AWS IoT Twinmakerを使って、複数データをまとめて管理してみる①の続きになります。
今回は、Timestreamを経由して、Twinmakerにデータを連携するところを解説します。
Timestreamの設定
今回のように、様々なデバイスから時系列に送られてくるデータを扱う際は、Amazon Timestreamが選択肢のひとつとしてあがってきます。
時系列データの柔軟な取得や分析を行えるクエリが利用可能なので、IoTデバイスからのデータを扱う際はとても便利です。では、さっそく設定していきましょう。
データベースを作成
Timestreamより、データベースを作成を押下します。
設定は、標準データベースを選択します。サンプルデータベースは、ワンクリックで開始できますが、今回はカスタム設定するため、標準データベースを選んでください。
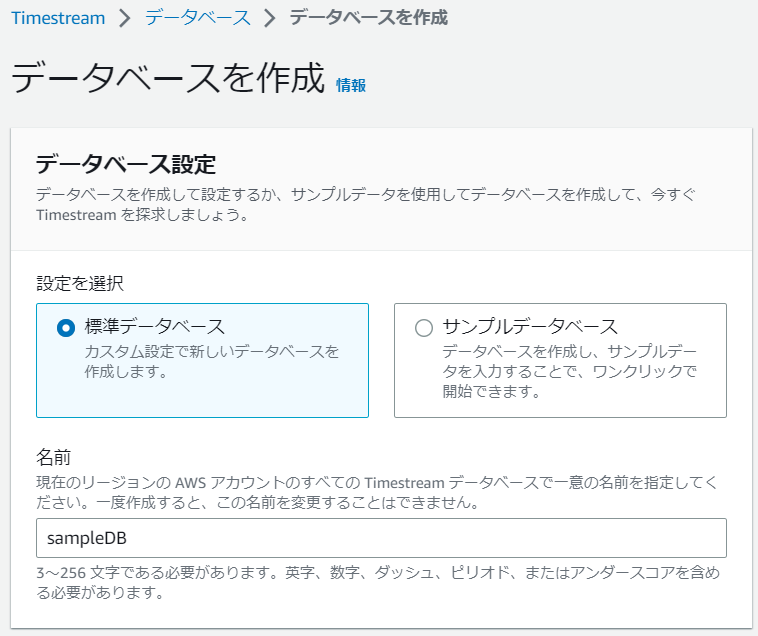
テーブルを作成
続いて、テーブルを作成します。
データベースは先ほど設定した名称のまま、テーブル名については任意の値を設定してください。また、データ保持については、メモリは1日、マグネティックストアの保持期間は1ヶ月とします。
これだけで、Timestream側の準備は完了です。
IoT Core側の設定
ここで、IoT CoreからTimestreamへデータを送信するために、IoT Coreで追加の設定をします。
IoT Coreページの左ペインより、ルールセクションを選択し、Timestreamへデータを送るためのルールを作成してきます。

ルール作成より、任意のルール名を入力したのち、ルールのクエリにて以下のように、Raspberry Piで指定したトピック名を設定します。
SELECT * FROM 'トピック名'
Step3ではルールアクションにて、先ほど作成したテーブル名などを指定して作成する。
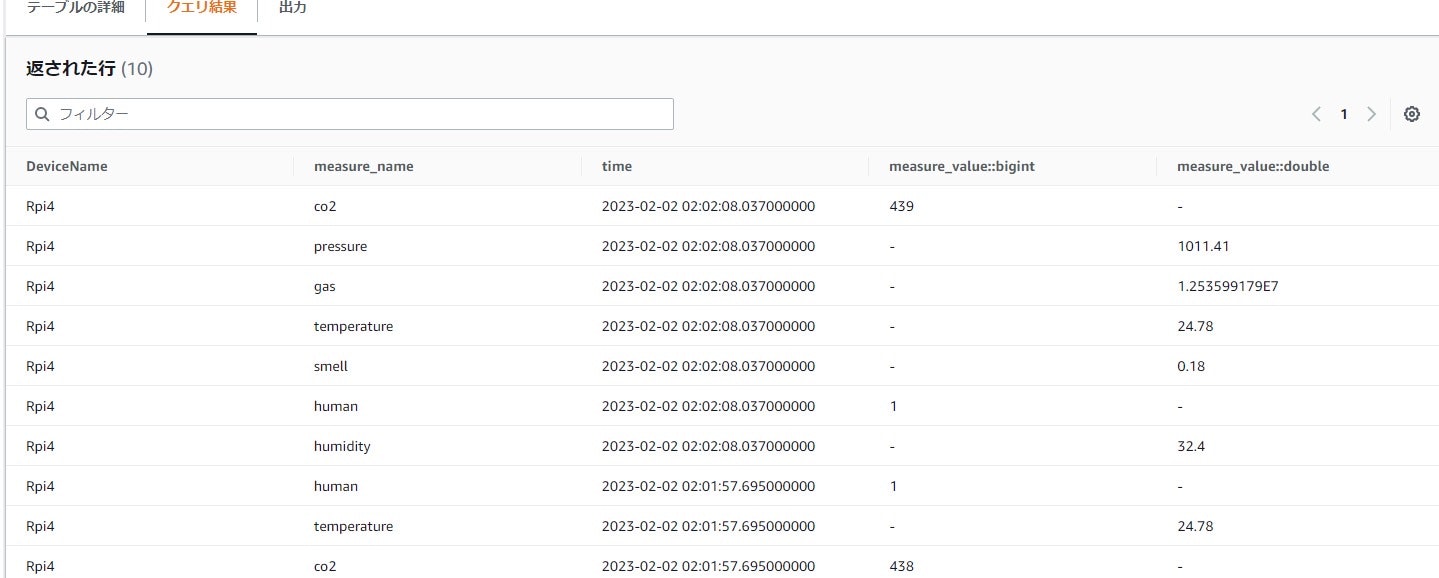
ルール作成後に、試しにTimestreamのページにて、クエリ実行してみると、以下のように複数センサーからデータを受信できていることが確認できます!
Lambdaの設定
Timestreamまでデータを送られていることは確認できたので、次にTimestreamからTwinmakerにデータを送るために、Lambdaを作成していきます。
まずは、LambdaがTimestreamにアクセスできるようにするためのIAMロールを作成します。
IAMページより、LambdaサービスにAWSLambdaBasicExecutionRoleとAmazonTimestreamReadOnlyAccessポリシーを追加したロールを作成してください。
続いて、Lambdaページより、先ほど作成したIAMロールを付与したPython関数を作成します。
作成後に、環境変数タブより、以下2つを設定してください。
| key | value |
|---|---|
| TIMESTREAM_DATABASE_NAME | 作成したデータベース名 |
| TIMESTREAM_TABLE_NAME | 作成したテーブル名 |
コードは今回は以下のようなものを作成しました。
後ほどIoT Twinmakerでデバイスごとに別々のモデルを作成しますので、Timestreamから送られてくるデータのうち、Device Nameを確認して、のちに作成するIoT Twinmakerの各デバイスに割り振っています。
import logging
import json
import os
import boto3
from datetime import datetime
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
# Get db and table name from Env variables
DATABASE_NAME = os.environ['TIMESTREAM_DATABASE_NAME']
TABLE_NAME = os.environ['TIMESTREAM_TABLE_NAME']
# Python boto client for AWS Timestream
QUERY_CLIENT = boto3.client('timestream-query')
# Utility function: parses a timestream row into a python dict for more convenient field access
def parse_row(column_schema, timestream_row):
data = timestream_row['Data']
result = {}
for i in range(len(data)):
info = column_schema[i]
datum = data[i]
key, val = parse_datum(info, datum)
result[key] = val
return result
# Utility function: parses timestream datum entries into (key,value) tuples. Only ScalarTypes currently supported.
def parse_datum(info, datum):
if datum.get('NullValue', False):
return info['Name'], None
column_type = info['Type']
if 'ScalarType' in column_type:
return info['Name'], datum['ScalarValue']
else:
raise Exception(f"Unsupported columnType[{column_type}]")
# This function extracts the timestamp from a Timestream row and returns in ISO8601 basic format
def get_iso8601_timestamp(str):
# e.g. '2022-04-06 00:17:45.419000000' -> '2022-04-06T00:17:45.419000000Z'
return str.replace(' ', 'T') + 'Z'
# エンティティ設定
def get_entity(str):
if str == '<エンティティ1_ID>':
return 'Rpi1'
elif str == '<エンティティ2_ID>':
return 'Rpi2'
elif str == '<エンティティ3_ID>':
return 'Rpi3'
elif str == '<エンティティ4_ID>':
return 'Rpi4'
elif str == '<エンティティ5_ID>':
return 'Rpi5'
# Main logic
def lambda_handler(event, context):
selected_property = event['selectedProperties'][0]
selected_entityId = event['entityId']
LOGGER.info("Selected property is %s", selected_property)
LOGGER.info("Selected entityID is %s", selected_entityId)
# 1. EXECUTE THE QUERY TO RETURN VALUES FROM DATABASE
query_string = f"SELECT DeviceName, measure_name, time, measure_value::bigint, measure_value::double " \
f" FROM {DATABASE_NAME}.{TABLE_NAME} " \
f" WHERE time > from_iso8601_timestamp('{event['startTime']}')" \
f" AND time <= from_iso8601_timestamp('{event['endTime']}')" \
f" AND measure_name = '{selected_property}'" \
f" AND DeviceName = '{get_entity(selected_entityId)}'" \
f" ORDER BY time ASC"
try:
query_page = QUERY_CLIENT.query(
QueryString = query_string
)
except Exception as err:
LOGGER.error("Exception while running query: %s", err)
raise err
# Query result structure: https://docs.aws.amazon.com/timestream/latest/developerguide/API_query_Query.html
next_token = None
if query_page.get('NextToken') is not None:
next_token = query_page['NextToken']
schema = query_page['ColumnInfo']
# 2. PARSE TIMESTREAM ROWS
result_rows = []
for row in query_page['Rows']:
row_parsed = parse_row(schema,row)
# LOGGER.info('row parsed: %s', row_parsed)
result_rows.append(row_parsed)
# 3. CONVERT THE QUERY RESULTS TO THE FORMAT TWINMAKER EXPECTS
# There must be one entityPropertyReference for Humidity OR one for Temperature
entity_property_reference_co2 = {}
entity_property_reference_co2['componentName'] = 'timestream-reader'
entity_property_reference_co2['propertyName'] = 'co2'
entity_property_reference_human = {}
entity_property_reference_human['componentName'] = 'timestream-reader'
entity_property_reference_human['propertyName'] = 'human'
entity_property_reference_gas = {}
entity_property_reference_gas['componentName'] = 'timestream-reader'
entity_property_reference_gas['propertyName'] = 'gas'
entity_property_reference_temperature = {}
entity_property_reference_temperature['componentName'] = 'timestream-reader'
entity_property_reference_temperature['propertyName'] = 'temperature'
entity_property_reference_pressure = {}
entity_property_reference_pressure['componentName'] = 'timestream-reader'
entity_property_reference_pressure['propertyName'] = 'pressure'
entity_property_reference_humidity = {}
entity_property_reference_humidity['componentName'] = 'timestream-reader'
entity_property_reference_humidity['propertyName'] = 'humidity'
entity_property_reference_light = {}
entity_property_reference_light['componentName'] = 'timestream-reader'
entity_property_reference_light['propertyName'] = 'light'
entity_property_reference_smell = {}
entity_property_reference_smell['componentName'] = 'timestream-reader'
entity_property_reference_smell['propertyName'] = 'smell'
values_co2 = []
values_human = []
values_gas = []
values_temperature = []
values_pressure = []
values_humidity = []
values_light = []
values_smell = []
for result_row in result_rows:
ts = result_row['time']
DeviceName = result_row['DeviceName']
measure_name = result_row['measure_name']
measure_value = result_row['measure_value::bigint']
measure_value_double = result_row['measure_value::double']
time = get_iso8601_timestamp(ts)
value = { 'doubleValue' : str(measure_value) }
value_double = { 'doubleValue' : str(measure_value_double) }
entity_property_reference_co2['entityId'] = DeviceName
entity_property_reference_human['entityId'] = DeviceName
entity_property_reference_gas['entityId'] = DeviceName
entity_property_reference_temperature['entityId'] = DeviceName
entity_property_reference_pressure['entityId'] = DeviceName
entity_property_reference_humidity['entityId'] = DeviceName
entity_property_reference_light['entityId'] = DeviceName
entity_property_reference_smell['entityId'] = DeviceName
if measure_name == 'co2':
values_co2.append({
'time': time,
'value': value
})
elif measure_name == 'human':
values_human.append({
'time': time,
'value': value
})
elif measure_name == 'gas':
values_gas.append({
'time': time,
'value': value_double
})
elif measure_name == 'temperature':
values_temperature.append({
'time': time,
'value': value_double
})
elif measure_name == 'pressure':
values_pressure.append({
'time': time,
'value': value_double
})
elif measure_name == 'humidity':
values_humidity.append({
'time': time,
'value': value_double
})
elif measure_name == 'light':
values_light.append({
'time': time,
'value': value_double
})
elif measure_name == 'smell':
values_smell.append({
'time': time,
'value': value_double
})
# The final structure "propertyValues"
property_values = []
try:
if(measure_name == 'co2'):
property_values.append({
'entityPropertyReference': entity_property_reference_co2,
'values': values_co2
})
elif(measure_name == 'human'):
property_values.append({
'entityPropertyReference': entity_property_reference_human,
'values': values_human
})
elif(measure_name == 'gas'):
property_values.append({
'entityPropertyReference': entity_property_reference_gas,
'values': values_gas
})
elif(measure_name == 'temperature'):
property_values.append({
'entityPropertyReference': entity_property_reference_temperature,
'values': values_temperature
})
elif(measure_name == 'pressure'):
property_values.append({
'entityPropertyReference': entity_property_reference_pressure,
'values': values_pressure
})
elif(measure_name == 'humidity'):
property_values.append({
'entityPropertyReference': entity_property_reference_humidity,
'values': values_humidity
})
elif(measure_name == 'light'):
property_values.append({
'entityPropertyReference': entity_property_reference_light,
'values': values_light
})
elif(measure_name == 'smell'):
property_values.append({
'entityPropertyReference': entity_property_reference_smell,
'values': values_smell
})
LOGGER.info("property_values: %s", property_values)
# marshall propertyValues and nextToken into final response
return_obj = {
'propertyValues': property_values,
'nextToken': next_token
}
except Exception as err:
print("No Data")
return_obj = {'propertyValues': [], 'nextToken': next_token}
return return_obj
この関数が、いわゆるデータコネクタの役割を果たしていて、IoT Twinmakerにデータを連携する箇所となります。
次回は、IoT Twinmakerでデバイスからのデータを受信して、3Dモデルに紐づかせて、Grafanaで表示させるという内容を解説していきます。
本記事は、以下を参考にしています。
https://aws.amazon.com/jp/blogs/news/build-a-digital-twin-of-your-iot-device-and-monitor-real-time-sensor-data-using-aws-iot-twinmaker-part-1-of-2/