概要
意味解析まではできたので,簡単な算術演算と代入文だけに着目してバイトコードの生成,およびその実行を考える.今回はスタックマシンを採用するので,まずは算術演算と代入をどのようにスタックマシンで実現するかを考え,その後どのようなバイトコードを生成すればよいかを考えていく.
演算の場合のスタックマシンとコード生成
まず,スタックマシンで1+2のような計算を行う時,どのようにスタックを使うのかを考えてみる.とはいえこれはとても簡単で,以下のようにスタック使えば良い.
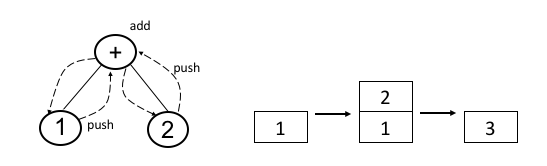
まず,左辺の1をスタックに積み,次に右辺の2を積む.最後に,スタックのトップの2つの数を加算し,結果をスタックに積む.これは,上の図にあるように,加算のASTを深さ優先探索でたどっていき,帰りがけに値の場合はスタックにプッシュ,演算の場合はスタックに積まれた値を使って計算し,結果をスタックにプッシュする,というアルゴリズムで実現できる.そのため,この動作を実現するバイトコードは,次のようにすれば良いことがわかる.
push 1
push 2
add
このコードを生成するには(ほとんど前述の繰り返しになるが),ASTを深さ優先探索でたどっていき,値の場合にはpush 値を生成,演算の場合には演算を行う命令addを生成していけば良い.このアルゴリズムは,1+2*3のように,演算の組み合わせでもうまく動作することが容易に想像できると思う.
代入の場合のスタックマシンとコード生成
代入式の場合,i = 1のように,右辺の値を左辺の変数に代入する.そのため,右辺の値をスタックに積み,その値を変数の格納先である領域に取り出す,という動作をすれば良い.この例では右辺が定数なので,この定数をどこに格納しておくか,ということが問題になる.また,変数の格納先だが,これはどこになるのか,ということも考えなければならない.
まず,定数の格納先だが,バイトコードに直接埋め込む方法と,関節アクセスする方法が考えられる.バイトコードに直接埋め込む,というのは,例えばint型をpushするという命令をpush_int(0x30)だとし,定数1を格納することを考えると,0x30 0x01 のように,0x01を直接書いてしまう方法である.ここまでの言語では,int, double, boolean型しかないので,埋め込む値はたかがしれている.しかし,今後文字列も導入しようとすると,文字列の長さは事前にはわからないので,少々面倒くさくなる.一方,関節アクセスするとは,定数を格納できる領域を確保しておいて,そこに値を格納し,その格納先のアドレス(インデックス)を使う,という方法である.これは,配列のアクセスの仕方を想像すると良い.この場合,関節アクセスになるので速度は犠牲になる.
今回は,命令を簡略化するため,また文字列など入ってきた場合に統一したアクセス方法のほうがなんとなく気持ちが良いので,関節アクセスする方法を取ることにする.
次に,変数の格納先だが,これも定数の格納先同様,変数にインデックスを振っておき,変数を見つけたらそのインデックスを参照すればよい.そして,代入するときにはそのインデックスを使用してスタックからPOPして値を格納すればよいということになる.なお,いくつの変数を使うかは静的に決められるので,コンパイル時に確定させ,変数名とインデックスを対応付けておく.
この動きを図示すると,以下のようになる.
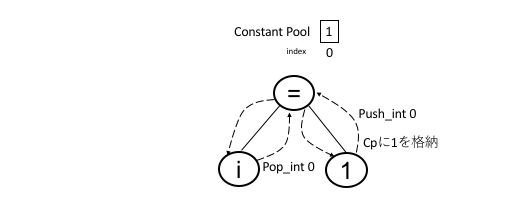
代入文に関するコード生成では,右の式からコード生成し,最後に変数のインデックスに値を格納する命令を生成すれば良いことがわかる.また,変数に格納するのは実行時だが,定数を格納するのはコード生成時であることに注意する.したがって,この例では,
- 右辺に定数があるので,それをConstant Pool(CP)に格納し.そのインデックスを保持する
- そのインデックスを使って値をスタックにpushする(push_int index)命令を生成する
- 左辺のインデックス(この場合0)を使ってスタックから値をpopする
という命令を生成すれば良い.具体的には,以下のような命令を生成する.
push_int 0
pop_int 0
くどいようだが,1の定数の格納はバイトコードの生成ではなく,変数の格納である.また,この例では,左辺の変数に格納されている値は捨てられるので何もしていないが,一般的に変数をアクセスされるときにはその値を使うので,push_int 0のような命令を生成する必要がある.
式文のコード生成
ここまでで,一般的な計算する式の場合と代入式の場合を考えてきたが,代入式を実行すると最終的にスタックには何も残っていないことが想像できると思う.しかし,一般的な計算式の場合,最終的な計算結果がスタックに残されることになる.そこで,式文を終了するときにはスタックから値を削除しなければならない.
よって,以下のコードの場合
i = 1 + 2;
push_int 0 // 定数1を格納しているインデックスが0
push_int 1 // 定数2を格納しているインデックスが1
add
pop_int 0
だが,
1 + 2;
だと
push_int 0
push_int 1
add
pop
となる.つまり,代入式なのかそれ以外か,によって最後に生成する命令を変える必要がある.
バイトコードの生成準備
ここまでの流れから,プログラムを実行するときには定数を格納しておく領域を用意し,定数はその領域に保存しつつ,変数に対応する何らかの領域が必要なことがわかる.それらの領域の大きさはコンパイルが終わった時点で静的に確定できる.つまり,プログラムを一度解析すれば変数の数は分かるし,プログラムに出現する定数(1とか1.2)の数も分かる.プログラムを実行するときには,バイトコードを解釈していくだけでなく,定数の領域を用意してコンパイル時に出現した定数を格納しつつ,変数の領域から,値を読み出し/値を格納しながらプログラムを実行していくことになる.そこで,コンパイルでは,定数を格納,必要な変数の情報を格納.バイトコードを生成し,最後にそれらをシリアライズしてバイナリとして出力することを目指す.
そこで,これら情報を格納するための構造体を定義する.
typedef struct {
char *name;
TypeSpecifier *type;
} CS_Variable;
typedef enum {
CS_CONSTANT_INT,
CS_CONSTANT_DOUBLE
} CS_ConstantType;
typedef struct {
CS_ConstantType type;
union {
int c_int;
double c_double;
}u;
} CS_ConstantPool;
typedef struct {
uint32_t constant_pool_count; // 定数の数.コンパイル実行後に確定
CS_ConstantPool *constant_pool; // 定数を格納する領域
uint32_t global_variable_count; // 変数の数.意味解析実行後に確定可能
CS_Variable *global_variable; // 変数の情報を格納.コンパイルするだけなら不要.
uint32_t code_size; // バイトコードのサイズ.コンパイル実行後に確定
uint8_t *code; // バイトコードの実体
} CS_Executable;
CS_Executableがシリアライズに必要な情報を格納する構造体であり,CS_ConstantPoolに定数を格納する.また,CS_Variableは変数の情報を格納する.バイトコードとそのサイズは*codeとcode_sizeに格納する.例えば,
int i;
i = 1 + 2;
のようなプログラムがあったとすると,定数は1,2の2つで,バイトコードからはそれらのインデックスで参照する.具体的には,constant_poolのインデックス0に1が格納され,インデックス1に2が格納される.これらの値を参照するにはconstant_poolのインデックスを利用する.また,このプログラムでは変数は1つ(i)だけだが,意味解析が終わった時点ですべての変数はDeclarationListに繋がれており,意味解析の最後でそれぞれの変数にインデックスを割り当てるので,iを利用するには実行時の変数格納領域のインデックス0を利用すれば良いことがわかる.
バイトコードの定義
ここまで,代入式や加算式を例にバイトコードの例を出してきたが,プログラムを実行するのに必要十分なバイトコードを定義する必要がある.スタックマシンの計算とは,結局のところ
- 値の取り出し
- 値の保存
- 加算や減算などの演算
を行うに過ぎない(関数呼び出しはまだ考えない).そして,演算に関しては,プログラム言語で定義した演算子に対応するバイトコードをよういすれば用意すればよく,演算は多くの場合,
- スタックに積まれた値を必要な数だけPOP(2項演算なら2つ)
- 演算子に従った計算をする(加算など)
- 結果をスタックにPUSH
という動作をすればよい.よって,演算子に対応するバイトコードには引数のようなものは不要.
一方,値の取り出しや保存は,「どこに保存」するか,また,「どこから取り出す」か,といった,場所の情報が必要になる.これまでの議論から,場所とは結局,変数や定数の格納場所に対応するインデックスである.ということは,例えば値を取り出す時,変数から取り出すのか,定数から取り出すのか区別できる必要があり,かつそのインデックスを指定する必要がある.つまり,値の取り出し,保存には引数が必要になってくる.現時点ではグローバル変数しかありえないため,値の保存場所は(グローバル)変数だけだが,今後のことを考え(関数呼び出し),スタックにも保存できるようにする必要がある.というわけで,値の保存先は
- スタックに確保されるローカル変数
- グローバル変数
の2種類であるため,まずはグローバル変数に対応する命令としてPOP_STATIC_XXX(XXXはINTやDOUBLEの型名),ローカル変数に対応する命令としてPOP_STACK_XXXを用意する.
一方,値の取り出し先は,
- スタックに確保されるローカル変数
- グローバル変数
に加え,
- 定数
がある.そのため,PUSH_STACK_XXX,PUSH_STATIC_XXXに加え,定数から取り出す,PUSH_XXXを用意する.
まとめると,保存先は2種類,取り出し先は3種類,ということになる.こうしたバイトコードを定義したヘッダ(svm.h)を用意し,enumで定義する.これらバイトコードは主に実行するときに使うので,保存場所としてsvmディレクトリを新規に作成する.
typedef enum {
SVM_PUSH_INT = 1,
SVM_PUSH_DOUBLE,
SVM_PUSH_STACK_INT,
SVM_PUSH_STACK_DOUBLE,
SVM_POP_STACK_INT,
SVM_POP_STACK_DOUBLE,
SVM_PUSH_STATIC_INT,
SVM_PUSH_STATIC_DOUBLE,
SVM_POP_STATIC_INT,
SVM_POP_STATIC_DOUBLE,
SVM_ADD_INT,
SVM_ADD_DOUBLE,
(略)
また,後述するが,バイトコードを生成する時,それぞれのバイトコードに引数が存在するのか,存在するならその個数はいくつか,などの情報を定義して追う必要があるため,それらの情報を定義する構造体(OpcodeInfo)も定義する,
typedef struct {
char *opname;
char *parameter;
uint8_t s_size;
} OpcodeInfo;
そして.それぞれのバイトコードに対応する情報を定義する配列を用意する.
OpcodeInfo svm_opcode_info[] = {
{"dummy", "", 0},
{"push_int", "i", 1},
{"push_double", "i", 1},
{"push_stack_int", "i", 1},
{"push_stack_double", "i", 1},
{"pop_stack_int", "i", -1},
{"pop_stack_double", "i", -1},
{"push_static_int", "i", 1},
{"push_static_double", "i", 1},
{"pop_static_int", "i", -1},
{"pop_static_double", "i", -1},
(略)
みれば分かるように,配列のインデックスがバイトコードと一致する.また,引数がある場合はiを記入し,2バイトBigEndianで数値を格納することとする(詳しくはバイトコードの生成で).
バイトコード生成
バイトコード生成は,結局の所CS_Executableを生成することである.具体的には,意味解析が終わったASTを使って,
- バイトコードの生成
- 定数の格納
を行えば良い.そこで下図のように,POPやPUSHにはインデックス情報が必要になるが,定数が出てくるたびにCS_ConstantPoolに格納し,constant_pool_countをインクリメントすれば定数のインデックスは分かる.また,変数に関しては,意味解析のときにidentifier(識別子)から実体のポインタを参照するようにしているし.さらに参照先であるDeclarationListには出現順(先頭を0として連番)に意味解析の最後にインデックスをふっているので,その参照をたどることでインデックスは取得できる.
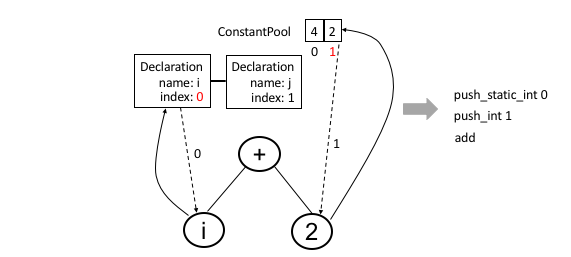
バイトコード生成はASTを操作するので,バイトコード生成専用のCodegenVisitorを作る.
typedef enum {
VISIT_NORMAL,
VISIT_NOMAL_ASSIGN,
} VisitState; // 代入文のときに状態遷移が必要
struct CodegenVisitor_tag {
Visitor visitor; // 意味解析と同様Visitorを継承
CS_Compiler *compiler;
CS_Executable *exec; // この中身に適切に情報を格納する
VisitState v_state; // 代入のバイトコード生成を参照
uint16_t assign_depth; // 代入のバイトコード生成2を参照
uint32_t CODE_ALLOC_SIZE;
uint32_t current_code_size;
uint32_t pos;
uint8_t *code; // 生成したバイトコードを格納
};
演算のバイトコード生成
1+2のバイトコード生成を考える.VisitorでASTをトラバースし,戻りながら(leave_xxxの関数で)バイトコードを生成する.今回相となるノードは
- INT_EXPRESSION
- ADD_EXPRESSION
以下のコードで具体的に生成する.
typedef struct {
CS_ConstantType type;
union {
int c_int;
double c_double;
}u;
} CS_ConstantPool;
/* CS_ExecutableのConstantPoolに追加し,インデックスを返す */
static int add_constant(CS_Executable* exec, CS_ConstantPool* cpp) {
exec->constant_pool = MEM_realloc(exec->constant_pool,
sizeof(CS_ConstantPool) * (exec->constant_pool_count+1));
exec->constant_pool[exec->constant_pool_count] = *cpp;
return exec->constant_pool_count++;
}
static void leave_intexpr(Expression* expr, Visitor* visitor) {
CS_Executable* exec = ((CodegenVisitor*)visitor)->exec;
CS_ConstantPool cp;
cp.type = CS_CONSTANT_INT;
cp.u.c_int = expr->u.int_value;
int idx = add_constant(exec, &cp); // 定数のConstantPoolを作成し,追加する
gen_byte_code((CodegenVisitor*)visitor, SVM_PUSH_INT, idx); // 返されたインデックスを使ってバイトコードを生成
}
static void leave_addexpr(Expression* expr, Visitor* visitor) {
switch(expr->type->basic_type) {
case CS_INT_TYPE: {
gen_byte_code((CodegenVisitor*)visitor, SVM_ADD_INT);
break;
}
case CS_DOUBLE_TYPE: {
gen_byte_code((CodegenVisitor*)visitor, SVM_ADD_DOUBLE);
break;
}
default: {
fprintf(stderr, "%d: unknown type in leave_addexpr codegenvisitor\n", expr->line_number);
exit(1);
}
}
}
gen_byte_codeの詳細はさておき,1や2の定数はleave_intexprでSVM_PUSH_INTのバイトコードが生成される.また,ADDに関しては,leave_addexprでSVM_ADD_INTまたはSVM_ADD_DOUBLEのバイトコードが生成される.
今回,インデックスは2バイトのBigEndianで格納すると決めたので,1+2から生成されるバイトコードは
01 00 00 01 00 01 0b
こうなる.1バイト目,4バイト目の01はSVM_PUSH_INT, それぞれの後に続く0000, 0001はそれぞれのインデックス.そして,0bはSVM_ADD_INTである.
変数のバイトコード
変数がプログラムに表れた時,代入と参照が考えられる.代入は後述するとして,参照のバイトコードはコードは以下のようになる.
static void leave_identexpr(Expression* expr, Visitor* visitor) {
CodegenVisitor* c_visitor = (CodegenVisitor*)visitor;
switch(expr->type->basic_type) {
case CS_BOOLEAN_TYPE:
case CS_INT_TYPE: {
gen_byte_code(c_visitor, SVM_PUSH_STATIC_INT,
expr->u.identifier.u.declaration->index);
break;
}
}
(略)
現時点では,変数はグローバル変数しかありえないので,必然的に生成するバイトコードはSVM_PUSH_STATIC_XXXとなる.そして,変数のインデックスはexpr->u.identifier.u.declaration->indexで参照している.これは先の図に示した通り.また,この言語にはboolean型があるが,バイトコードにするときにtrueは1,falseは0に置き換える.
代入のバイトコード
代入は,i=1のようなコードになるが,これは「変数iに1を保存する」,という振る舞いになる.先ほど変数のバイトコードを示したが,その時は変数のバイトコードはSVM_PUSH_であった.これは値の保存ではなく,値の取り出す振る舞いであり,代入にはマッチしない.ここでは変数に保存しなければならないので,SVM_POP_xxxという命令を生成しなければならない.つまり,変数のバイトコードは代入で用いられる時とそれ以外で用いられるときで振る舞いを変える必要がある.さらに,代入で用いられる場合でも,
i = j;
を考えると,このコードは右辺のjの値をiに代入するという振る舞いにする必要があるため,「jの値を取り出し」「iに保存する」としなければならない.つまり,変数のバイトコードが代入の右辺に現れるときにはSVM_PUSH_左辺に現れるときにはSVM_POP_としなければならない.VisitorがASTを操作する時,代入文が現れると右辺を先に訪問し,次に左辺を訪問するようにしている.そのため,右辺をすべて訪問し終わり,左辺を訪問するときに状態を変化させ,右辺を訪問しているのか,それとも左辺を訪問しているのか判断できるようにする必要がある.
そのため,こうした状態を管理するために先に示したVisitStateを定義している(再掲).
typedef enum {
VISIT_NORMAL, // 代入の右辺を含む通常状態を示す.この時変数はPUSH系の命令を生成する
VISIT_NOMAL_ASSIGN, // 代入の左辺を訪問中であることを示す.この時変数はPOP系の命令を生成する.
} VisitState; // 代入文のときに状態遷移が必要
さらに,この,右辺から左辺に移動する時,を何らかの形で知る必要があるが,現状のVisitorの訪問方法は,
(略)
case ASSIGN_EXPRESSION: {
traverse_expr(expr->u.assignment_expression.right, visitor);
traverse_expr(expr->u.assignment_expression.left, visitor);
(略)
となっており,右辺が終わってからすぐに左辺を訪問するので,その間にvisitorに通知するして,状態を変化させる必要がある.そこで,visitorにnotify_expr_listを追加し,通知するように変更した.
(略)
notify_expr_list[ASSIGN_EXPRESSION] = notify_assignexpr;
(略)
static void notify_assignexpr(Expression* expr, Visitor* visitor) {
((CodegenVisitor*)visitor)->v_state = VISIT_NOMAL_ASSIGN; // 状態を変化させる
}
case ASSIGN_EXPRESSION: {
traverse_expr(expr->u.assignment_expression.right, visitor);
if (visitor->notify_expr_list) { // 通知する
if (visitor->notify_expr_list[ASSIGN_EXPRESSION]) {
visitor->notify_expr_list[ASSIGN_EXPRESSION](expr, visitor);
}
}
traverse_expr(expr->u.assignment_expression.left, visitor);
break;
}
こうすることで,変数に対応するバイトコードを生成する時,VisitStateの状態を見て,SVM_PUSH/SVM_POPどちらの命令を生成するかを切り替える.
static void leave_identexpr(Expression* expr, Visitor* visitor) {
switch (c_visitor->v_state) {
case VISIT_NORMAL: { // 値の取り出しのバイトコードを生成
switch(expr->type->basic_type) {
case CS_BOOLEAN_TYPE:
case CS_INT_TYPE: {
gen_byte_code(c_visitor, SVM_PUSH_STACK_INT,
expr->u.identifier.u.declaration->index);
break;
}
(略)
}
break;
}
case VISIT_NOMAL_ASSIGN: { // 値の保存のバイトコードを生成
switch (expr->type->basic_type) {
case CS_BOOLEAN_TYPE:
case CS_INT_TYPE: {
gen_byte_code(c_visitor, SVM_POP_STATIC_INT,
expr->u.identifier.u.declaration->index);
break;
}
(略)
さて,変化させたVisitStateをいつもとに戻すか考えなければいけないが,それは後述.
代入のバイトコード2
このプログラム言語では,以下のようなコードを書くことができる
int i;
int j;
int k
k = 10;
i = j = k;
この時期待する振る舞いは,iとjに10が代入されていることである.先ほどの議論から,代入の左辺に識別子があった場合には保存の命令(SVM_POP_XXX)が生成されるので,jには代入できるが,そうすると保存する値がすでにスタックからなくなっているので,iには代入できないことになる.これを防ぐには,jのときにはSVM_POP_XXXじゃなくて,値をコピーするバイトコード(SVM_DUP_XXX)を定義して出力するか,POPしたあと更にPUSHするか,の2択である.ここでは,命令を増やしたくないので後者のアプローチを取る.
さらに,文法的には
x = y = z = a = b = c = ...
も許されるわけなので,いつPOP/PUSHをペアで出力するのか,いつPOPだけにするのかを判定できないと困る(当然,左辺に代入される識別子がない場合であるが,各識別子はそうした情報を持たないので判定できない).
というわけで,代入式の深さを利用して判定する.そのためにVisitorにassign_depthを用意しておいた.
uint16_t assign_depth; // 代入のバイトコード生成2を参照
これを使い,visitorがASSING_EXPRESSIONのノードを訪問したらインクリメント,出ていくときにデクリメントする.
static void enter_assignexpr(Expression* expr, Visitor* visitor) {
((CodegenVisitor*)visitor)->assign_depth++;
}
static void leave_assignexpr(Expression* expr, Visitor* visitor) {
--((CodegenVisitor*)visitor)->assign_depth;
}
そして.識別子のノードでは,assign_depthが1より大きいとき,つまり,i=j=1のjのような状況ではSVM_PUSH_XXXの命令を生成するようにすれば良い.
if (c_visitor->assign_depth > 1) { // nested assign
switch(expr->type->basic_type) {
case CS_BOOLEAN_TYPE:
case CS_INT_TYPE: {
gen_byte_code(c_visitor, SVM_PUSH_STACK_INT,
expr->u.identifier.u.declaration->index);
break;
}
VisitStateを戻すタイミング
代入式で変更したVisitStateはもとに戻さなければいけない.そうでないと,例えば
int i;
int j;
i = j = 10;
i+j;
のようなi+jでも代入が行われてしまう.また,
i = 10;
このような場合だと,iのバイトコードはSVM_POP_XXXとなるので,スタックには何も残らないが,
int i;
i = 10;
i;
このようなプログラムだと,3行目でiの値がPUSHされてそのままになってしまう.iの値は捨てられてしかるべきである.
以上を考えると,式文の終わりを認識した時,
- 代入文だったらVisitStateをもとに戻す.
- それ以外の文だったらスタックの値を捨てる.
とすればよい.代入文だったかどうかはVisitStateを見れば分かるので,以下のような実装になる.
static void leave_exprstmt(Statement* stmt, Visitor* visitor) {
CodegenVisitor* c_visitor = (CodegenVisitor*)visitor;
switch (c_visitor->v_state) {
case VISIT_NORMAL: {
gen_byte_code(c_visitor, SVM_POP); // 代入式ではないのでスタックから値を削除
break;
}
case VISIT_NOMAL_ASSIGN: {
c_visitor->v_state = VISIT_NORMAL; // 状態をもとに戻す
c_visitor->assign_depth = 0; // 深さを0に戻す
break;
}
default: {
fprintf(stderr, "no such visit state in leave_exprstmt\n");
break;
}
}
}
この他,生成したバイトコードが正しいかどうか確認するために逆アセンブルする機能も実装した.以下のプログラムをバイトコードに変換した結果を示す.
int j;
int i;
i = 4;
j = i = i + 5;
結果
< Disassemble Start >
-- global variables --
[0]j:int
[1]i:int
-- constant pool --
pool count = 2
[0]:4
[1]:5
-- code --
01 00 00 09 00 01 03 00 01 01 00 01 0b 09 00 01
03 00 01 09 00 00
push_int 0000
pop_static_int 0001
push_stack_int 0001
push_int 0001
add_int
pop_static_int 0001
push_stack_int 0001
pop_static_int 0000
< Disassemble End >
逆アセンブル結果をよく見ると,正しくバイトコードが生成できていることが分かる.
ここまでの実装は,以下のコマンドで試すことができる
>git clone https://github.com/hiro4669/csua.git
>cd csua
>git branch begin_code_gen origin/begin_code_gen
>git checkout begin_code_gen
>make
>./comp/cgent ./comp/tests/prog4.cs
目次に戻る