概要
troccoの生みの親で、現プロダクト責任者をしている @hiro_koba_jp です。
troccoアドベントカレンダー2022の1記事目書いていきます!(みんなも参加してね)
データ分析やデータエンジニアリングにおいてETL(Extract Transform Load)という言葉を耳にしたことがある方は多いのではないでしょうか?
一方、「ETLではなくELT(音楽グループではない)が主流になりつつある」といったような論調も増えてきました。
この記事では、ETLとELTの違いや、なぜELTにシフトしつつあるのか、この先どうなるのか(予想)について、私なりの見解を書いてみようと思います。
一昔前まではETLパターンが多かった
Redshiftが登場した2013年頃、人々はデータレイク層はS3上で構築し、データウェアハウス層〜データマート層はRedshift上に組む人が多かったように思います。
なぜなら当時のRedshiftはノード数 x 稼働時間課金で、ノード内のストレージにデータをロードして使う形だったため、大量のデータをストレージにロードしてしまうとコストが高くなってしまうのです。
したがって最も容量の多いデータレイク層はRedshift上にロードせずS3上にコールドデータとして持たせ、そこからRedshiftに必要なデータのみロードする事が多かったです。
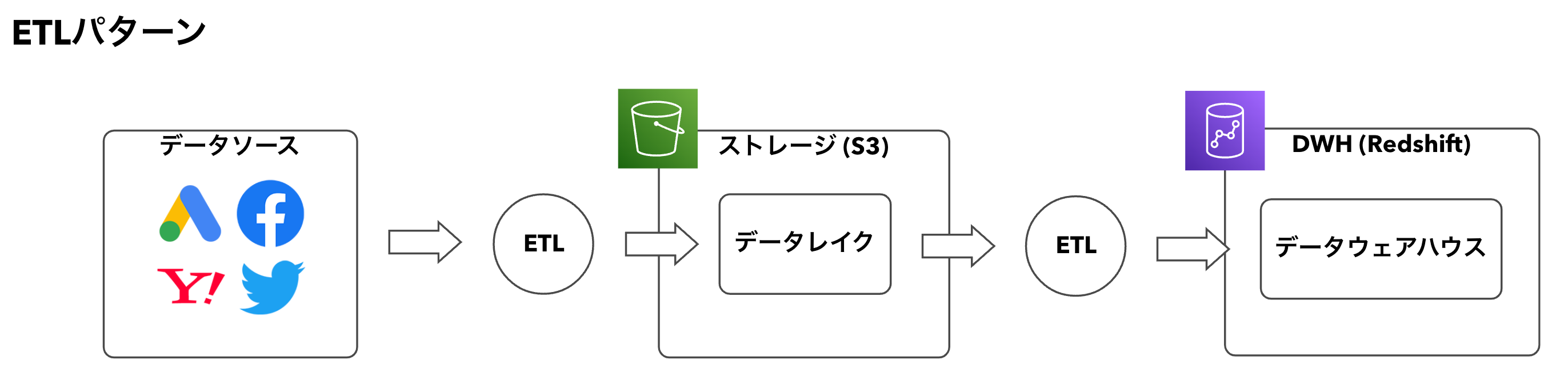
例えば以下の図のように、ETLパターンで事前に加工・変換してからDWHにロードする事が主流でした。
(このETLはSparkなどの分散処理フレームワーク上で、PythonやJavaなどのプログラミング言語を用いて実装されます)
DWHにおける「コンピュートとストレージの分離」
時代は流れ、BigQueryやAthenaのようなクエリ処理に特化したサービスが台頭し始めます。
先述のRedshiftのように、コンピュートリソースとストレージが同一サーバ内に同居するようなアーキテクチャだと、
- CPUはあまり使っていないけど、ストレージが一杯だからノードを増やす必要がある
- ストレージは全然使っていないけど、CPUの処理能力が足りないからノードを増やす必要がある
といったように、CPUかストレージのどちらかがボトルネックになった際にスケールアウト(=課金)する必要がありました。
一方でBigQueryやAthenaは根本的なアーキテクチャが大きく異なります。
ストレージはブラックボックス化されており、クエリ処理に特化しているのが特徴です。(厳密にはストレージ容量に対する課金はありますが、大幅にコスパが良くなりました)
しかもサーバ台数のような概念はなく、クエリが処理対象としたデータ容量での課金となります。
(CPUリソースなどは内部的に自動で割り当ててくれるため、CPU処理能力の最適化もあまり考えなくてよくなりました)
これらはデータ界隈での大きなブレークスルーポイントでした。
データレイク層が「DWH」システム上に構築されるように
コンピュートとストレージの分離による恩恵が以下です。
- データ容量による課金が最小化された
- 処理速度も大幅に向上した
これにより、
Sparkなどの分散処理フレームワーク上でPythonやJavaなどのプログラミング言語を用いて実装するETL
↓
DWH上にとりあえずロードして、SQLで変換しちゃおうぜ
という変化が起こりました。
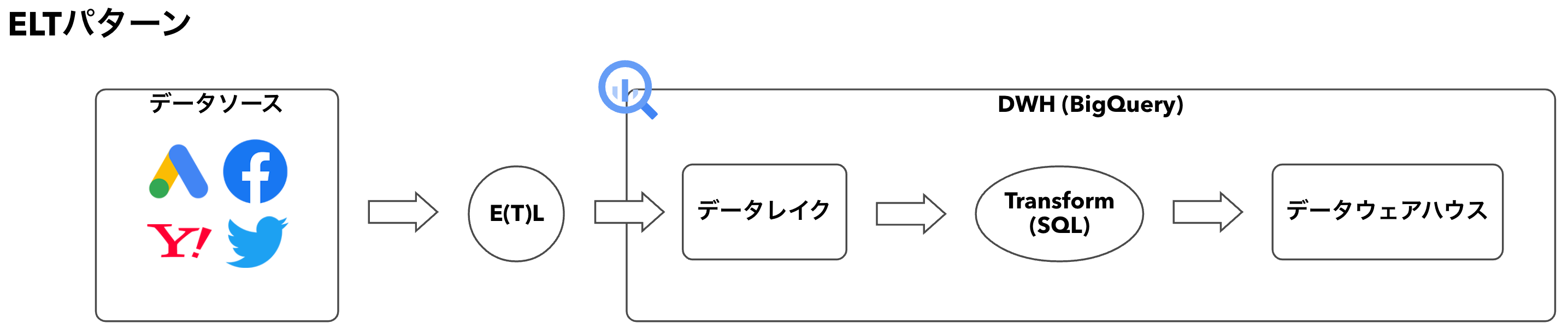
これがETL→ELTの転換ポイントではないかと考えます。
また、一般的な事業会社においての「データ変換・加工」のニーズはそれほど複雑ではなく、SQLのようなシンプルな処理言語でも十分処理可能である、という事実も影響しているように思えます。
ETLとELTの違い
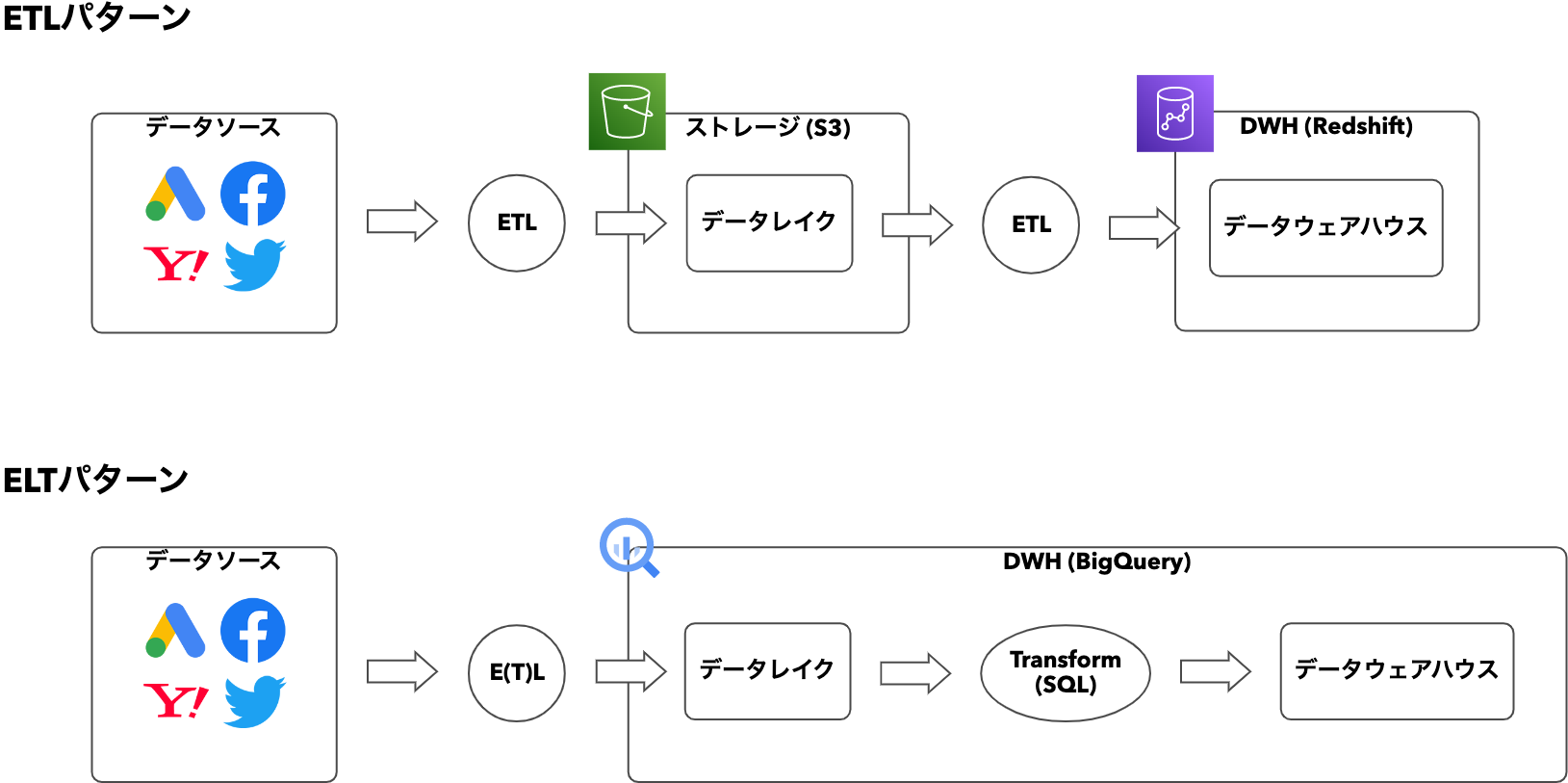
改めてETL/ELT2つの処理パターンを比べてみましょう。
ETLパターンで処理する場合、データソース→ストレージと、ストレージ→DWHの2種類のETLが必要になります。
また、ETLでデータ変換を行う場合、多くの場合はSparkなどの分散処理フレームワーク上でJavaやPythonなどのプログラミング言語で処理を実装する必要があります。
そのためETLを実装できるのはごく一部のデータエンジニアのみでした。
一方のELTパターンでは、E(T)Lはそこまで複雑な処理を要求されない&OSSやSaaSも多くあるため、誰でもデータレイク層を構築することが出来ます。
さらに、データ変換はSQLで実装可能なため、アナリストやSQLが分かるマーケターやマネージャーの方でも対応できるようになります。
ELTのほうが民主化されている状態と言えるでしょう。
ELTは銀の弾丸なのか
最後に、ELTの弱点と未来について語ります。
ELTの最大の弱点は、SQLで処理を記述「しなければならない」ことだと思います。
SQLは何十年も前から存在する言語で、複雑な処理を記述することが苦手です。
複雑な処理を書かなければいけない時は、プログラミング言語の自由度やテスト機構などが羨ましくなることが多々あります。
しかし、この弱点も近年対策がされつつあります。
最近多くのDWHでは、プログラミング言語が使えるようなアップデートが盛んに行われています。
Snowpark(Snowflake)やBigQueryのストアドプロシージャでSparkを使えるアップデートなどがソレです。
また、dbtなどの台頭により、SQL自体の弱点も補われつつあります。
これらはELTパターンの普及に拍車をかけ、それによってデータ変換やデータ処理自体をどんどん民主化してくれることでしょう。
まとめ
いかがでしたでしょうか。今回はETLとELTの違いや、歴史的変遷などを語ってみるポエム記事を書いてみました。
データ界隈は日々の進化が激しく、とても刺激的ですね。
それでは皆様、Happy Data Enginnering!