時系列分析とは
時間の経過とともに観測されたデータを時系列データといいます。
- 毎日の最高気温
- 株価
- 毎年の売上高
などがあります。
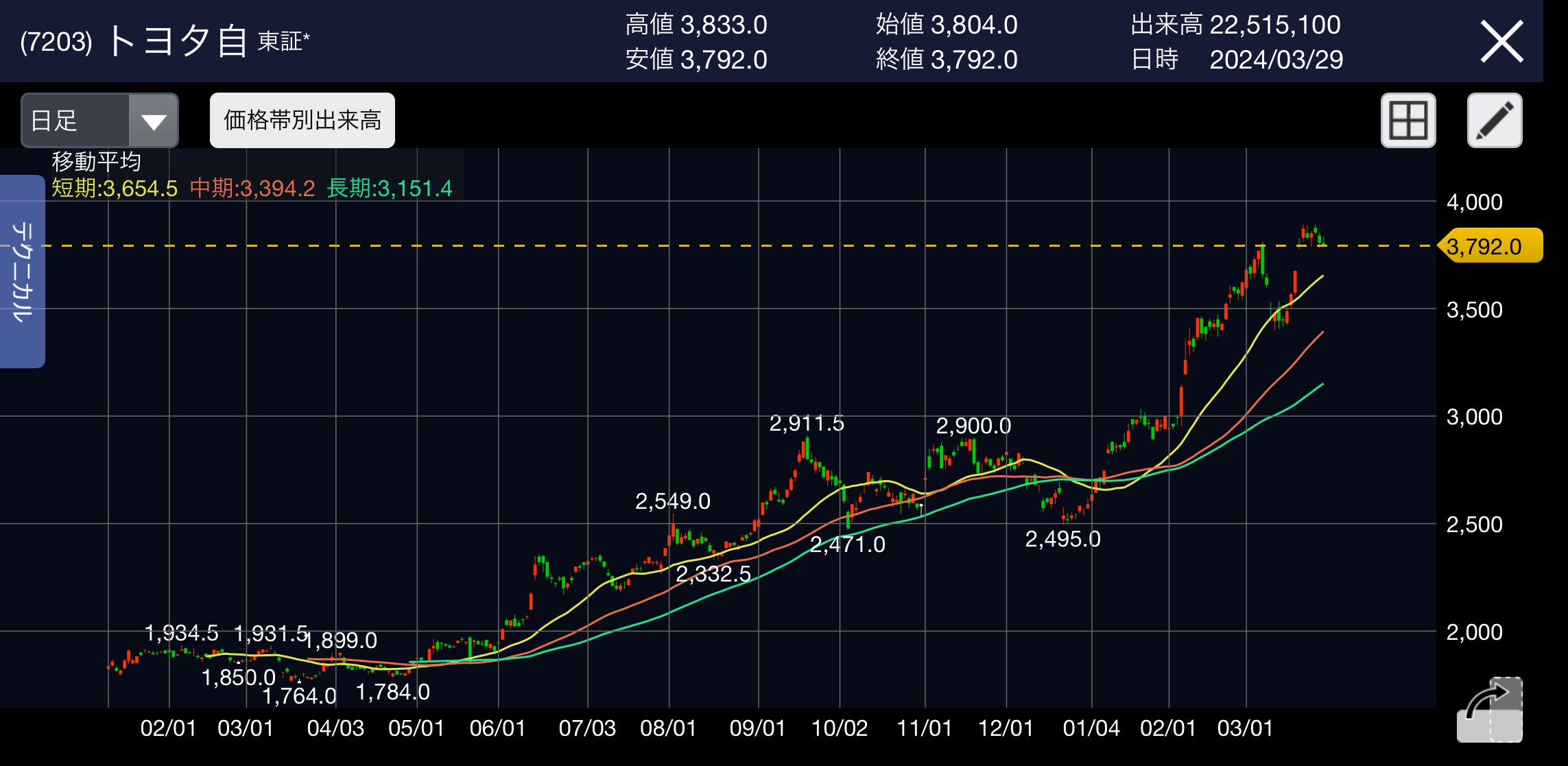
(記事の最後では、トヨタ自動車の株価を実際に予測しています。)
時系列データの特徴量
時系列データ$Y_{1},Y_{2},...,Y_{T}$は、一つ前の時点と似た値を取るはずです。すなわち、$Y_{t}$と$Y_{t-1}$の相関は正の値になります。ここで、
Cov[Y_{t},Y_{t-h}]=\gamma_{t,h}
\rho[Y_{t},Y_{t-h}] = \frac{Cov[Y_{t},Y_{t-h}]}{\sqrt{V[Y_{t}]V[Y_{t-h}]}}=\rho_{t,h}
はそれぞれ、時点$t$における$h$次の自己共分散、時点$t$における$h$次の自己相関係数といいます。また、時間差$h$はラグとよばれます。
本記事は「統計学実践ワークブック」第27章時系列分析と、こちらのYoutube動画を一部参考に作成しています。
定常性
時系列データの平均・自己共分散(自己相関係数)が観測時点$t$に依存しない場合、共分散定常過程と呼ばれます。
時系列分析に限らず、定常性は"時刻$t$によらない状態"を指します。
時系列分析の種類
時系列分析には様々な種類があります。
| 種類 | 具体的な分析手法 |
|---|---|
| 古典的時系列分析手法 |
AR・MA・ARMA・ARIMA・SARIMA VAR・VARIMA GARCH |
| 状態空間モデル | 線形ガウス状態空間 隠れマルコフモデル ベイズ構造時系列モデル |
| 深層学習ベース |
LSTM Attention |
下に行くほど複雑なモデルになります。本記事では太文字の部分を紹介しています。
時系列データの要素
時系列データは5つの要素に分類されます。
- 長期変動(トレンド) ・・・長期的な変動傾向 ex)人口増加、経済成長
- 循環変動 ・・・一定の周期で出現する変動 ex)平日と週末
- 季節変動 ・・・季節ごとに繰り返される変動 ex)春-夏-秋-冬
- 周期変動 ・・・季節変動より長い周期的な変動 ex)好景気-不景気
- 不規則変動 ・・・ランダムな変動 ex)自然災害
古典的時系列分析手法
自己回帰過程(AR過程)-AutoRegressive Process
時系列データを表現する代表的なモデルの一つです。
最もシンプルなものは、1次の自己回帰過程(AR(1)過程)であり、
Y_{t}=\phi_{1} Y_{t-1} +U_{t} (T=1,2,...,T)
で表現されます。ここで、${U_{t}}$は互いに独立で平均0、分散1の同一分布に従うホワイトノイズといいます。
$Y_{t}$は「直前の値$Y_{t-1}$」と「誤差$U_{t}$」によって決まるという意味
\begin{align}
Y_{t}&=\phi_{1} Y_{t-1} +U_{t} \\
&=\phi_{1}(\phi_{1} Y_{t-2} +U_{t-1})+U_{t} \\
&=\phi_{1}^2Y_{t-2}+\phi_{1}U_{t-1}+U_{t} \\
\\
&=\phi_{1}^tY_{0}+\sum_{j=1}^t \phi_{1}^{t-j}U_{j}
\end{align}
より、$Y_{0}$から$Y_{t}$への影響は$\phi_{1}^t$であることがわかります。
したがって、
- $|\phi_{1}|<1$のとき、過去から現在への影響は時間差が開くほど弱くなる
- $|\phi_{1}|>1$のとき、過去から現在への影響は時間差が開くほど強くなる
のです。
期待値
E[Y_{t}]=c+\phi_1 E[Y_{t-1}]+0
$E[Y_{t}]=E[Y_{t-1}]=\mu$より、
\mu=c/(1-\phi_1)
共分散
\gamma_0 =\dfrac{\sigma^2}{1-\phi_1^2}
自己共分散
\gamma_h =\phi_1^h \dfrac{\sigma^2}{1-\phi_1^2}
自己相関係数
自己相関係数$\rho_h$は、$\gamma_h=\phi_1\gamma_{h-1}=\phi_1^2\gamma_{h-2}=・・・=\phi_1^h\gamma_0$より、
\rho_h = \phi_1^h
先ほどまでは$Y_{t}$が1期前の$Y_{t-1}$のみで説明されるAR(1)過程を考えていましたが、それを拡張し、
Y_{t} = c+\phi_{1}Y_{t-1}+\phi_{2}Y_{t-2}+・・・+\phi_{p}Y_{t-p}+U_{t}
というAR(p)過程を考えることもできます。
MA過程 -Moving Average Process
$Y_{t}$が${U_{t}}$の加重和で表されているものを移動平均過程(moving average process)といいます。1次の移動平均過程(MA(1)過程)は、
Y_{t}=\mu+U_{t}+\theta_{1}U_{t-1}
と表現されます。${U_{t}}$はホワイトノイズです。
期待値
E[Y_{t}]=\mu
分散・自己共分散
\gamma_h =\left\{ \begin{array}{1}(1+\theta_1^2)\sigma^2 & (h=0) \\ \theta_1 \sigma^2 & (h=1) \\0 & (h>1) \end{array} \right.
期待値、分散・自己共分散に$t$が含まれていないため、共分散定常であることがわかります。
ARMA過程(自己回帰移動平均過程)
AR過程とMA過程を組み合わせたものがARMA過程(自己回帰移動平均過程)です。
Y_{t}=c+\phi_1Y_{t-1}+・・・+\phi_{p}Y_{t-p}+U_{t}+\theta_1U_{t-1}+・・・+\theta_qU_{t-q}
で表現され、ARMA(p,q)過程と呼びます。
$c+\phi_1Y_{t-1}+・・・+\phi_{p}Y_{t-p}+U_{t}$はAR過程、$c+U_{t}+\theta_1U_{t-1}+・・・+\theta_qU_{t-q}$はMA過程になっています。
ARIMA過程(自己回帰和分移動平均過程)
AutoRegressive Integrated Moving Average Processの略。
${Y_{t}}$ではなく、階差$\Delta Y_{t} =Y_{t}-Y_{t-1}$が共分散定常になっているものです。
\Delta Y_{t}=\phi_1\Delta Y_{t-1}+・・・+\phi_{p}\Delta Y_{t-p}+U_{t}+\theta_1U_{t-1}+・・・+\theta_qU_{t-q}
階差をとる必要があるかは、単位根検定によって判断します。
SARIMA過程
Seasonal AutoRegressive Integrated Moving Average Processの略。
ARIMA過程に「季節変動」を加えたものです。
単位根検定
データによって、ARMA過程とARIMA過程のどちらを用いた方がよいかは異なります。階差をとる必要があるかはデータをプロットしただけではわかりにくいため、単位根検定(unit root test)と呼ばれる検定を行います。
階差をとる必要があるのは$\phi_{1}=1$の場合で、単位根検定では$\phi_{1}=1$を帰無仮説、$|\phi_{1}|<1$を対立仮説として検定を行います。
特に、$\phi_{1}=1$の場合の$t$検定はディッキー・フラー検定と呼ばれ、実証研究で広く用いられています。
単位根を持つ時系列データとは、長期的なトレンドが存在することを示します。
コレログラム
ARMA過程やARIMA過程では、次数を決定する必要があります。AR過程とMA過程の自己相関係数は、
AR過程
\rho_h = \phi_1^h
MA過程
\rho_h= \frac{\gamma_h}{\gamma_0} =\left\{ \begin{array}{1} \dfrac{\theta_1}{1+\theta_1^2} & (h=1) \\0 & (h>1) \end{array} \right.
です。これが真の自己相関係数(理論値)になります。
なお、実際のデータから求められた標本自己相関係数の図をコレログラムといい、理論値と比較して次数選択を行います。
*随時更新する予定です。
機械学習による時系列分析
LSTMによる株価予測
LSTM(Long Short-Term Memory)は文書生成や株価予測によく用いられる機械学習の手法です。
こちらの記事が非常に分かりやすくまとめられていたので参考にさせていただきました。
実際に、pythonでLSTMモデルを用いてトヨタ株の予測をしてみようと思います。
import keras
import pandas as pd
from datetime import datetime
import numpy as np
from matplotlib import style
import matplotlib.pyplot as plt
import yfinance as yf
import warnings
warnings.filterwarnings('ignore')
# yahoo finance からトヨタ自動車【7203】の2018年1月1日以来の時列データセットを抽出し、データの形式を確認
df = yf.download("7203.T",start='2018-01-01',end = datetime.now(),interval="1d")
df.head()
# datasetをplotして可視化
plt.figure(figsize=(16,6))
plt.title('Close Price History')
plt.plot(df['Close'])
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price of Toyota', fontsize=18)
plt.show()
# Closeコラムのみ抽出
data = df.filter(["Close"])
dataset = data.values
# データの正規化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
scaled_data
# データを訓練データと検証データに分割し、7割が訓練用に設定
training_data_len = int(np.ceil(len(dataset) * 0.7))
training_data_len
train_data = scaled_data[0: int(training_data_len), :]
train_data.shape
機械学習ではお馴染みの所得したデータを訓練データとテストデータに分けます。
#訓練データの取得
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i,0])
y_train.append(train_data[i,0])
# 訓練データのreshape
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train,(x_train.shape[0], x_train.shape[1], 1))
x_train.shape
# kerasから必要なライブラリを導入
from keras.models import Sequential
from keras.layers import Dense, LSTM
#LSTMモデル構築
model = Sequential()
model.add(LSTM(128,return_sequences = True, input_shape=(x_train.shape[1], 1)))
model.add(LSTM(64, return_sequences = False))
model.add(Dense(25))
model.add(Dense(1))
model.compile(optimizer='adam',loss='mean_squared_error')
#訓練用モデル構築
model.fit(x_train, y_train, batch_size = 1, epochs =1)
# 検証用データを取得とデータ変換
test_data = scaled_data[training_data_len - 60: , :]
x_test = []
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i,0])
y_test = dataset[training_data_len:, :]
x_test = np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1],1))
# 予測値の算出
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# RMSEを利用して予測精度を確認
from sklearn.metrics import mean_squared_error
test_score = np.sqrt(mean_squared_error(y_test,predictions))
print('Test Score: %.2f RMSE' % (test_score))
train = data[: training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize = (16,6))
plt.title('LSTM Model')
plt.xlabel('Date', fontsize =18)
plt.ylabel('Close Price of Toyota', fontsize =18)
plt.plot(train['Close'])
plt.plot(valid[['Close','Predictions']])
plt.legend(['Train','Real','Prediction'], loc='lower right')
plt.show()
LSTMをimportし、LSTMモデルを構築します。実際の予測結果はこんな感じです。

かなり精度は高いですが、実用できるかはわかりません。
時系列分析の注意点
将来を完全に予測できるわけではない
自然科学分野と異なり、人間の営みが絡む社会科学分野では、理論通りに行動しない人間の行動心理や自然災害などの予期せぬ事態によって、予測通りの結果が得られない場合が数多くあります。現実社会への実用には注意が必要です。
最適なモデル選択
様々な過程がありましたが、実際にどのモデルを選択するかを考える際は、5つの要素を考えると良いです。
例えば、アイスの販売数予測を行いたい場合、間違いなく「季節変動」は考慮する必要があるでしょう。その際、適切なモデルはSARIMA過程になります。
では、ARMA過程とARIMA過程にはどのような違いがあるか比較してみましょう。
ARMA過程の場合のシミュレーション
import math
import random
import numpy as np
import matplotlib.pyplot as plt
sigma=5
y=[0]
u=[0]
t=[0]
for i in range(100):
t.append(i+1)
u.append(random.gauss(0,sigma**2))
y.append(y[i]+u[i+1]+u[i])
#散布図にプロット
plt.plot(t,y)
plt.title('ARIMA Process Yt')
plt.show()
実行結果はこんな感じです。

|

|
ARIMA過程の場合のシミュレーション
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima_process import ArmaProcess
# ARIMA過程のパラメータを設定
# AR次数: p、MA次数: q
p = 1
q = 1
# AR係数とMA係数を指定
ar_coefs = np.array([0.5, -0.25])
ma_coefs = np.array([0.3])
# 分散(ここでは1.0に設定)
sigma = 1.0
# ARIMA過程を生成
arima_process = ArmaProcess(ar_coefs, ma_coefs)
simulated_data = arima_process.generate_sample(nsample=100, scale=sigma)
# 生成された時系列データを可視化
plt.plot(simulated_data)
plt.title('Simulated ARIMA Process')
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()
実行結果はこんな感じです。

|

|
先ほどの場合と比べて、"ギザギザした変動"になっていることが確認できます。こちらの場合は、階差$\Delta Y_{t}$が共分散定常過程であることから、1期前の値には影響されないのです。
このように、ARMA過程では一度増加するとしばらく増加傾向のある山型の変動が見られるのに対し、ARIMA過程ではランダムなギザギザした変動が見られるという違いがあります。現実のモデルでは、ARIMA過程の方がやや実用的ともいわれます。(株価・売上データ等はARIMAモデルに近い)
その他
未知のクラスやタスクに対して、訓練データを用いずに他の情報から予測するZero-shot Learningと呼ばれる手法も進んできています。
2024年データ解析コンペティションでは、日経POS情報からの飲料業界のデータからZero-shot Learningを用いて期間限定の新商品の需要予測をするというものが最優秀賞を受賞しています。