目的
AWS Glue を触る中で躓いた点をまとめて整理する。
Glue ジョブスクリプト作成 Tips
ジョブプロファイルは有効にする
データの抽出・変換処理のパフォーマンス向上のために、ジョブプロファイルは有効化を選択しておく。
メトリクスは CloudWatch から参照できる。
リソースが有効活用されているかを確認しながら、コストも含めてジョブの設定・スクリプトを最適化していくことができる。
Glue の自動生成ジョブは処理が重い
Glue のジョブ作成時に、 「このジョブ実行」の選択肢で 「AWS Glue が生成する提案されたスクリプト」を選択すると、 指定した設定をもとに一連の処理を実行するスクリプトが自動生成される。
しかし、クローラーで作成したテーブルを使ってジョブを作るとテーブルの全データを temporary ディレクトリにコピーするようで、大量データを扱う際には効率が悪い。
なので、例えば s3 から csv データを取得する場合には、可能であれば pySpark の read 処理をそのまま使う方が早く済む。
df = spark.read.option("delimiter",",").csv("s3://mydata/xxx",header=True)
Glue のジョブパラメータを利用するには「--」をつける
Glue のジョブを実行する際にジョブのパラメータを指定できる。
このとき、 GUI で操作している場合でも「--」をつけてジョブパラメータを入力する必要がある。
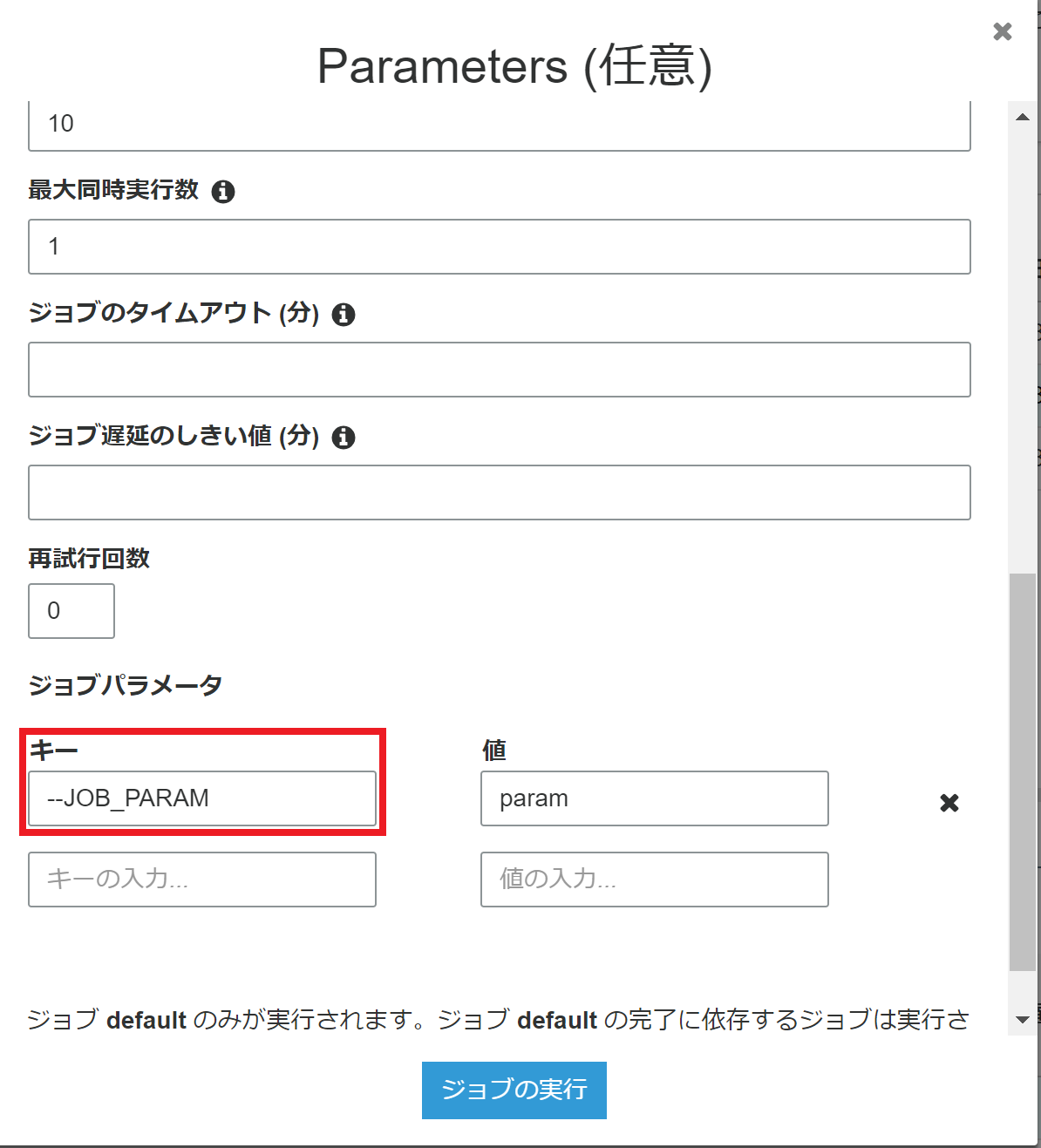
この場合、ジョブスクリプト上では下記で入力パラメータを取得できる。
args = getResolvedOptions(sys.argv, ['JOB_PARAM'])
param = args['JOB_PARAM']
「--」をプレフィックスに入れずにパラメータを設定するとどうなるかというと、無視される。
無視されるので、ジョブスクリプト上でパラメータを取り出す処理で指定したパラメータを取得できずにエラーとなる。
コマンドラインからならともかく、画面から入力する場合も「--」を入力しなければならないのはちょっと違和感あるものの、このような仕様らしい。
ジョブパラメータに現在時刻を設定する
Glue の内部での実行環境は linux 上のようなので、ジョブパラメータの値に`date "+%Y-%m-%d`と入力すればパラメータ自体に現在時刻を設定することができる。
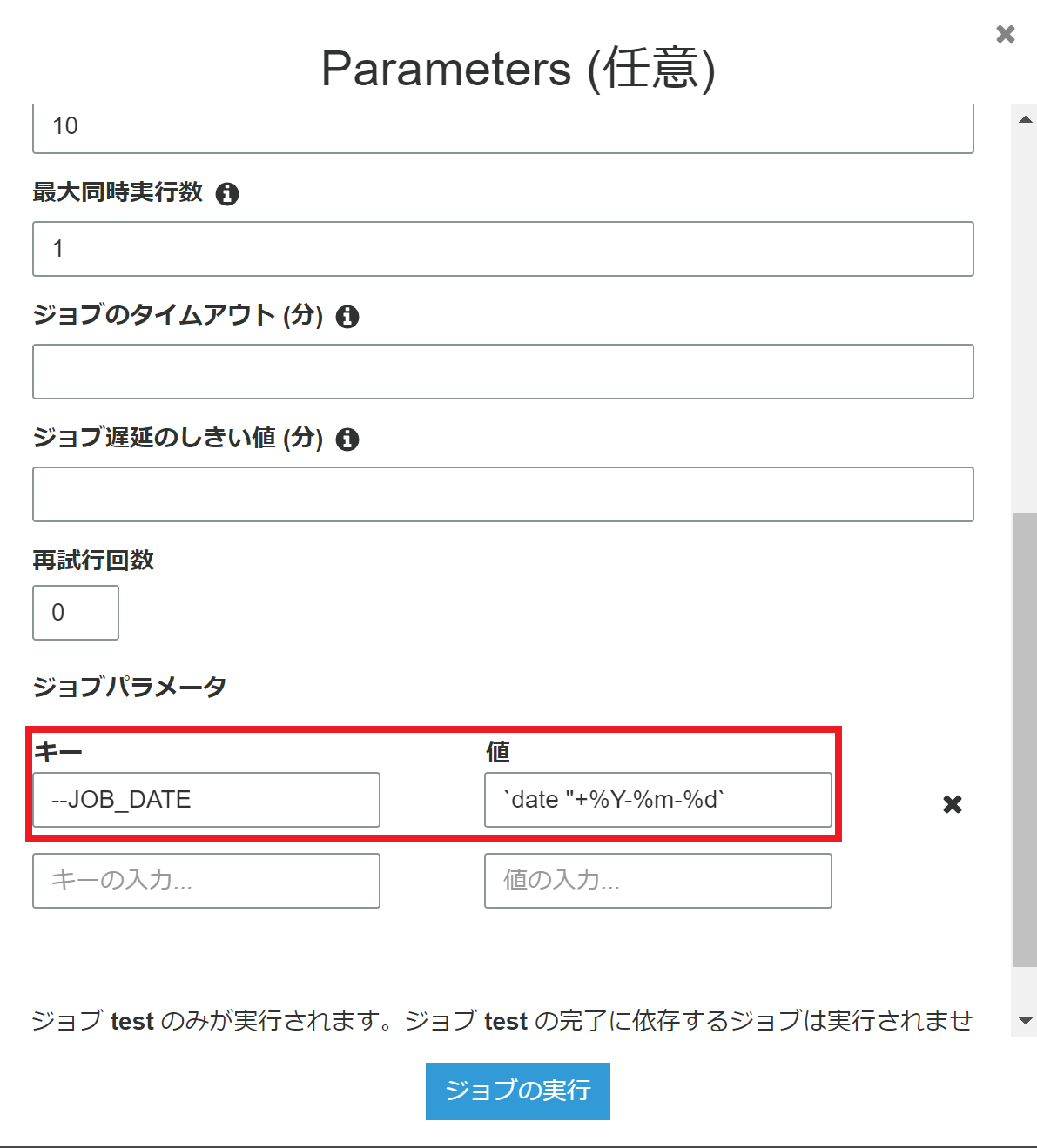
とはいえ、 ジョブスクリプト内で現在時刻を取得する処理を実装すればほとんどのケースで困らないはず。
この方法で現在時刻を取得するのは Glue 内部の実行環境に依存してしまうので、余程のことがない限りやらない方が良い。
Glue ジョブ設定 Tips
DPU を変えると何が変わるのか?
Spark の最大 executer 数が変化する。
具体的には
spark.dynamicAllocation.maxExecutors
のパラメータが変更される。
ただし、 DPU に指定した数字がそのまま最大 executer 数になるわけではない模様。
ほかにも変化があるかもしれないが、 表面的には DPU が増えると executer 数が増えて処理速度のアップが処理内容によっては期待できる。
Glue の Spark オプション
Spark オプションでメモリは 5GB、コア数は4コアで固定されている様子。
--conf spark.executor.memory=5g
--conf spark.executor.cores=4
Glue を使う上で Spark の設定変更はできないので、メモリ不足などでジョブが失敗する場合はスクリプト側を変更するしかなさそう。
Glue ジョブ入出力データ Tips
出力ファイル名は指定できない
Glue のジョブスクリプトで結果出力のファイル名を指定する機能は特にない模様。
Spark をベースにしているので当然といえば当然か。
出力ファイルを1つにまとめる
Spark と同様、 partition を1に指定すれば出力ファイルは1つになる。
しかし、当たり前のことだが partition を分けないことによるパフォーマンスの悪化は避けられない。
また、出力結果を Redshift などで取り込むことを考えると、ファイルが複数に分散されているメリットのほうが大きい。
なので、余程の理由がない限り出力ファイルを1つにまとめない方がよさそう。
さいごに
何度か Glue を触ってみて、少しづつ便利さと不便さがわかり始めてきた。
今のところ一番残念に思っているのは python は version 2.7 しかサポートしていないところ。
いつか version 3.6 もサポートされるんだろうか。。。