AIに関する知識は乏しいながらも、AzureのAIサービスを用いてそれっぽいことをしてみたいと思っていたところ、ちょうどいいコンテンツがありました。
ドローンによる船の撮影画像を学習させて、作成した検出モデルを用いて衛星画像から船を判別してみるまでを、Azureのサービスだけで実現するという内容になっています。
今回は、こちらを実施してみた、という記事になります。
そもそもAzureの機械学習サービスとは
Azureの機械学習サービスは大別すると、「Azure Applied AI Services」「Azure Cognitive Services」「Azure Machine Learning」の3つがあり、それぞれ以下の図のようなサービスがあります。
 (参照:https://www.slideshare.net/KokiIshizuka/ignitebuild2021-azure-cognitive-servicesazure-applied-ai-services)
(参照:https://www.slideshare.net/KokiIshizuka/ignitebuild2021-azure-cognitive-servicesazure-applied-ai-services)
| サービス | 特徴 |
|---|---|
| Azure Applied AI Service | 開発者が素早く効果的にデータを活用するための高度なサービスで、メトリクスの異常の監視と分析やドキュメント中の情報の抽出が可能 |
| Azure Cognitive Service | クラウドベースのサービスで、REST APIとクライアントライブラリSDKが用意されている |
| Azure Machine Learning | 機械学習プロジェクトのライフサイクルを加速および管理できる |
今回は、この中からAzure Cognitive ServicesのCustom Visionを使って、簡単に機械学習モデルを作ってみます。
Azure Cognitive Serviceとは
Azure Cognitive Servicesとは、人工知能やデータサイエンスのスキルが特に必要なくても、言語やプラットフォームを問わずにアプリを構築できるAIサービスです。Cognitive Servicesのメリットとして、以下のようなものが挙げられます。

(参照:https://azure.microsoft.com/ja-jp/products/cognitive-services/#overview)
また、Cognitive Servicesのサービス内容は大きく5つ(視覚、音声、Language、決定、検索)に分かれています。今回は、この中から視覚(Vision)を選んで機械学習にトライします。
Custom Visionとは
Custom Visionは、Cognitive ServicesのVision分野のサービスで、写真や動画、デジタルコンテンツの認識や識別が可能となっています。Vision分野のサービスには、Custom Visionの他に、Computer Visionというサービスがあり、機械学習のモデルが複数用意されていて簡単に使えるのですが、Custom Visionリソースを用いると、オリジナルのオブジェクト検出モデルを作成することができます。
では、さっそく設定していきます。
Custom Visionの設定
以下の手順で設定していきます。
- Custom Visionリソースの作成
- 画像のトレーニング
- 実際にテスト
それでは、1つずつ見ていきます。
1. Custom Vision リソースの作成
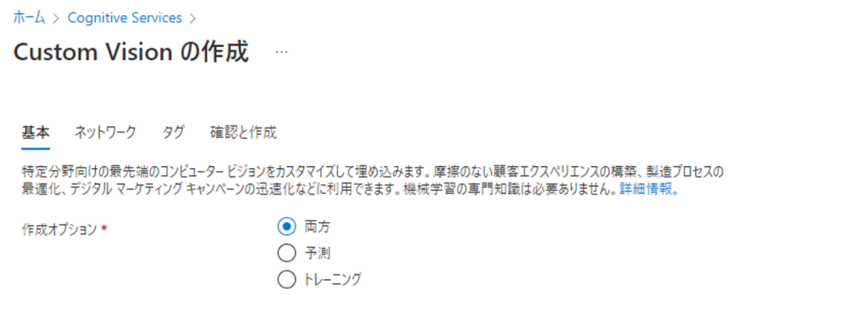
Azure portalの「ホーム→Cognitive Services→Custom Vision」より、Custom Visionリソースを作成します。「作成オプション」では、「予測 or トレーニング or 両方」から選択できます。
続いて、Custom Vision portalより、Custom Visionプロジェクトを作成します。先ほど作成したCustom Visionリソースの情報を反映させて、以下のように作成します。
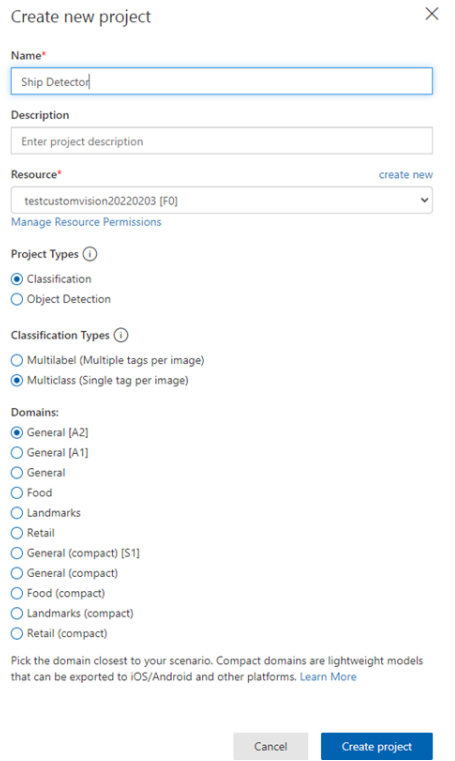
少し待つと、プロジェクトが作成されて、新しいブラウザ画面に遷移します。このプロジェクト内で、続いて画像のトレーニングを実施していきます。
2. 画像のトレーニング
では、トレーニング環境を設定していきます。手順としては、「画像アップロード」「対象物にタグをつける」「トレーニング」という流れになります。
画像アップロード
まずは、「Add images」よりアップロードしたい画像を選択します。
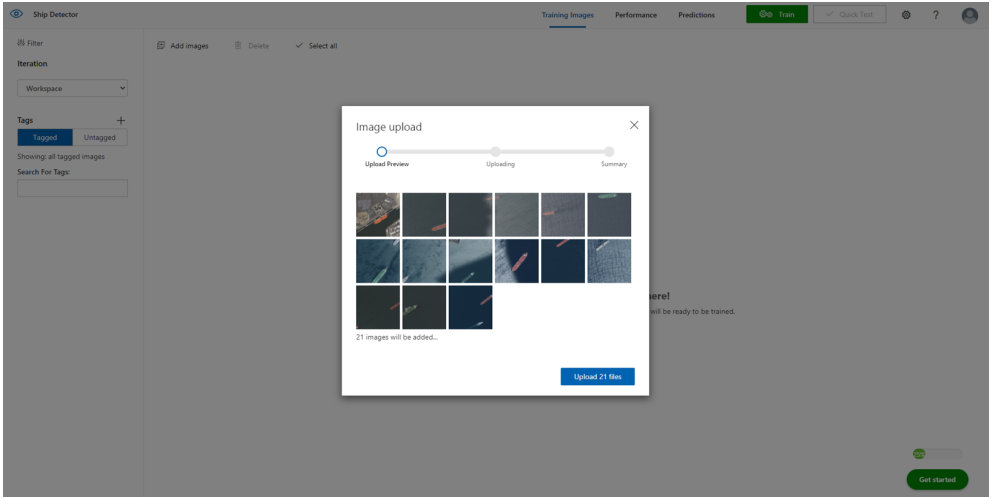
今回は、本Githubにあらかじめ学習データとして格納されている画像を20枚ほどアップロードしました。
対象物にタグをつける
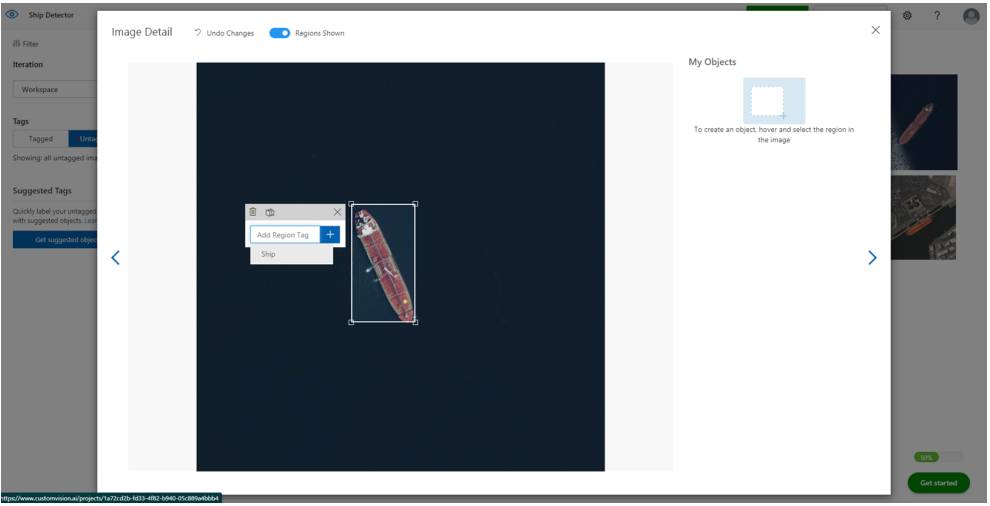
アップロードが終わったら、画像にタグを付与していきます。判別させたい対象物をマウスでクリックすると、以下のように自動的に対象の候補範囲を絞ってくれます。
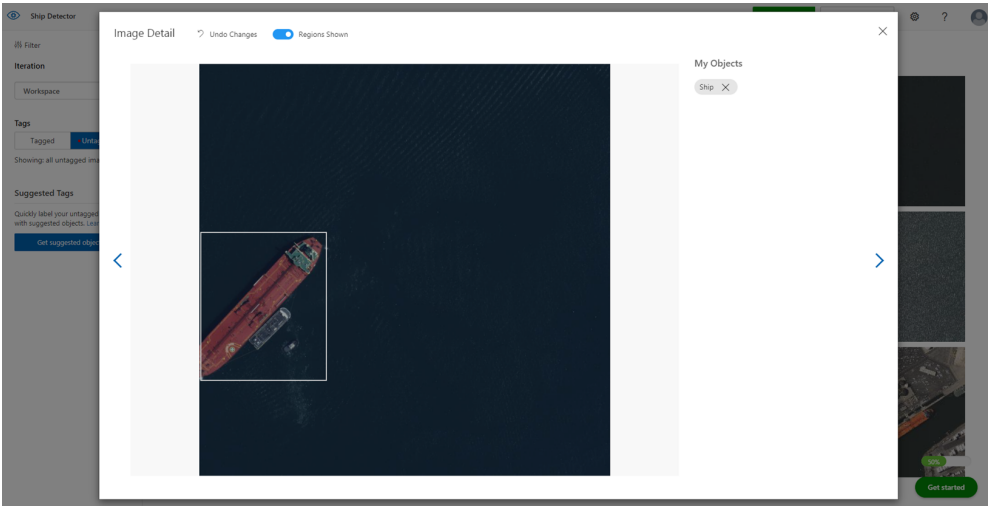
わざわざ図形で対象物を囲う必要もなく、ポチっと押すだけで対象物を判定してくれるのはとても便利でした。
続いて、選択した対象物に対してタグを付与していきます。今回は「Ships」というタグを付与しました。一度タグを登録すると、登録したタグの中から選択できるので、20枚程度の画像に対しては5分ぐらいでタグ付けが完了しました。
トレーニング
では、タグ付けをした画像を用いてトレーニングをします。Trainをクリックし、以下のポップアップが表示されるのでより短時間でトレーニングできるQuick Trainingを選択します。なお、Advanced Trainingだと、時間はかかるものの、より精度の高いモデルを作成することができます。
トレーニングタイプを選択した後に、Trainをクリックするとトレーニングが開始されます。数分待つと、以下のようにいくつかのパラメータ(適合率、再現率、アプリパフォーマンスなど)の評価が画面に表示されて、モデルが完成します。
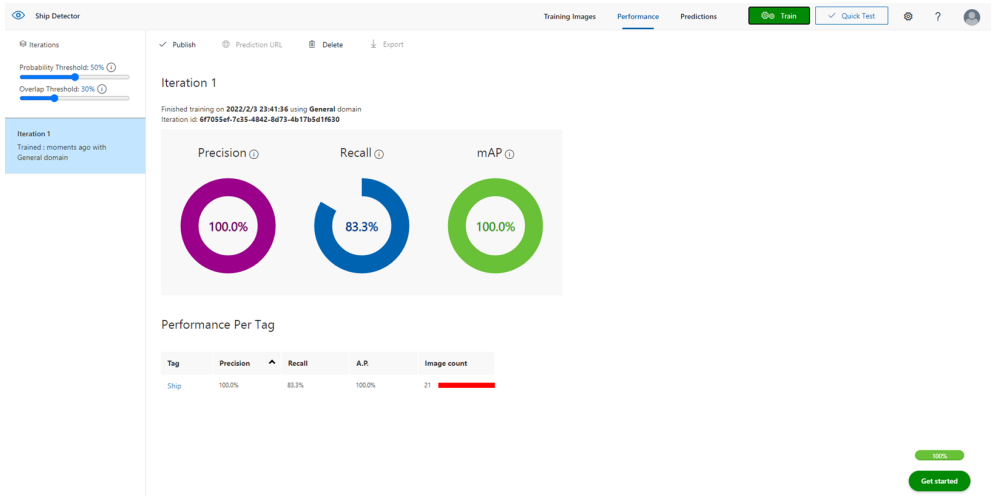
数値の導出方法や信憑性など、詳しいところまではあまり分かってないですが、このようにたった20枚の画像をポチポチしているだけで、数値だけ見ると割りと良さそうなモデルが完成しました。
では、このモデルを利用して、衛星画像から船を判別できるかどうか、テストしてみます。
3. 実際にテスト
では、作成したモデルを用いて、衛星画像から船を判別できるか試してみます。
なお、作成したモデルを公開(publish)することで、アプリからも使用することができます。今回は、MS公式からのサンプルより、作成したモデルのエンドポイント、Custom VisionリソースのKeyやIDなどを指定して、テストを実施します
。
今回、テスト画像として、Azure Mapsで使用されている衛星画像を用いて試してみました。
結果は。。
1枚目

2枚目

識別率90%を記録する対象物があったものの、2枚目の画像では船を1台認識できておらず、全体的にそこまで高精度なモデルにはなりませんでしたが、衛星画像でも船を判別することは一応確認できました。学習データを増やしたり特徴量の増減など、モデル自体をもう少し検討すれば、精度向上も期待できるかもしれませんが、今回はここまでとします。