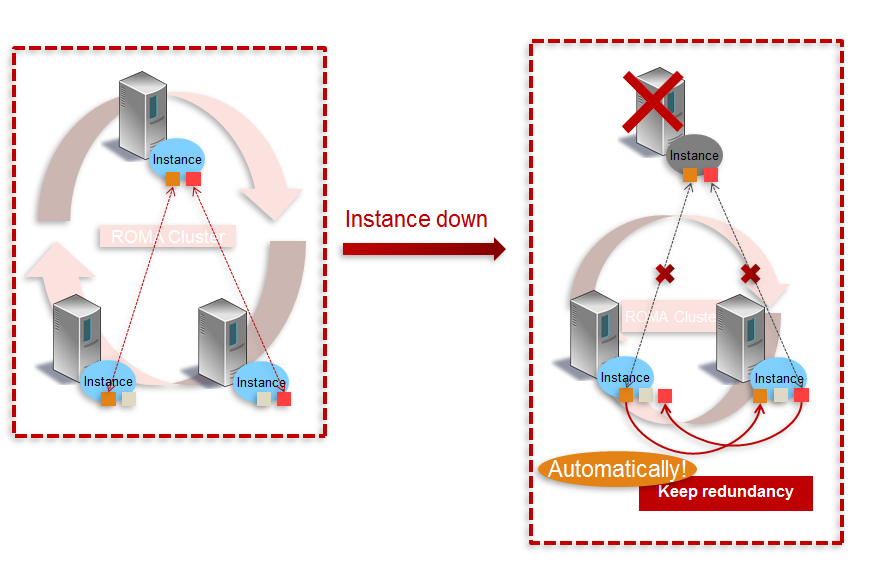
サーバエラーなどでinstanceが落ちて冗長度が低下してしまった時の対処方法です
条件
"localhost_10001", "localhost_10002", "localhost_10003"の3インスタンスでクラスターを組んでいた時、"localhost_10001"が落ちてしまった時を例にして説明します
冗長度復帰手順(recover)
1. ステータス確認
まずはtelnetで生きているインスタンスへアクセスし、現在のstatusを確認します
$ telnet telnet 10002
> stat node
.
routing.nodes.length 2 #=> 3から2へ
routing.nodes ["localhost_10002", "localhost_10003"] #=> localhost_10001が落ちている
.
routing.short_vnodes 133 # 冗長度の低下したvnodeの数
routing.lost_vnodes 0 # 冗長度が0になったvnodeの数
.
.
- localhost_10001が落ちたため、このinstanceが担当していたvnodeの冗長度が落ちています
- デフォルトで冗長度2なので1instance落ちてもデータの読み書きは問題なく行えます
- ただし該当vnodeは冗長度1の状態
2. 冗長度回復
コマンド
> recover
- 生きているインスタンスの中で、冗長が落ちているvnodeの担当を再アサイン、及びデータのコピーを行うことで冗長度の回復を行う
- どれか1インスタンスで実行すればOKです
実行
> recover # recover実行
> stat run_recover
stats.run_recover true # recoverが実行中であることを示します
> stat short
routing.short_vnodes 127 # 段々減っていきます
- recoverプロセスが進むにつれて、
routing.short_vnodesの数が減っていきます
3. 終了確認
> stat run_recover
stats.run_recover false # recoverが終了するとfalseに戻ります
> stat short
routing.short_vnodes 0 # 冗長度の低下したvnodeが0になっています
- recoverプロセスにかかる時間は、データ量やサーバスペックによって異なります
AUTO RECOVER機能
上記では手動でrecoverを実行していましたが、冗長度が落ちた際に自動でrecoverを実行するように設定することも可能です
コマンド
> set_auto_recover [ 'true' | 'false' ] <sec>
- trueで起動、falseで停止します
- <sec>は、冗長度の低下を検知してから何秒後にrecoverを実行するかを指定します
- 猶予期間のようなもので、recoverではなく他の対処法をとりたくなった場合には、この時間内に
set_auto_recover falseを実行することでrecoverの実行をキャンセルすることが可能です
- 猶予期間のようなもので、recoverではなく他の対処法をとりたくなった場合には、この時間内に
参照URL
ROMA Recovery redundancy: http://roma-kvs.org/learn/recovery_redundancy.html
ROMA Commands Page: http://roma-kvs.org/commands.html