最初に
本ドキュメントでは関数型プログラミングで見受けられるコードのパターンを記述する。
関数型プログラミングでは、関数自体を通常のオブジェクトと同じように、変数に格納したり、引数に渡したり、データ構造の一部にできることにより、命令型プログラミングと比較して簡潔なコード記述ができる効果が見込まれる。
本ドキュメントでは、関数型プログラミングの理論よりサンプルを提示することにより、読者に視覚的に効果を見せるよう努めている。
対象となる読者は以下の通りである。
-
Java言語による命令型/オブジェクト指向型プログラミングが書ける/読める
-
関数型プログラミングに興味がある
パターンは、命令型プログラミングの例として、Java言語での例を記載する。
Scala言語は、オブジェクト指向プログラミングと関数型プログラミングを組み合わせた設計思想として作られている。
一方で、Java言語は、Project Lambdaと呼ばれるプロジェクトにより、それまでのJava言語を拡張する形で実装がされ、Java SEバージョン8により正式にJava言語に取り込まれた。
Scala言語, Java言語, で、2つの整数値を乗数を算出する関数を比べてみる。
Java
import java.util.function.IntBinaryOperator;
IntBinaryOperator intMultiplier = (a, b) -> a * b;
Scala
val intMultiplier: (Int, Int) => Int = (a, b) => a * b;
ES
const intMultiplier = (a, b) => a * b
いくつか類似している部分とそうでない部分があることに気づくであろう。まず、関数は、aとbの2つの引数を渡し、それを乗算したものを返している部分の記述はJava言語とScala言語で共通している。この表記はラムダ式と呼ばれる。
Java言語では関数はIntBinaryOperatorというクラスになっている。Scalaでは整数型Intの引数を2つ取り、関数型Intを返すということがクラス( (Int, Int) => Int )であることが分かる。
Java言語におけるクラスIntBinaryOperatorは、SAM(Single Abstract
Method)インターフェイスと呼ばれる単一の抽象メソッドを持つインターフェイスである。Java言語では、このSAMインターフェイスに対して、上記のような省略したコードを記述できる。上記のコードは実際には以下のコードを同等である。
IntBinaryOperator intMultiplier = new IntBinaryOperator() {
@Override
public int applyAsInt(int a, int b) {
return a * b;
}
};
一方で、Scala言語はクラスが関数の入出力を分かりやすく示したクラスであるが、Scala言語でも実際はFunction2[Int, Int, Int]というクラスのエイリアスになっている。そのため、以下のような記載もできる。
val intMultiplier: Function2[Int, Int, Int] = (a, b) => a * b;
Scala言語の場合は、関数へのクラスが決められているために、変数intMultiplierの型を明示しなくてもよい。(ただし、この例だと代わりに引数(a, b)への型を明示する必要がある)
val intMultiplier = (a: Int, b: Int) => a * b;
Java言語の場合は、必ず使用するSAMインターフェイスを明示する必要があるが、逆にメリットとしては、どのようなSAMインターフェイスに対してもラムダ式で記載できる点にある。
なお、Scala言語でもSAMインターフェイスに対するラムダ式を、Scala 2.12で正式サポートされている。
なお、本ドキュメントでは関数型プログラミングに関する部分に力点をおいていて、あまり言語の構文などは詳しくは書かない。これは読者自身で調査をしていただきたいと考えている。
パターン
パターンをプログラムで記述する際に、list 変数を使用するが、これは次の通りの変数定義が事前に行われている前提とする。
List<String> list = Arrays.asList("apple", "orange", "grape");
val list: Seq[String] = Seq("apple", "orange", "grape")
繰り返し
繰り返しは基本的なパターンではあるが、これにも関数型プログラミングの特徴が存在する。
最初に命令型プログラミングでの例を示す。
for (String s : list)
System.out.println(s);
拡張for文を使用しているが、それ以外は特筆すべき点はない。
これを関数型プログラミングであるScalaで書くと下記のようになる。最初は少し冗長に書く。
def output(s: String) = {
println(s)
}
list.foreach(output)
1~3行目でoutput関数を定義している。これは、引数sを受け取り、その内容を標準出力に印字する。
4行目ではこのout関数をforeachメソッドの引数として渡している。このことにより、list変数内のひとつひとつの要素が順にoutput関数の引数sに渡されて実行がされる。
実際にはこのように関数を分けて定義は行わず、以下のようにforeachメソッドの引数に関数定義を直接記述する。
list.foreach { s: String => println(s) }
Scalaに関しては、この記述は以下のようにfor表記でも記述が出来る。Scalaのfor表記は、Javaの拡張for文と見た目は似ているが、実際は異なり、この例でのfor表記は上記のforeachを使用したものに変換がされる。
for (s <- list)
println(s)
次にJava言語での関数型プログラミングの例を示す。まずはScala言語の例のように冗長な例から示す。
Consumer<String> output = s -> System.out.println(s);
list.stream().forEach(output);
この1行目の書き方はラムダ式を使用した書き方で、実際は下記のようなコードと同等となる。
Consumer<String> output = new Consumer<String>() {
public void accept(String s) {
System.out.println(s);
}
};
Java言語においても、Scala言語と同様に、一般的には下記のように記述を行う。
list.stream().forEach(s -> System.out.println(s));
Java言語ではメソッド参照という書き方があり、以下の様な書き方もできる。
list.stream().forEach(System.out::println);
同様な記述はScalaでも可能であるが、Scalaの場合はprintln関数そのものを渡している。
list.foreach(println)
マップ
リスト内のデータ一つ一つを変換し、別のデータを作成するという例に移る。
以下はlist 変数内の各項目を、文字列の長さに変換する命令型プログラミングでの例である。
List<Integer> eachLength = new ArrayList<>();
for (String s : list)
eachLength.add(s.length());
命令型プログラミングでは、最初に文字列の長さが入った空のリスト( eachLength )を作成する。(1行目)そして、順に文字列ひとつひとつを長さに変換し、eachLength に加えていく。(2~3行目)
次に関数型プログラミングでの例を示す。
val eachLength: Seq[Int] = list.map(s => s.length())
関数型プログラミングでは、リストのmap関数に、変換用の関数を渡すことで、リストそのものの変換を実現している。
Scala言語の場合は、これをfor表記でも記述できる。記述は繰り返しで示した例を似ているが、yieldというキーワードが付いている。このキーワードを付けることで、上記のmap関数で記述した内容と同じ動きとなる。
val eachLength: Seq[Int] = for (s <- list) yield s.length()
次に、Java言語での関数型プログラミングの例を示す。
List<Integer> eachLength =
list.stream().map(s -> s.length()).collect(Collectors.toList());
Scala言語のmap関数を使用した例に似ているが、リストを一旦ストリームにしたあと、再度リストに戻しているために冗長にみえる。
メソッド参照を使用した場合は以下のようになる。
List<Integer> eachLength = list.stream().map(String::length).collect(Collectors.toList());
合計
リストの文字列の長さの合計を算出する例を示す。Scala言語、Java言語ともに合計を算出する関数が用意されているが、最初はこれらを使用しない例から始める。
まずは命令型プログラミングでの例を示す。ここでは、先ほど使用したeachLength変数を再利用する。
int summary = 0;
for (int length : eachLength)
summary += length;
命令型プログラミングでは、最初に合計値を0で初期化した変数summaryを用意し、それに各文字列の長さの値を加えていく。
次に関数型プログラミングでの例を示す。
val summary = eachLength.reduceLeft((x, y) => x + y)
このreduceLeft関数では、まず、eachLength変数のリストに格納された最初(0番目)と次(1番目)の項目値を足し算をする。次に、その足し算の結果値と、その次(2番目)の項目値の足し算をする。同様に3番目以降の値も足し算をeachLength変数のリストの最後まで繰り返し、最後の足し算の合計値を返す。
なお、Scala言語では次のような書き方もできる。これは左の’_’
(アンダースコア)が上記のx、右の’_’
(アンダースコア)が上記のyを表している。
val summary = eachLength.reduceLeft(_ + _)
次に、Java言語での関数型プログラミングの例を示す。
Integer summary = eachLength.stream().reduce(0, (a, b) -> a + b);
Scala言語の例によく似ているが、reduceメソッドの第一引数に0という数値を渡している違いがある。そして、上記のコードでは分からないが、この例のreduceメソッドの内部は必ずしも足し算をeachLength変数のリストの最初の項目値から順に足し算をするわけではないという点に注意が必要である。
たとえば、2, 5, 7, 3という順のリストがあったとする。Scala言語の例では必ず以下の計算が行われる。
((2 + 5) + 7) + 3
ところが、Java言語の例では以下のように最初の項目から順に計算が行われない場合がある。
((0 + 2) + 5) + ((0 + 7) + 3)
Java言語の場合は、順序が最初から行われないことに加え、最初に足し算が発生するときに必ず0を加えている。
これは数学的には単位元が存在すること、結合律を満たすことを意味し、この2つを満たすことをモノイドという。
最初の項目から順に計算が行われないのがどういうケースで発生するかというと、これは並列計算を実施するときに発生する。並列計算により、各プロセッサーに分散し計算を効率化することができる。
実はScala言語でもreduceLeftメソッドではなくreduceメソッドを使用するとJava言語のように並列計算に対応ができる。
val summary = eachLength.reduce(_ + _)
また、foldメソッドを使用すれば、初期値を与えることも出来る。
val summary = eachLength.fold(0)(_ + _)
さて、合計値を計算する方法だが、これはScala言語、Java言語共に特化した記述方法があり、最後にその記述を紹介する。
Scala言語は名前そのままのsumメソッドが準備されている。
val summary = eachLength.sum
Java言語の場合は、以下の2つの方法がある。
int summary = list.stream().mapToInt(String::length).sum();
この方法は、mapToIntメソッドで、IntStreamというint型に特化したストリームに変換することで実現している。
Integer summary4 = list.stream().collect(Collectors.summingInt(String::length));
こちらの方法は、文字列の長さを計算したものを順次合計するやり方である。
エラー処理
ここではエラー処理を題材にする。ここではエラー処理ということを広義に捉え、エラーがない状態とある状態を持てることをエラー処理と考え、紹介する。
ヌル
C言語に影響を受けた言語は、変数にオブジェクトがアサインされていない状態のとき、ヌル(null)値が格納される。
ヌル値の問題点は、変数値がヌルが許されるかどうかがをドキュメント以外では判別できず、ヌル値のままその変数を使用しようとするとNullPointerExceptionが発生することである。
関数型プログラミングでは、ヌルは原則使用せず、以下のようなクラスを使用し、解決を行っている。
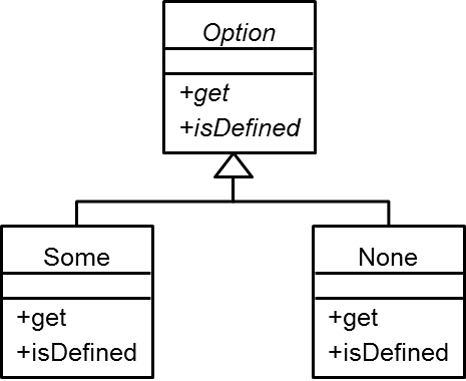
少し簡略したクラス図だが、抽象クラスOptionがあり、そこに抽象メソッドgetと抽象メソッドisDefinedが準備されている。(もちろん実際にはもっと多くのメソッドは存在する)その派生クラスとして、SomeクラスとNoneクラスが定義されていて、Someクラスでは実際の値が入った状態、Noneクラスは値がない状態を表す。getメソッドはSomeクラスでは対象の値が返るが、Noneクラスでは例外が発生する。isDefinedメソッドはSomeクラスではtrue、Noneクラスではfalseが返る。
これにより、まずOptionクラスの変数はヌル値になる可能性があることが明確に分かる。そして、その可能性がある場合は、以下のようにif文で分岐が出来る。
val valueOption: Option[T] = .....
if(valueOption.isDefined) {
val value: T = valueOption.get
// valueで何かをする
}
型TはOption(Optional)型の値の型である。
Javaでもほぼ同様の書き方ができる。JavaではSomeクラスやNoneクラスといった具象クラスを分ける実装はしていなく、Optionalクラス自身の内部に成功と失敗時の状態を持っている。
Optional<T> valueOption = .....
if (valueOption.isPresent()) {
T value = valueOption.get();
// valueで何かをする
}
おそらくここまでの説明では、Option(Optional)クラスは関数型プログラミングというよりオブジェクト指向であるという印象があるのではないかと思う。
まずは、Option(Optional)クラスにおけるマップを示す。
Opition(Optional)クラスにはマップ(map)メソッドが存在する。(上記のクラス図にはマップ・メソッドは省略している)
val textOption: Option[String] = .....
val lengthOption: Option[Int] = textOption.map(s => s.length())
Optional<String> textOption = .....
Optional<Integer> lengthOption = textOption.map(s -> s.length());
上記はマップ・メソッドではString型のオブジェクトを含む可能性があるtextOption変数を、String型オブジェクトの長さを含む可能性があるlengthOption変数に変換をしている。つまり、textOption変数のisDefined(isPresent)メソッドがtrueを返せば、lengthOption変数もtrueを返し、textOption変数のisDefined(isPresent)メソッドがfalseを返せば、lengthOption変数もfalseを返す。
Scalaの場合は、以下のfor表記でもマップ・メソッドと同等の書き方ができる。
val textOption: Option[String] = .....
val lengthOption: Option[Int] = for(s <- textOption) yield s.length()
また、Scalaの場合にはOptionクラスにもforeachメソッドが存在する。
textOption.foreach(println)
この例では、textOption変数の実体がSomeクラスであれば、つまり、中身のデータがヌルでないならば、中身のデータを印字し、Noneクラスであれば、何も実行しない(印字がされない)。
Javaの場合はメソッド名がifPresentという名称で同じことが実行できる。
textOption.ifPresent(System.out::println);
Scalaのforeachメソッドの例も、以下のfor表記で同等の書き方が可能である。
for(s <- textOption) println(s)
ここまで、Option(Optional)クラスにもリストと同じようにforeachメソッドやマップ・メソッドに相当するものがあることを示してきた。
次に関数型プログラミングを語る上では、もう一つの重要なflatMapメソッドを紹介する。(上記のクラス図にはflatMapメソッドは省略している)
ここでの例は、コマンドライン引数を解析し、コマンドライン引数に含まれるユーザーID、パスワードを元に対象サーバーにアクセスをする。(対象サーバーは、DBサーバーやsshでのLinuxサーバーなどが想定されるが、ここではあくまで例のために具体的なところまでは言及しない)
あらかじめ以下の3つのメソッドが定義されている。
それぞれがOption(Optional)クラスのインスタンスの戻り値であるのは、これらが値を持たない(持てない)可能性があるからである。getUserId/getPasswordメソッドは、適切な引数が渡されていない場合は値が持てないし、connectはユーザーIDやパスワードが誤っている場合や、サーバーに接続できない場合は値が持てない。
def getUserId(args: Array[String]): Option[String]
def getPassword(args: Array[String]): Option[String]
def connect(user: String, password: String): Option[Connection]
Optional<String> getUserId(String[] args)
Optional<String> getPassword(String[] args)
Optional<Connection> connect(String userId, String password)
目指したい作成対象メソッドは以下の型のメソッドである。
def connect(args: Array[String]): Option[Connection]
Optional<Connection> connect(String[] args)
まずはJavaの命令型プログラミングでの例を示す。
Optional<Connection> connect(String[] args) {
Optional<String> userIdOption = getUserId(args);
Optional<String> passwordOption = getPassword(args);
if (userIdOption.isPresent() && passwordOption.isPresent()) {
String userId = userIdOption.get();
String password = passwordOption.get();
return connect(userId, password);
} else
return Optional.empty();
}
難易度は高くないため、説明は不要かと思う。おそらくこれでも十分分かりやすいと思うかもしれない。
さて、flatMapメソッドの説明に移る。
型Option[A]である変数optionAと、クラスAを引数とし、Option[B]
(Optional<B>)を返すメソッドactionが存在するとする。
val optionB: Option[B] = optionA.flatMap { a => action(a) }
Optional<B> optionB = optionA.flatMap(a -> action(a)};
これは、optionAがヌル値ではない値が入った場合、かつ、その値でaction(a)を実行した結果がさらにヌル値ではない値が入った状態であるときにのみ、optionBはヌル値ではない値が入った状態になる。
つまり、以下と同じ動きをする。
val optionB: Option[B] = if(optionA.isDefined) action(optionA.get) else None
Optional<B> optionB = optionA.isPresent() ? action(optionA.get()) : Optional.empty();
表にすると以下になる。下記でtrue/falseとはOption(Optional)のインスタンスのisDefined(isPresent)の結果がtrue/falseになることである。
| optionA | action(a)の結果 | flatMapの結果(optionB)
|--------------+----------------------+----------------|
| true | true | true |
| true | false | false |
| false | 呼ばれない | false |
このflatMapメソッドを使用したconnectメソッドの実装は下記のとおりとなる。
def connect(args: Array[String]): Option[Connection] =
getUserId(args).flatMap { userId =>
getPassword(args).flatMap { password => connect(userId, password)
}
}
Optional<Connection> connect(String[] args) {
return getUserId(args).flatMap(userId ->
getPassword(args).flatMap(password -> connect(userId, password)));
}
これから見て分かる通り、命令型プログラミングでの条件分岐がこの例ではflatMapメソッドに吸収されている。
これだけだとむしろ複雑になったように見えるかもしれない。これをScala言語のfor表記で記載すると下記のようになる。
def connect(args: Array[String]): Option[Connection] =
for(userId <- getUserId(args);
password <- getPassword(args);
connection <- connect(userId, password))
yield connection
この表記では、Option(Optional)クラスの中身の値を取り出し、その値で処理を順次実施しているイメージが掴みやすいのではなかろうか。
なお、このfor表記は、正確には次のように変換される。
def connect3(args: Array[String]): Option[Connection] =
getUserId(args).flatMap { userId =>
getPassword(args).
flatMap { password =>
connect(userId, password).map { conn =>
conn
}
}
}
例外
例外に関してはScala言語のパターンのみになる。Java言語でも例外に関するライブラリをOSSで作成している例もあるが、現時点でメジャーではないために説明はしない。(https://github.com/jasongoodwin/better-java-monads)
まず、Java言語での例外処理の話から始める。Java言語ではtry/catchで例外処理を実施する。
try {
// 例外発生が伴う可能性がある処理
.....
} catch(....) {
// 例外発生時の対応処理
....
}
Scala言語でも同様のtry/catchで記述が可能であるが、ここでは他の関数型プログラミングらしい方法を紹介する。
Scala言語にはTryクラスが準備されている。Tが大文字である点に注意してほしい。Tryクラスは以下のような構造である。
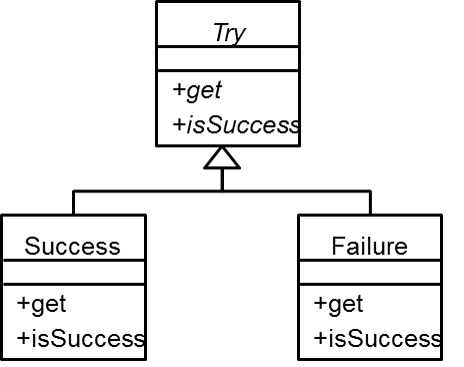
まず一見にしてTryクラスがOptionクラスに類似していることが分かると思う。成功(Success)と失敗(Failure)のクラスが分かれているのは、OptionクラスのSomeクラス/Noneクラスがあるのと類似している。
さて、Tryクラスの使い方だが、これにはTry(コンパニオン)オブジェクトのapplyメソッドを使用する。Java言語風な言い方では、静的メソッドに近い。(違いがScala言語ではシングルトン・オブジェクトとなる)
val result = Try.apply {
// 例外発生が伴う可能性がある処理
.....
}
まず、applyメソッドに失敗する可能性がある処理を渡している。また、その結果をresult変数で返している。result変数には、処理の成功/失敗にしたがい(Tryクラスから派生した)SuccessクラスかFailureクラスのインスタンスが格納される。
Scalaの(コンパニオン)オブジェクトのapplyメソッドは省略することが許されているために、下記のように書くこともできる。
val result = Try {
// 例外発生が伴う可能性がある処理
.....
}
TryクラスもOptionクラスと同様に成功した場合は値を取り出すことができる。
val result: Try[T] = .....
if(result.isSuccess) {
val value: T = result.get
// valueで何かをする
}
Option(Optional)クラスで説明した事項はTryクラスでも同様にできる。以下はOption(Optional)クラスと比較しながら見てほしい。
val textTry: Try[String] = .....
val lengthTry: Try[Int] = textTry.map(s => s.length())
val textTry: Try[String] = .....
val lengthTry: Try[Int] = for(s <- textTry) yield s.length()
textTry.foreach(println)
for(s <- textTry) println(s)
def getUserId(args: Array[String]): Try[String] = .....
def getPassword(args: Array[String]): Try[String] = .....
def connect(user: String, password: String): Try[Connection] = .....
def connect(args: Array[String]): Try[Connection] =
getUserId(args).flatMap { userId =>
getPassword(args).flatMap { password => connect(userId, password) }
}
def connect(args: Array[String]): Try[Connection] =
for (
userId <- getUserId(args);
password <- getPassword(args);
connection <- connect(userId, password)
) yield connection
Option(Optional)クラスと同じ記述ができるのが分かると思う。
Option(Optional)クラスのNoneは、TryクラスにおけるFailureクラスに相当する、つまり、エラー処理における失敗という状態に相当すると考えれば、共通点があることは納得できるのではないかと思う。
クラス定義
関数型プログラミングではオブジェクトはImmutable(不変)である必要がある。
一方、オブジェクト指向プログラミングにおいてはオブジェクトの内部を変化させることが基本となる。これはMutable(可変)といわれる。
Java SE(Standard Edition)の中で、Mutableなクラスの例を示す。
Stack<String> stack = new Stack<>();
stack.push("apple");
stack.push("orange");
stack.push("grape");
stack.pop();
読者はStackクラスに関して既知であると想定し、Stackクラスそのものの説明はしない。この例の1行目から5行目までの全てのstack変数は同一のインスタンスを参照している。4行目が終わった時点では、スタックには上からgrape、orange、apppleが積まれている。5行目ではその一番上から値を削除するため、5行目実行後はorange、apppleになる。
Java SEの多くのクラスはこのようなMutableなクラスである。一方で、Java
SEも一部Immutableなクラスがある。典型的にはStringクラスがImmutableクラスである。
String s = "abcde";
String t = s.substring(2);
1行目実行後の変数sと2行目実行後の変数tはそれぞれ”abcde”、”cde”の文字列だが、重要なのは2つは異なるStringインスタンスを参照している点と、変数s
は2行目の実行後も”abcde”のままであるという点である。
Immutableなクラスは自分自身のインスタンスの状態を変えるのではなく、状態ごとに別のインスタンスを生成する。
先ほどのStackの例をScala言語で実装すると、違いが明確に分かると思う。(なお、Scala言語でのStackクラスは現在は使用が推奨されず、Listクラスを代替として使うことが推奨されるが、説明のため、Stackクラスを使用する)
import scala.collection.immutable.Stack
val stack = new Stack[String]()
stack.push("apple")
stack.push("orange")
stack.push("grape")
stack.pop
5行目を実行した後のstack変数が指すインスタンスには何が入っているだろうか。Javaのように3つ全ての文字列が積まれているように思うかもしれないが、Immutableなので、正解は5行目が終わっても空のままである。(このため、6行目にpopメソッドを実行した場合は、スタックが空のために、popする対象がない旨の例外が送出される)
では、Immutableなクラスではどうすればよいのか?以下がその例である。
import scala.collection.immutable.Stack
val stack: Stack[String] = new Stack[String]()
val stack1: Stack[String] = stack.push("apple")
val stack2: Stack[String] = stack1.push("orange")
val stack3: Stack[String] = stack2.push("grape")
val (value: String, stack4: Stack[String]) = stack3.pop2
興味深いのは、Java言語ではpushメソッドでインスタンスの状態が変わる一方、Scala言語では状態が変わるのではなく、状態が変わったスタックのインスタンスを返す。
また、6行目のpopメソッド相当のpop2メソッドも注目すべき点で、一番上に積まれていた値と共に、その値を取り出した後のスタックも戻り値で返している。
このように関数型プログラミングでは、Immutableなクラスを実現するために、状態を変えたい場合、自身のインスタンスの状態を変えるのではなく、インスタンスの状態を変えた新しいインスタンスを返す。これにより、インスタンスの状態に一貫性を持たせることを可能にしている。
なお、先ほどの例では、stack変数がstack,
stack1~4を多く出てきて、コードが汚いと感じる方もいるかもしれない。関数型プログラミングにはこのためのStateモナドというものが存在する。ここではコードの説明はしないが、変数が多く出てこない書き方が出来る点だけ頭に留めておいてほしい。
import scalaz._, Scalaz._
import scala.collection.immutable.Stack
// Stateモナド用のpush、pop定義
def push[T](t: T): State[Stack[T], Unit] =
State { stack: Stack[T] => (stack.push(t), Unit) }
def pop[T](): State[Stack[T], T] =
State { stack: Stack[T] => stack.pop2.swap }
// アクションの定義。stack変数が出てこない点がポイント
val actions: State[Stack[String], String] =
for(
_ <- push("apple");
_ <- push("orange");
_ <- push("grape");
v <- pop[String]) yield v
val (stack: Stack[String], value: String) = actions(new Stack[String]())
繰り返し(再び)
命令型プログラミングでは通常繰り返しにはwhile文/do-while文のような繰り返し構文を使用する。一方、関数型プログラミングでは、while文/do-while文を使用することは推奨されない。
その理由のひとつとしては、while文/do-while文はImmutableな変数値を持つ可能性が高くなるためである。Java言語はもちろんScala言語でもwhile文/do-while文は戻り値を持たない。(正確にはScala言語はUnit型というそれ自体に意味を持たない値を返す)したがって、データをループにより加工する場合では、何らかのMutableな変数値を持つ必要がある。関数型言語ではMutableな変数値を持つことは可読性を低めるBad
Practiceの1つと看做される。
もう一つの理由としては関数型プログラミングにおいては、while文/do-while文は代替のコーディングが準備されているからである。命令型プログラミングとは出自が異なる関数型プログラミングでは、while文/do-while文以外の方法で繰り返しをコーディングする。今回はその方法を紹介する。
再帰呼出し
再帰呼出しに関しては、Scalaのみになり、Javaでは対象外となる。再帰呼出しそのものは命令型プログラミングでも古くから存在するが、Scalaでは末尾呼出し最適化という機能が働くことが大きく異なる点である。
まずは以前繰り返しを説明した合計値を取得する例から説明する。以下は再掲である。
int summary = 0;
for (int length : eachLength)
summary += length;
これと同様の合計値を返す再帰呼出しの例の最初の版は以下になる。
def sum(eachLength: Seq[Int]): Int =
eachLength match {
case Seq(len) => len
case Seq() => 0
case Seq(len, remains@_*) => len + sum(remains)
}
このコードは実は大きな問題がある。eachLengthがたとえば10,000個の要素がある場合、StackOverflowErrorエラーで失敗をする。これは関数呼出し時に有限の領域であるスタック領域を使用してしまうために、繰り返し関数が呼び出させた場合、このスタック領域を使い果たしてしまうためである。これはJava言語でも一般的に起こる事象であるが、Scalaのような一部の関数型言語では特定の条件では末尾呼出し最適化と呼ばれる機構が機能し、再帰呼出しを回避する。
まずは先ほどの例が末尾呼出し最適化が機能していないことを確認する。
import scala.annotation.tailrec
@tailrec
def sum(eachLength: Seq[Int]): Int =
eachLength match {
case Seq(len) => len
case Seq() => 0
case Seq(len, remains@_*) => len + sum(remains)
}
このコードをコンパイルすると以下のエラーが発生する。これは再帰呼出しが末尾にないために最適化ができないということを示している。実際に上の例の7行目はsum関数を再帰呼び出した後に加算が行われていて、最末尾に再帰呼出しが行われていないことが分かる。
could not optimize @tailrec annotated method sum: it contains a recursive
call not in tail positionimport scala.annotation.tailrec
では、末尾再帰最適化の実施をするためにはどういう実装にすればよいか。先ほどの再帰呼び出しをした後、加算を実施していたがその順序を変えればよい。具体的には以下のようになる。
import scala.annotation.tailrec
@tailrec
def sum(eachLength: Seq[Int], value: Int = 0): Int =
eachLength match {
case Seq(len) => value + len
case Seq() => value
case Seq(len, remains@_*) => sum(remains, value + len)
}
この例ではパラメータvalueが一つ増えている。ここに合計値を常に渡すようにしているが、このパラメータは隠したいと思うかもしれない。これには以下のように関数を隠すことで実現できる。
import scala.annotation.tailrec
def sum(eachLength: Seq[Int]) = {
@tailrec
def _sum(_eachLength: Seq[Int], value: Int): Int =
_eachLength match {
case Seq(len) => value + len
case Seq() => value
case Seq(len, remains@_*) => _sum(remains, value + len)
}
_sum(eachLength, 0)
}
fold関数
fold関数は以前説明をしたが、ここでは少し視点を変えてみる。
再帰呼び出しにおける例を抽象化した場合どうなるでしょうか。まず、初期値を渡す必要があった。最後の例ではそれは隠蔽させたが、ここの例では復活させる。また、合計値と、配列(eachLength)の要素を元に新しい合計値を算出するロジックが必要となった。
まず第一版は以下の通りである。これを2つ前のコードと比べてほしい。変化点は本質的なものは2つ(のみ)である。1つは関数名をsumからrepeatに変えた。もうひとつは加算の関数(+)を、引数に渡した関数で処理をするようにした。小さいものとしてはvalueパラメータのデフォルトパタメータ(0)をなくした。
// 関数定義
def repeat(list: Seq[Int], value: Int)(f: (Int, Int) => Int): Int = {
list match {
case Seq(elemValue) => f(elemValue, value)
case Seq() => value
case Seq(elemValue, remains@_*) =>
repeat(remains, f(elemValue, value))(f)
}
}
// 呼出し例
repeat(eachLength, 0) { _ + _ }
これはIntに特化しているが型をさらに抽象化する。
// 関数定義
def repeat[A, B](list: Seq[A], value: B)(f: (A, B) => B): B = {
list match {
case Seq(elemValue) => f(elemValue, value)
case Seq() => value
case Seq(elemValue, remains@_*) => repeat(remains, f(elemValue, value))(f)
}
}
この例をみて賢明な方は気づいたかもしれないが、これはfold関数と非常に類似していることが分かる。
// Seq#foldLeft関数の定義
def foldLeft[B](z: B)(op: (B, A) => B): B
// 呼出し例(再掲)
val summary = eachLength.fold(0)(_ + _)
ここで特に伝えたいポイントは、fold関数は繰り返しを汎用的に実装できるテクニックの1つである点である。
おそらく、この説明だけだと、単に説明だけのトリック、つまり、応用性があまりないと感じるかもしれないが、fold/reduce関数は実は大変広い。
CSV解析ツールの例を考えてみよう。以下はScala言語でCSVファイル解析の例である。簡単のために、ダブルクオート文字(“)の考慮などはされていない。
以下はそのサンプルである。1行目はCSVのヘッダで2行目以降が実データになっている。
a, b, c
1, 2, 3
4, 5, 6
まずはCSV用の型を定義する。CSVのヘッダ用CsvHeaderクラス、CSVのボディー用CsvLineクラスおよびCSV(そのもの)を表すCsvクラスを定義する。
object CsvHeader {
def parse(line: String): CsvHeader = {
CsvHeader(line.split(',').map(_.trim).toSeq)
}
}
case class CsvHeader(colName: Seq[String])
case class CsvLine(items: Seq[String])
case class Csv(header: CsvHeader, lines: Seq[CsvLine] = Seq()) {
def addLine(line: String) =
Csv(header, lines :+ CsvLine(line.split(',').map(_.trim)))
}
全行をStringのリストの形で取得したものをCsvに変換する例は以下である。
val lines = ....;
val Some(csv) = lines.foldLeft[Option[Csv]](None) {
case (None, line) =>
Some(Csv(CsvHeader.parse(line)))
case (Some(csv), line) =>
Some(csv.addLine(line))
}
この例のポイントは、1行目のヘッダを解析済みかどうかをOptionがSomeかNoneかで判断している。Optionは最初はNoneで渡されるが、1行目のヘッダを渡された時点で、Csv型を包んだSomeになる。つまり、状態管理をしている。このようにfold関数は、リストや配列などのひとつひとつの要素に対して状態を変化させながら結果を出す場合に使用できる。
この状態を持ちながら繰り返しが行えることは非常に重要で、これにより多くの繰り返し処理を、再帰呼出しではなく、fold関数により実現できる。関数プログラミングでは、再帰呼出しで実装を実現する前に、fold関数で実装を検討する方が望ましい。再帰呼出しは、その度に関数定義が必要なため、可読性が低くなることが多い。
ただし、fold関数によりむしろ可読性が悪くなったり、あるいは、パフォーマンスが悪くなる場合は、再帰呼出しを使用してほしい。
なお、先に説明したサンプルは(先ほどの例より若干難しくみえるかもしれないが)以下のようにももう少し短く書ける。
val lines = ....;
val Some(csv) = lines.foldLeft[Option[Csv]](None) {
case (optCsv, line) =>
optCsv.map(_.addLine(line)).orElse(Some(Csv(CsvHeader.parse(line))))
}
これまでのfold関数の例は、Scala言語だったが、Java言語では以下のようになる。ここでは説明は省略するが、ほぼScala言語と同様に記述している。
public class CsvHeader {
private List<String> colNames;
public CsvHeader(List<String> colNames) {
this.colNames = colNames;
}
....
}
public class CsvLine {
private List<String> items;
public CsvLine(List<String> items) {
this.items = items;
}
....
}
public class Csv {
private CsvHeader header;
private List<CsvLine> lines;
public Csv(CsvHeader header, List<CsvLine> lines) {
this.header = header;
this.lines = lines;
}
public Csv(CsvHeader header) {
this.header = header;
this.lines = new ArrayList<CsvLine>();
}
public Csv addLine(String line) {
return addLine(new CsvLine(parseLine(line)));
}
public Csv addLine(CsvLine line) {
List<CsvLine> lines = new ArrayList<CsvLine>(this.lines);
lines.add(line);
return new Csv(header, lines);
}
....
}
List<String> parseLine(String line) {
return Arrays.
stream(line.split(",")).
map(item -> item.trim()).collect(Collectors.toList());
}
List<String> lines = ....;
Csv result = lines.stream().reduce(
Optional.<Csv>empty(),
(optCsv, line) ->
Optional.of(optCsv.map(
csv -> csv.addLine(line)).orElse(
new Csv(new CsvHeader(parseLine(line))))),
(optCsv1, optCsv2) -> {throw new RuntimeException();}).get();
最後に
本ドキュメントでは私の経験から関数型プログラミングのパターンを書いた。関数型プログラミングでは、命令型プログラミングとは異なる書き方が多く可能なことが発見できたと思う。命令型プログラミングしか経験がない場合は、関数型プログラミングは分かりにくいと感じるものもあるかもしれないが、何度かコードを書いたり読んだりすることで、関数型プログラミングは多くの抽象化機構があり、その抽象化を理解すれば、関数型プログラミングの理解者には非常に分かりやすいコードになる。
このドキュメントに記載したパターンはその抽象化の基本的なものであるが、是非本ドキュメントを、関数型プログラミングの理解の入り口にしていただくと幸いである。
Hirofumi Arimoto
Java, Scala, JavaScriptや、機械学習に興味あり
実際の開発での知見を可能な限り記事にしたいと思っている