はじめに:
Nishika株式会社が運営、特許庁がホストをつとめる、AI×商標:イメージサーチコンペティション(類似商標画像の検出)に参加しました。
本記事では、どのような手法をとったか備忘録も兼ねて記載したいと思います。
コンペにも深層学習にもmarkdown記法にも慣れていないため粗があると思います。
また、初心者なので内容に誤りのある可能性があることをお気をつけください。
結果:

約57%の精度で類似商標を提示することのできるモデルを作成することができました。
8位のmotono0223さんと同スコアで9位solo silver…あと1つでも合っていればsolo goldだったのに、惜しい!
概要 :
本コンペは、増え続ける商標出願に対して商標審査官の業務負担を減らすために、商標類似判定アルゴリズムの開発を目的としたものです。
参加者には、約80万枚の画像データと、画像データ中の類似画像同士のファイル名が記載されたcsvファイル(学習用)などが配布されています。
(データセットの画像はコンペ以外での使用が禁じられているため、フリー素材を使ったデータセットの説明画像を以下に掲載します。)
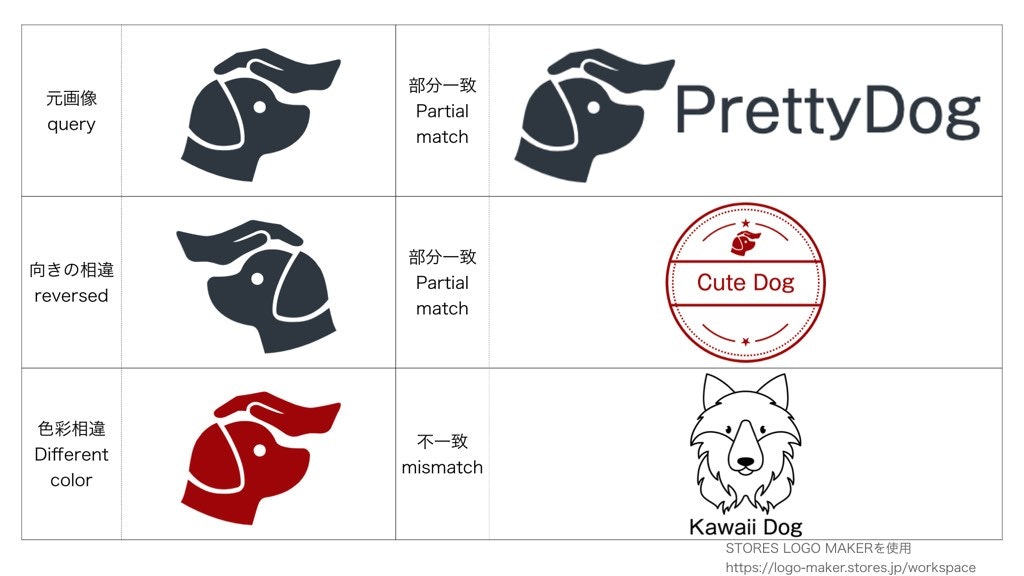
例えば、上記の画像の「元画像と部分一致」「色彩相違と部分一致」などが類似となり、それ以外の画像同士(例えば犬のロゴと車のロゴ)のペアは不一致とみなされます。
前処理 :
コンペで配布されているデータをそのまま用いることは少なく、適切な分析や学習を行うためにデータの加工を行います。
本コンペで提供されているデータは大きく分けて、類似画像同士のファイル名が記載されたテーブルデータ(学習用)と、画像データの2つです。
-
テーブルデータ :
-
類似しているが記載が分かれているペアを統一
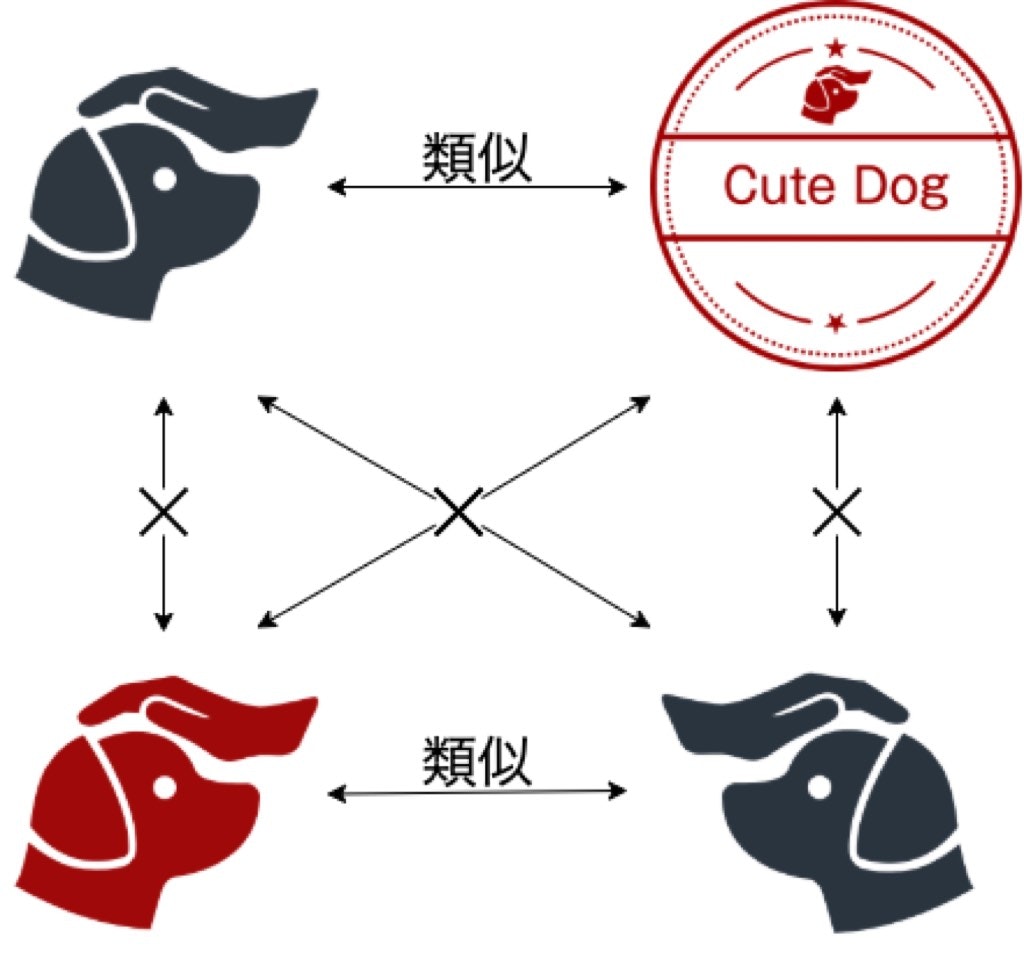
上の画像のように、類似している商標なのにその情報が関連づけられていないものが複数ありました。
学習を行う時は類似物が全て関連づけられていないと、類似しているのに非類似と学習してしまうため、修正が必要でした。
私は手作業で別のファイルを用意し、そこに対応関係を書き込む方法をとったのですが、かなり時間がかかりました。
1位の、チームtmsbirさんはphashのハミング距離を用いて類似画像をまとめています。 -
類似していないペアを除去
類似していないペアが類似していると誤って記載されているものが数組存在しました。これも学習に悪影響を与えるため、取り除きました。
-
-
画像データ :
- train.csv内の画像のロゴ部分をannotation
- YOLOv5をtrain
- YOLOv5を用いてロゴと判定された部分をthreshold:0.1でcrop
商標の中で文字の占める割合が高いと、以下の画像のように、文字の存在に引っ張られてしまい、画像検索の精度が悪くなってしまうことが運営のNotebookでも言及されていました。

そこで、文字の影響をできるだけ排除することを目標にYOLOv5を用いて、ロゴの部分のみをcropしました。

annotationもvottを使い手作業で行いました。
3,4000枚近くをannotationするのは大変でしたが、ラジオを聴きながら心を無にしてできるのでそこまで苦痛な作業ではありませんでした。
2位のanyaiさんや3位のチームTDXさんはauglyを用いて文字入れ処理を行うことでこの問題に対処しています。
私のモデルでは、ロゴのようなものが2つ以上存在した場合(例えば、文字の両側にロゴが存在する場合)ロゴの可能性が高いものを採択し、残りは捨てる処理をとっています。私の手法は使える情報を制限してしまうものだったので、auglyを用いた方がよかったのかなと思います。
Augmentation :
- train
- HorizontalFlip(p=0.5)
- Rotate(limit=10, P=0.8)
- RandomBrightness(limit=(0.09,0.6),p=0.5)
- validation
- なし
augmentationについては、種類を増やせば増やすほど精度が低下していったように感じました。
例えば、
RGBShift(r_shift_limit=255, g_shift_limit=255, b_shift_limit=255, p=0.5)
を組み込んだところ、0.163→0.1543となりました。
(limitを0~255にするのは少しやり過ぎたような気もしましたので、100以下のより小さい値に変えたりもしたのですが、白っぽい画像がほぼ白になってしまうケースがあり、悪影響が出そうだったのでRGBShiftは組み込みませんでした)
今回のコンペでは色彩相違やロゴの位置の違い、角度の違いはあったものの、ざっと見た限り激しく状態が悪い画像は少なそうでした。このことが影響しているのかもしれません。
こちらの(3)にある通り、augmentationを何でもかんでも詰め込むのではなく、推論時にどのような画像が入力されるのかを考えることが大切そうです。
Model :
- EfficientNet_b4をContrastive Lossで学習(5fold)
- Embeddingは最終層手前の1792次元のベクトルを使用
- Epoch : 20(/fold)
20epochの中でvalidation lossが最も小さい値をとるものを採択しました。

こちらの記事において、Facebook AI Image Similarity Challengeという似たコンペでは、EfficientNetv2が優れた結果を出したという記述があります。
しかしながら、本コンペではあまり良い結果は出ませんでした。
EfficientNetv2は学習が進むにつれてaugmentationを強くするprogressive learningという考え方を採用しています。
EfficientNetの方が良い結果を出せたのは、入力画像の特性から弱いaugmentationが好まれたからなのかなと思います。
Loss :
- ContrastiveLoss
loss(d, Y) = Y * d^2 + (1-Y) * max(0, m-d)^2
で表される損失関数です($ Y $は類似の場合1,非類似の場合0)。
初項で類似組の距離を近づけ、第2項で非類似組の距離を遠ざけます。
こちらのサイトの”Contrastive Loss Function”の部分が大変わかりやすいです。
Arcfaceも試してみたのですが、私の技術力が足りないせいか、全く結果が出なかったため使用しませんでした。
- CrossBatchMemory(2000)
過去の画像(のembedding)も学習に活用する手法です。
上のContrastive Lossを含めてpytorch metric learningというライブラリで実装しました。
こちらを参考にしてください。
メリットとしては、メモリの消費量を抑えつつ、あたかも巨大なミニバッチサイズで学習しているときのような効果が得られることにあり、モデルの学習に有益な難しいペアをより作りやすくなります。
後処理 :
α-weighted query expansion $α = 1$, $K=1$)
検索結果のクエリ$ \textbf q $と上位K件の検索結果$ \textbf d $を用いて新たなクエリ$ \hat{\textbf q} $を作成する方法がα-weighted query expansion(αQE)です。
クエリ1つのみで捉えきれない特徴を反映するために、検索結果の特徴を芋づる式に捕捉できる手法です。
\hat{\textbf q} = \frac{1}{Z} \sum_{i=0}^{k} w_i \textbf d_i
ただし、
\textbf{d}_0 := \textbf{q} \\
w_i = similarity(\textbf{q},\textbf{d}_i)^α
$ α=0 $のとき、$ w_i = 1 $となり AQE(Average QE:単純平均によるQE)になります。
$ α=1 $の時の αQEは加重平均のことなのかなと考え、$ Z := \sum_{i=0}^{k} w_i $としました。
詳細はこちらの”3.1 Generalized query expansion”とこちらの”4-5. Query Expansion”をご覧ください。
検索 :
Annoy(ntree=2000)
Annoyは近似近傍探索のライブラリです。
数千件であれば全てを比較し尽くす全走査が確実なのですが、検索対象が80万件近くあるため、インデックス検索を用います。
cosine類似度を用いて検索を行うので、特徴量ベクトルを大きさ1で正規化してインデックスにします。
後処理を行う前と行なったあとそれぞれでインデックスを作りました。
当初はntree=10でLB0.32程でしたが、ntreeを増やすと0.2ほどの改善に繋がりました。
メモリと残り時間の都合からこれ以上ntreeを増やすことができませんでした。
ntreeを増やして性能低下が起こることはなかったため、増やせば増やした分だけaccが上がるのだと思います。
ちなみに検索時の時間は問題ないのですが、インデックスをビルドするだけで2時間程度かかった記憶があります。
問題点:
-
過学習
lossのグラフを見れば分かるとおり、明らかに過学習が起こっています。
これを解消しようとdropoutを入れてみたのですが、精度が下がりました。
考えられる原因としては、- cross batch memory→leak
- validation時にaugumentationをかけていない
- コーディングミス
などが挙げられます。
反省点:
-
評価指標を手元で再現していなかった
致命的です。
今回はたまたまPublic LBとPrivate LBがそれほどかけ離れていない(むしろ私は全体的に上昇傾向だった)から良かったものの、かけ離れたものだったらshake downしてしまいます。
Cross Validationは行なっていたのですが、lossの値を見ていました。
というのも、1foldでできたモデルを元にして80万件の画像をベクトル化し、1foldごとに(=5回)正答率を計算するのは時間がいくらあっても足り無さそうとその時は思ったからです。
ただ、今この記事を書いていてそこまで大変なことではなさそうだったなとうっすら思います。
次からは、あくまでもコンペの評価指標をもとにしてTrust CVを手元で作れたらなと思います。 -
実験管理が全くできていなかった
W&Bなどの実験管理ライブラリを知ったのがコンペ終了の直前でした。
スコアや変更点などは全てipynbファイルの名前に書き込んでいたので大変見にくく、後から見直し辛いものとなっていました。
何が効いたのか、直前にチェックして実験のスピードを早めるためにも実験管理が重要だと痛感しました。
感想
画像認識系として初めて参加したコンペとなりました。
参加当初は低スコア域をウロウロしていたのですが、終了間際にスコアが大幅アップしました。
8位までがgold圏内だったのですが、8位の方と同スコアで9位となってしまい、少し悔しい結果となってしまいました。
ただ、画像認識の手法や深層学習の動作などを学ぶことができ、とても貴重な経験でした。