先日、ChatGPT、WhisperのAPIを活用して音声を使ってAI講師と英会話ができるアプリを公開しました。
ChatGPT APIやWhisper APIは利用自体シンプルなのでQiitaにあるチュートリアル記事がほぼ全てかなと思いつつ、参考になる情報もあるかなということで簡単に記事にしてみることにします。
前提
筆者は、オンライン英会話サービスを運営していた経験があるため、ある程度英会話サービスの運用経験やデータモデル構築経験があります。
作ったもの
今回作ったのはYapという名前のサービスです。
TOEFLやIELTSなどのスピーキング試験対策やビジネス英会話にフォーカスしたサービスで、AI講師と自由に会話することよりも、空き時間にすぐに取り組めて、適切なフィードバックを即座に受けられるというところに集中しています。
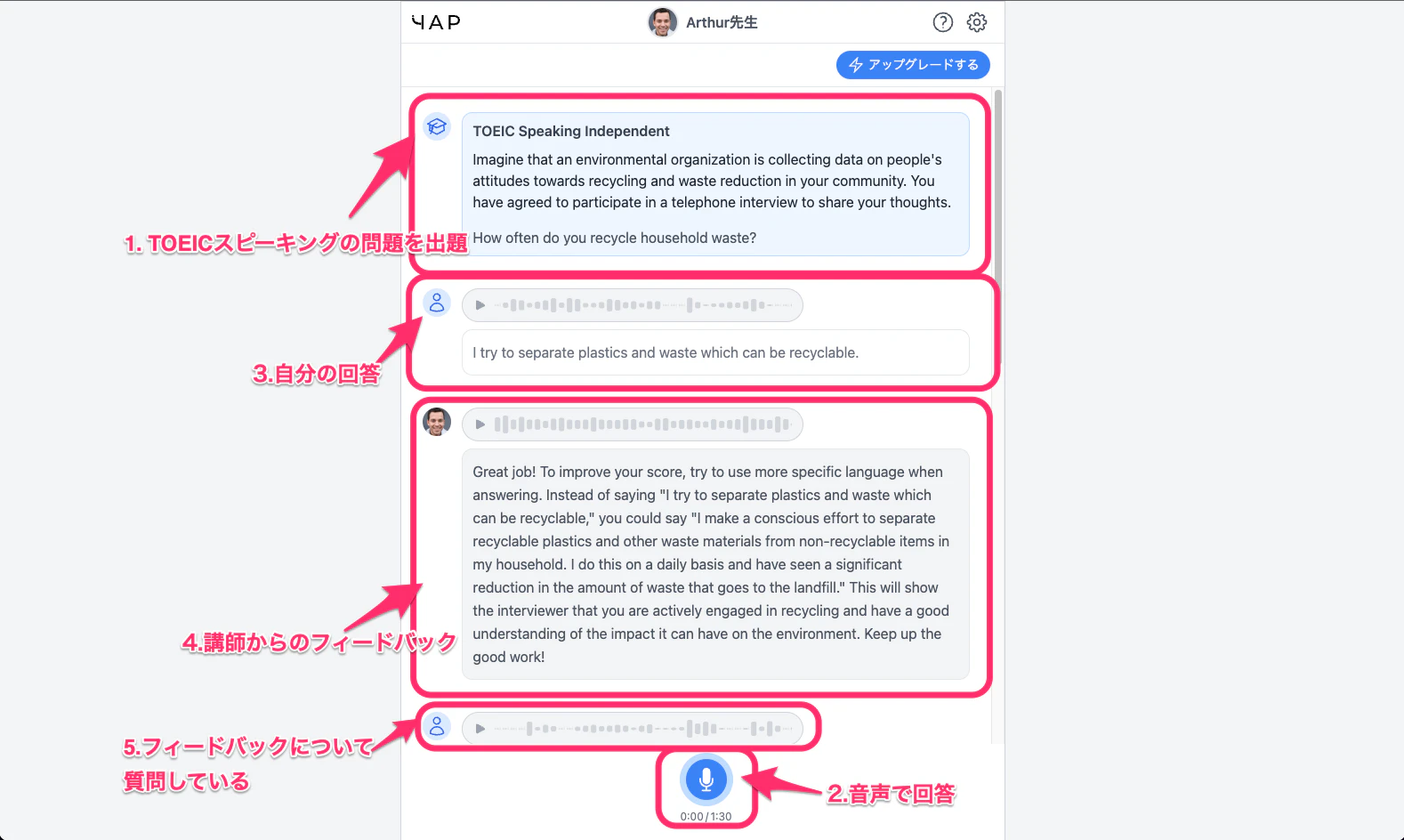
上の画像に大体書いてありますが、流れとしては、
- 選んだコースに基づいて出題される問題に回答する
- AI講師からフィードバックを受ける
- フィードバックをもとに追加の質問を行う
- 先生とフリートークをするか、次の問題に進む
という風になっています。
なぜこの形式にしたの?
実は以前から必要な学習に関してのみに、ネイティブ講師から非同期フィードバックを返して効率的に学ぶサービスというアイデアがありました。なぜかというと僕自身がTOEFLのスピーキング試験の勉強をしていたころオンライン英会話にそれだけで25分使うのもったいないと思っていて、かと言ってスピーキングだけフィードバックもらう場所がないというので困ってたからです。
ただ当時は、実際にネイティブ講師に話を聞いたところ値段が合いそうにないのでやめたという過去があります。
それが今回ChatGPT APIによりできそうだということになり、実現しました。
そんなわけで、どちらかというと、オンライン英会話で会話自体を練習したいというよりは、25分も時間取らず必要なことだけ、練習をぐるぐる回していきたいという人向けになっています。
使用技術
前回の記事にもある通り僕はElixirが好きなのでElixir使いたかったのですがまだ今は公式のNodeライブラリを使うのが良いかなと思いTypeScriptだけ使ってます。(Nodeはそんなに好きじゃないので若干後悔もあり笑)
使っているものは以下のような感じです。
- TypeScript
- Apollo Server
- Next.js
- Tailwind
- Prisma
- Nexus
- nexus-prisma
- Uppy
- Uppy Companion
- ChatCompletion API(ChatGPT API)
- Whisper API - Speech-to-Text
- AWS Polly - Text-to-Speech
- S3, CloudFront
- Redis(PubSubのみ)
- PostgreSQL
- SuperTokens - Authentication
技術選定
Next.js、Tailwind
普段から使っているため。
Apollo Server
以前にNest.js、TypeORMでアプリを作ったことがあったのですが、今回のように小さなアプリでNestjsはやりすぎだなということや既に忘れてしまっているので、今回はApollo Serverを使って雑に作ることにしました。
Prisma
Prismaも前に少し使った経験があり、データベースマイグレーションがほぼ自動でできるので小さめのアプリだとPrismaで必要十分以上かと思います。
Nexus
個人的にコードベースでGraphQLスキーマを生成するのが好みなのと、TypeGraphQLは以前に使っていてバグが多かった印象があるのでNexusを選びました。Prisma公式でもNexusを推しています。また今回prismaチームが開発を進めているnexus-prismaライブラリを使用しました。
nexus-prisma
Prisma公式が開発しているらしきNexus連携です。まだ鋭意開発中ということで動きに怪しいところもありますが、Graphqlモデルがこんな感じで簡単に定義できます。NexusPracticeとなっているところですね、全部に適用されてないのはたまに生成失敗しているのかタイプエラー起きることがあるからです
import { objectType, unionType, enumType } from 'nexus'
import { Practice as NexusPractice, PracticeStatus } from 'nexus-prisma'
export const Practice = objectType({
name: NexusPractice.$name,
description: NexusPractice.$description,
definition(t) {
t.field(NexusPractice.id)
t.field(NexusPractice.user)
t.field(NexusPractice.type)
t.field(NexusPractice.category)
t.field(NexusPractice.passage)
t.field('status', { type: enumType(PracticeStatus) })
t.boolean('isRetry')
t.field(NexusPractice.createdAt)
t.field(NexusPractice.updatedAt)
t.field(NexusPractice.practiceDirection)
t.field(NexusPractice.practiceParts)
},
})
Uppy, Uppy Companion
クライアントからS3へのダイレクトアップロードに使ってます。ただ結局サーバーサイドに音声を落としているのでダイレクトアップロードいらなかったかもしれません。
ChatGPT API, Whisper API
これらが開発の前提
Polly
色々調べた結果、レビューの評価と料金とを鑑みてバランスが取れていた。Neuralを使うと値段が数倍上がるのですが、先生の声はいい感じのものがいいなということでNeuralにしました。
S3、CloudFront
特になし。AWS Pollyと相性良い。
Redis
後で書きますが、JobQueueでChatCompletionとPolly部分をやろうとしていた。
現状はWebsocketのPubSubのみ。Cacheはまだ特に入れてません。
PostgreSQL
いつもPostgreSQL使ってます。
SuperTokens
Firebase Auth、Supabase Auth、Auth0あたりを検討して、オープンソースを試すことにしてSuperTokensを入れました。いい感じなのですが、まだ黎明期のツールなので、Nextでパスワード入力を無くしたり、マジックリンクを使えなくしたりする処理が後々必要になりました。しかし料金も安いので基本的におすすめです。
開発期間と開発の様子
基本的な、音声を録音して、フィードバックを返すみたいなところはそんなに時間かかりませんでした。
ちゃんと記録してないのですが、大体こんな感じのスケジュール感だった気がします。うろ覚えなのであたりとつけてます笑(*別でフリーランスのお仕事や、別で運営しているサービスもちょっとしているので全部の時間使えているわけではないです。)
1-3日目あたり
技術選定してました。Nest.jsのプロジェクトを立ち上げてみて消したり、Supabaseなどをちょっと触ってみたりしてました。
4-7日目あたり
ChatGPTにデータベースモデル作ってもらったりして失敗して結局自分で考え直したりしてた。
単純な短問回答問題で、チャット画面、音声入力、ChatGPTからの返信までして。自分でちょっと遊んでました。
8-10日目あたり
元々考えてた、一つのチャットUIで全てのやり取りを行うのではなく、練習問題ベースでチャットページを切り替えるスタイルに変更しました。
11日目から17日目あたり
問題を作成したり、今後ビジネス英会話やIELTSなど問題の形式が複雑になったとしても対応可能なようにリレーションを見直したり、データベースモデルを見直ししたりしていました。
18-25日目あたり
大体こんな感じです。
- ランディングページの作成
- 最低限のエラーハンドリング
- 講師とのフリートーク
- ChatGPTコンプリーションも調整入れていい感じの回答も来るようにできた。がChatGPT3.5だとたまに頭が悪いこともある。
リリース一旦できそう。
26-28日目あたり
- 公開するサーバーの選定。AnsibleとTerraformを使おうとしてよく考えたらいらなそうと気づいて、Fly.ioを検討するも、Renderが一番簡単そう。ということでRender.comにデプロイ。
- モダルを追加して使い方説明を追加したり、翻訳をちゃんと入れたりしました(英語版と日本語版があるため)
29-31日目あたり
- 開発者コミュニティでシードをちょっと試してもらいフィードバックをもらう。
- ここまでで実装していた録音機能が使いづらいということでUIの改善
- JobQueueだとどうやらスケールが難しそうなので、仕方なくエラーが発生すること前提で、音声用のスクリプト生成と音声生成をjobQueueなしでやることにする
- Stripeを使ってサブスクを実装(クレジットを使うアイデアもありましたが、OpenAIやAWSへのリクエストのエラーハンドリングが大変そうだと思い、一旦無制限利用プランのみで、Stripeの料金テーブルを使ってWebhookだけで対応するという風にしています。
32日目
Corsの設定をちゃんと入れたり、プライバシーポリシーなどを追加して公開
はまったところや反省点
-
Node.jsはエラー原因特定ちょっと大変な気がする
最近はElixirメインでサーバーサイドを書いていたので、久しぶりにNodeをちゃんと使ってなかったからというのもありますが、Expressでバグが発生した時に場所特定がちょっと面倒だなと思いました。ただElixirはElixirで非人気言語ゆえの苦労がたくさんあるのでどっちもどっち。 -
NodeでJobQueue使うと逆にスケールできなさそう
ChatGPTに相談してたのですが、jobQueueのconcurrency増やすとアプリの負担が増えるから気をつけてとか言われて、OpenAIとPollyのリクエスト5-10秒ぐらいかかるんだけど、その間他のリクエストは走らないんじゃないのって聞くと、そうだねっという回答が来たので普通にシングルスレッドで回す方が実は数対応できるということに気づきました。が、Elixirだと数百万同時API走らせても平気だよねって思うと、やはり次からElixir使うのがいいかもと思いました。 -
Nextjsのi18nはSEOが鬼門
英語版と日本語版作りましたが、Nextのi18nがそんなにSEOに強くないのではという疑念があり、日本語版だけにしてれば数日早くリリースできて、SEOにもよかった可能性があります。 -
AWS Pollyのリスポンスが遅い
WhisperやChatCompletionのlatencyを心配してましたが、実は一番時間がかかるのがPollyでの音声生成でした。 -
実はWeb Speech APIを使った方がWhisperを使うより良さそう。
Whisperはとても性能が高いのですが、今回のようなサービスではChatGPT APIよりもWhisperやPollyの値段が5倍ほど高くなります。それに加えて一旦音声をダウンロードしてWhisperにAPIを投げるということをしているので、Web Speech APIを使った方がユーザー体験も上がり(要はスピードが上がる)、値段も安くなりそうです。多分すぐにWeb Speechに切り替えると思います。
今後の開発予定(やりたいこと)
まだまだ実は実装したいものがたくさんあります。
- 講師からの返信のストリーム再生
- 問題文の読み上げ対応
- 問題だけではなくてレクチャーを含む問題
- 実際のTOEFLのように15秒考えて40秒話すというような流れを入れたい。(ただ、これはLINEやWhatsappだと不可なので悩んでいます)
- IELTSのスピーキング試験のような会話主体の問題
- パラフレーズ(自分が言った言葉のもっとネイティブらしい表現を教えてくれる)
- 講師からの返信の翻訳(これは簡単に入れられるのではあるけど、複数言語の扱いも考えててまだ未対応)
などなど、Embeddingsを利用して先生が生徒との会話で昔出た話題なども含めて返答してくれるということもしたいですね。
ChatGPT APIとWhisper APIの実装について
プロンプトエンジニアリングなどありますが、GPT4モデルと違いGPT3.5モデルはたくさん条件を追加してもそれをしばしば無視します。ので条件を少なめにしたりする必要や、それまでの会話全部を渡すのではなく情報を絞ったりしています。こうした調整は必要ですが実装自体には難しいところはないかと思います。
まとめ
そんなわけで、ChatGPTとWhisperを使ったサービス開発についての知見シェアでした。
現状は中上級者の方向けのアプリとなっておりますが、もしTOEFLやIELTSのスピーキング対策をされているという方がいて僕のようにスピーキング練習の場所に困っている方がいたらぜひお試しいただければと思います。
YAP