭
最後に
アウトプットとして挑戦してみましたが、正直まだ何をやっているのかイメージが掴めないことが多いです・・・(特に後半のモデル作成以降)。
それから、データの種類が多く、扱う基準もだいぶテキトーに決めてしまっていますっ💦
ただ、実践形式で取り組むことはとても楽しかったので、雑魚雑魚ですが、少しずつ成長できたらと思います!!!