概要
バイトコードにコンパイルしたデータから,仮想マシンで読み込んで実行するためのファイル(バイナリファイル)を生成する.プログラム自身はバイトコードだけだが,それだけではプログラムは実行できず,定数や変数を格納しておく領域が必要となる.また,変数の初期化処理を行う場合には,変数の型情報も必要だし,実際にプログラムを実行するには作業領域であるスタックを確保する必要があるので,そのおおよその見積もりもできていたほうが都合が良い.
CS_Executableのデータ
バイナリコード生成とは,結局以下のCS_Executableの生成であった.
typedef struct {
uint32_t constant_pool_count; // 定数の数.コンパイル実行後に確定
CS_ConstantPool *constant_pool; // 定数を格納する領域
uint32_t global_variable_count; // 変数の数.意味解析実行後に確定可能
CS_Variable *global_variable; // 変数の情報を格納.コンパイルするだけなら不要.
uint32_t code_size; // バイトコードのサイズ.コンパイル実行後に確定
uint8_t *code; // バイトコードの実体
} CS_Executable;
バイトコードの生成を行うことで.CS_Executableは完成しているので,ここに格納されたデータのフォーマットを決めてバイナリを生成していけば良い.ここでは,以下のフォーマットでバイナリを生成することとする.
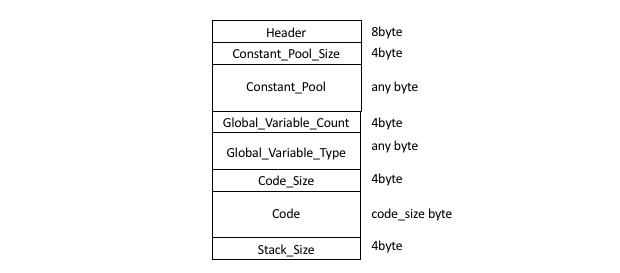
Header
ヘッダにはJavaのCAFEBABEを真似て,CAPHESUAという文字をASCIIコードで入れる.
Constant_Pool_Count
4バイトのBigEndianで定数の数を書き込む.
Constant_Pool
定数には複数の型(intとdouble)を書き込む可能性があるので,値だけではなく型情報も書き込む.intは4バイト,doubleは8バイトのBigEndianで書き込んでいく.型情報は1バイトあれば十分なので,"(1+4/8) * coustant_pool_count"バイト分のデータが書き込まれることになる.なお,doubleはIEEE754形式とする(とはいえ,C言語のdouble表現がこの形式に従っているので,単に書き込んでいくだけでよい).
Global_Variable_Count
4バイトのBigEndianで定数の数を書き込む.
Global_Variable_Type
CS_ExecutableのCS_Variableにはグローバル変数の情報が格納されている.グローバル変数は値の代入で利用し.その数はコンパイル時に確定しており,型チェックは意味解析でやっているので,実行時は配列でその領域を確保するだけでよい.しかし,それら変数の初期値を確定させるために,型情報を書き込んでいく.型情報は1バイトで十分なので,"1 * global_variable_count"バイト分データが書き込まれる.
Code_Size
生成したバイトコード数をBigEndianで書き込む.
Code
バイトコードを書き込む
Stack_Size
実行開始時に必要となりそうなスタックサイズを4バイトのBigEndianで書き込む.スタックサイズの計算は,バイトコードに含まれるPUSH系命令についているOpcodeInfoのs_sizeを利用する.
typedef struct {
char *opname;
char *parameter;
char s_size; // 命令が必要とするスタックサイズ量
} OpcodeInfo;
実装
上記の内容を愚直に実装していく
static void serialize(CS_Executable* exec){
FILE *fp;
if ((fp = fopen("a.csb", "wb")) == NULL) {
fprintf(stderr, "Error\n");
exit(1);
}
write_char('C', fp); // ヘッダの書き込み
write_char('A', fp);
write_char('P', fp);
write_char('H', fp);
write_char('E', fp);
write_char('S', fp);
write_char('U', fp);
write_char('A', fp);
write_int(exec->constant_pool_count, fp); // Constant_Pool_Sizeの書き込み
for (int i = 0; i < exec->constant_pool_count; ++i) { // Constant_Poolの書き込み
switch(exec->constant_pool[i].type) {
case CS_CONSTANT_INT: {
write_char(SVM_INT, fp);
write_int(exec->constant_pool[i].u.c_int, fp);
break;
}
case CS_CONSTANT_DOUBLE: {
write_char(SVM_DOUBLE, fp);
write_double(exec->constant_pool[i].u.c_double, fp);
break;
}
default: {
fprintf(stderr, "undefined constant type\n in disasm");
exit(1);
}
}
}
write_int(exec->global_variable_count, fp); // Global_Variable_Countの書き込み
for (int i = 0; i < exec->global_variable_count; ++i) { // Global_Variable_Typeの書き込み
switch(exec->global_variable[i].type->basic_type) {
case CS_BOOLEAN_TYPE:
case CS_INT_TYPE: {
write_char(SVM_INT, fp);
break;
}
case CS_DOUBLE_TYPE: {
write_char(SVM_DOUBLE, fp);
break;
}
default: {
fprintf(stderr, "No such type\n");
exit(1);
}
}
}
write_int(exec->code_size, fp); // Code_Sizeの書き込み
write_bytes(exec->code, exec->code_size, fp); // Codeの書き込み
int stack_size = count_stack_size(exec->code, exec->code_size); // Stack_Sizeの書き込み
write_int(stack_size, fp);
fclose(fp);
}
このコードで使っている,write_int, write_bytesなどの実装は以下の通り,
static void write_char(char c, FILE* fp) {
fwrite(&c, 1, 1, fp);
}
static void write_reverse(const void* pv, size_t size, FILE* fp) { // BigEndianで書き込み
char* p = (char*)pv;
for (int i = size - 1; i >= 0; --i) {
write_char(p[i], fp);
}
}
static void write_int(const uint32_t v, FILE* fp) {
write_reverse(&v, sizeof(uint32_t), fp);
}
static void write_double(const double dv, FILE *fp) {
write_reverse(&dv, sizeof(double), fp);
}
バイナリの確認
以下のソースファイルをもとにファイル生成してみる.int print(),print();に関して詳細は省く.
int print();
int j;
int i;
i = 4;
j = i = i + 5;
print();
ディスアセンブル結果は以下の通り
>./cgent tests/prog4.cs
(略)
push_int 0000
pop_static_int 0001
push_static_int 0001
push_int 0001
add_int
pop_static_int 0001
push_static_int 0001
pop_static_int 0000
push_function 0000
invoke
pop
生成されたファイルを確認してみる.
>hexdump -C ./a.csb
00000000 43 41 50 48 45 53 55 41 00 00 00 02 01 00 00 00 |CAPHESUA........|
00000010 04 01 00 00 00 05 00 00 00 02 01 01 00 00 00 1b |................|
00000020 01 00 00 09 00 01 07 00 01 01 00 01 0b 09 00 01 |................|
00000030 07 00 01 09 00 00 2b 00 00 2c 2a 00 00 00 04 |......+..,*....|
うまく生成できている.例えば,最初の8バイトにヘッダが入り,それに続く00 00 00 02は,定数が2つあることを示している.続く01 00 00 00 04は,定数の1つがint型で,値は0x00000004 = 4であることを示す.そして,その次の定数は5(0x0000000005)で,変数の数は2個(0x00000002),かつ両方int型(0x01)であることが分かる.そこからコードが27倍バイト(0x1b)続く.
ここまでの実装は,以下のコマンドで試すことができる
>git clone https://github.com/hiro4669/csua.git
>cd csua
>git branch begin_serialize origin/begin_serialize
>git checkout begin_serialize
>make
>cd comp
>./cgent ./tests/prog4.cs
>hexdump -C a.csb
00000000 43 41 50 48 45 53 55 41 00 00 00 02 01 00 00 00 |CAPHESUA........|
00000010 04 01 00 00 00 05 00 00 00 02 01 01 00 00 00 1b |................|
00000020 01 00 00 09 00 01 07 00 01 01 00 01 0b 09 00 01 |................|
00000030 07 00 01 09 00 00 2b 00 00 2c 2a 00 00 00 04 |......+..,*....|
0000003f
目次に戻る