はじめに
去年、子豚の出産を検知する装置を作成して、知り合いの畜産農家の方に使ってもらっていたのですが、Lobeで作成した画像認識の精度がいまいちなような感じがしたので、教科書に載っている内容を参考に、自分で学習モデルを作ってみました。
私の場合、子豚がいるかいないかの分類ですが、別の画像があれば同じようにモデル作成ができると思うので、参考にしていただければ幸いです。
やったこと
1.「子豚あり」「子豚なし」の画像をフォルダごとに分割する
2.画像を読み込んで、画像データと教師ラベルのリストを作成する
3.学習用とテスト用に分割する
4.学習用データを使ってモデルに学習させる
5.テスト用データを使ってモデルを評価する
1. 「子豚あり」「子豚なし」の画像をフォルダごとに分割する
画像はあらかじめ、現地から収集したものから作っています。
元の画像に対して、グレースケール処理とマスク処理することで学習用の画像を作成します。

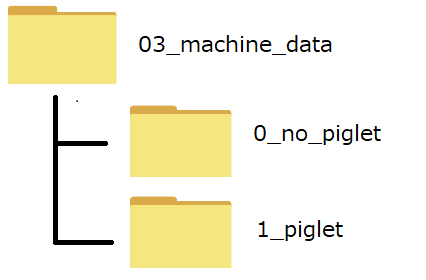
作成したファイルを以下のような構成のフォルダの配下に格納します。
「0_no_piglet」の下に子豚なしの画像を、「1_piglet」の下には子豚ありの画像を格納しています。
2.画像を読み込んで、画像データと教師ラベルのリストを作成する
ファイルを一つずつ読み込んで、画像データをXのリストに、フォルダ名を基にした教師ラベルをyのリストに格納します。
from pathlib import Path
from PIL import Image
import numpy as np
# ファイルのパスを設定
path_dir = "C:\\XXXXXXXXXXXXXX\\03_machine_data\\"
p = Path(path_dir)
# 分類するフォルダと教師ラベルを設定
cls_dic = {'0_no_piglet':0,'1_piglet':1}
X = []
y = []
for name, cls in cls_dic.items():
child = p / name
for img in child.glob('*.jpg'):
# 画像データをリストに追加
X.append(np.array(Image.open(img)).flatten())
# 教師ラベルをリストに追加
y.append(cls)
3.学習用とテスト用に分割する
集めたデータを学習用とテスト用意分割します。
全体の30%をテストデータにしようと思ったので、test_size=0.3としています。
random_state=123はいくつでもいいんですが、再現性を出すために適当な値に固定しています。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
4.学習用データを使って学習する
from sklearn.ensemble import RandomForestClassifier
# 学習データを学習する
model = RandomForestClassifier(random_state=123)
model.fit(X_train, y_train)
5.テスト用データを使ってモデルを評価する
from sklearn.metrics import classification_report
# テストデータを判定する
pred = model.predict(X_test)
# 判定結果を教師ラベルに付き合わせて結果を出力する
print(classification_report(y_test, pred))
precision recall f1-score support
0 0.73 0.88 0.80 25
1 0.77 0.56 0.65 18
accuracy 0.74 43
macro avg 0.75 0.72 0.72 43
weighted avg 0.75 0.74 0.74 43
出力された結果がこちらです。
子豚なしの再現率が少し高くて(0.88)、子豚ありの再現率が少し低いです(0.56)。
つまり、子豚が生まれても見逃すことが多いってことなので、これはよくないです。
おわりに
子豚がいるかいないかを判別するだけのモデルではありますが、割と簡単にモデル作成して評価することができました。
やってみて、画像は不要な部分をマスクするのではなく、必要な部分を抜き出す形の方が、処理をするデータ量が少なくていいんじゃないかと思い始めたので、そのうえで、学習データを増やして精度が改善するか、色々試してみようと思います。
今回は教科書に載っている方法で簡単に試してみましたが、より精度の出そうな深層学習にも興味があるので、そっちにも挑戦してみたいと思ってます。
追記
画像は不要な部分をマスクするのではなく、必要な部分を抜き出す形の方が、よさそうだなと思いさっそっく試してみました。
結果が少し良くなりました。やはり余計な情報は少ない方が精度出やすいのかもしれません。
precision recall f1-score support
0 0.73 0.88 0.80 25
1 0.77 0.56 0.65 18
accuracy 0.74 43
macro avg 0.75 0.72 0.72 43
weighted avg 0.75 0.74 0.74 43
precision recall f1-score support
0 0.78 0.84 0.81 25
1 0.75 0.67 0.71 18
accuracy 0.77 43
macro avg 0.76 0.75 0.76 43
weighted avg 0.77 0.77 0.77 43