こんにちは。株式会社船井総合研究所でデータ分析に携わっている平尾です。
今回は、Microsoft Fabricにおいてデータフレームが記載されているエクセルファイルを取り込み、テーブルを作成する方法に関してお伝えします。
また、そのデータフレームに不備があった際にTeamsでエラーメッセージを表示する方法も
お伝えします。
(pythonのライブラリであるpandasの基礎的な理解があることを前提にお話させていただきます。)
対象のエクセルファイル
今回は、「テーブル」と「補足」の2つのシートが存在する場合を例にします。
「テーブル」シート

「補足」シート

Notebookにおいてファイルを取り込む
まず、以下のようにエクセルファイルを格納します。
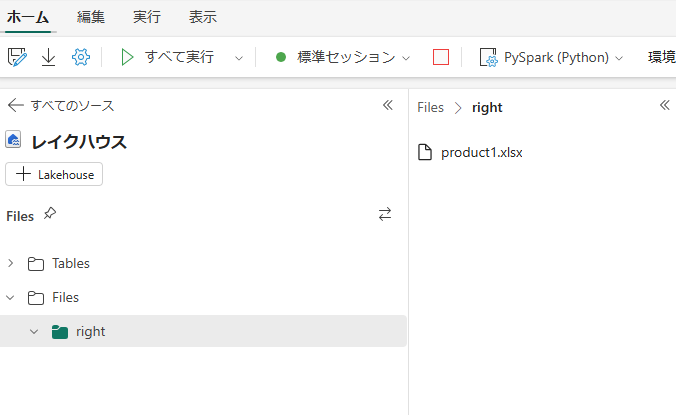
そして、Notebookにおいて以下のようなコードを記入します。
import pandas as pd
df1 = pd.read_excel("/lakehouse/default/Files/right/product1.xlsx", sheet_name = "テーブル" ,header=2, usecols="B:D")
missing_rows = df1[df1['商品コード'].isnull()] #'商品番号列において欠損値を含む行を抽出
min_row_index = missing_rows.index.min() #抽出された行のindexの最小値を取得
df2 = df1.iloc[:min_row_index] #抽出したい範囲のみ取得
df2['値段(円)'] = df2['値段(円)'].astype(int) # '値段(円)' の小数点を切り捨て
df2
すると、以下のようにファイルが取り込まれます。

「テーブル」シートの「商品コード」列において欠損値が発生するまでの行をデータフレームとして認識させています。そのため、「メモ」は除外されます。
データフレームを保存する
Notebookにおいて以下のようなコードを記入します。
df3 = pd.read_excel("/lakehouse/default/Files/right/product1.xlsx", sheet_name = "補足" ,header=1, usecols="B:C")
from pyspark.sql import SparkSession
# SparkSessionを作成
spark = SparkSession.builder.appName("SaveDataFrameAsTable").getOrCreate()
# pandas DataFrameをSpark DataFrameに変換
spark_df = spark.createDataFrame(df2)
#保存先のテーブル名と形式を指定
table_name = f"`製品テーブル_{df3.iloc[0,0]}`" # テーブル名を指定
format = "parquet" # 保存形式を指定 (parquet, csv, jsonなど)
# テーブルとして保存
spark_df.write.saveAsTable(table_name, format=format, mode="overwrite", orderBy="index") # mode="overwrite" で既存のテーブルを上書き
すると、以下のように、「製品テーブル_平尾」というテーブルが作成されます。

ここでは、様々なデータソースへの接続、データの読み込み、変換、分析などを実行できる
「SparkSession」を使用しています。
また、エクセルファイルの「補足」シートの「記載者」を、テーブル名に使用しています。
取り込んだ際のエラーメッセージをTeamsに表示する。
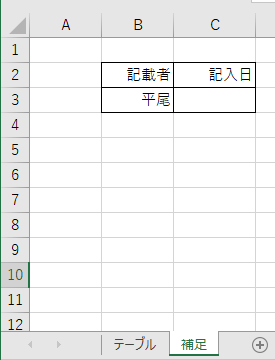
上のように、「補足」シートにおいて欠損値があった際にエラーをTeamsに表示する方法を説明します。
まず、ここまでで書いたコードはこのようになっています。
import pandas as pd
df1 = pd.read_excel("/lakehouse/default/Files/right/product1.xlsx", sheet_name = "テーブル" ,header=2, usecols="B:D")
missing_rows = df1[df1['商品コード'].isnull()] #'商品番号列において欠損値を含む行を抽出
min_row_index = missing_rows.index.min() #抽出された行のindexの最小値を取得
df2 = df1.iloc[:min_row_index] #抽出したい範囲のみ取得
df2['値段(円)'] = df2['値段(円)'].astype(int) # '値段(円)' の小数点を切り捨て
df2
df3 = pd.read_excel("/lakehouse/default/Files/right/product1.xlsx", sheet_name = "補足" ,header=1, usecols="B:C")
from pyspark.sql import SparkSession
# SparkSessionを作成
spark = SparkSession.builder.appName("SaveDataFrameAsTable").getOrCreate()
# pandas DataFrameをSpark DataFrameに変換
spark_df = spark.createDataFrame(df2)
#保存先のテーブル名と形式を指定
table_name = f"`製品テーブル_{df3.iloc[0,0]}`" # テーブル名を指定
format = "parquet" # 保存形式を指定 (parquet, csv, jsonなど)
# テーブルとして保存
spark_df.write.saveAsTable(table_name, format=format, mode="overwrite", orderBy="index") # mode="overwrite" で既存のテーブルを上書き
上のコードブロックにおける10行目のdf3 = .. を挟む形で、以下のコードを追加します。
(エラーを発生させるファイルを用いるために、ファイルパスを変えています。)
import requests
import json
def send_teams_message(message):
webhook_url = "https:~" # Teams の Webhook URL を設定 ※ここではURLを省略しています。
headers = {"Content-Type": "application/json"}
payload = {
"text": f"Notebook でエラーが発生しました: {message}", # メッセージにメンションを追加,
"markdown": True # markdown 形式を有効にする
}
response = requests.post(webhook_url, data=json.dumps(payload), headers=headers)
if response.status_code != 200:
print(f"Teams への通知に失敗しました: {response.text}")
df3 = pd.read_excel("/lakehouse/default/Files/wrong/product2.xlsx", sheet_name = "補足" ,header=1, usecols="B:C")
missing_count = df3.isnull().sum().sum()
# 欠損値がある場合にエラーメッセージを表示
if missing_count > 0:
# 欠損値がある列名を取得
missing_cols = df3.columns[df3.isnull().any()].tolist()
error_message = f"{', '.join(missing_cols)}が入力されていません"
send_teams_message(error_message)
raise ValueError(error_message) # エラーを再発生させる (必要に応じて)
TeamsのwebhookURLを用いてエラーメッセージを送れるように設定しています。
webhookURLの作り方は、以下のものを参照してください。
https://learn.microsoft.com/ja-jp/microsoftteams/platform/webhooks-and-connectors/how-to/add-incoming-webhook?tabs=newteams%2Cdotnet
これで、もし「補足」シートに欠損値があった際には以下のメッセージが送られます。

コード全体
最終的なコード全体がこちらです。
import pandas as pd
df1 = pd.read_excel("/lakehouse/default/Files/wrong/product2.xlsx", sheet_name = "テーブル" ,header=2, usecols="B:D")
missing_rows = df1[df1['商品コード'].isnull()] #'商品番号列において欠損値を含む行を抽出
min_row_index = missing_rows.index.min() #抽出された行のindexの最小値を取得
df2 = df1.iloc[:min_row_index] #抽出したい範囲のみ取得
df2['値段(円)'] = df2['値段(円)'].astype(int) # '値段(円)' の小数点を切り捨て
import requests
import json
def send_teams_message(message):
webhook_url = "https:~" # Teams の Webhook URL を設定 ※ここではURLを省略しています。
headers = {"Content-Type": "application/json"}
payload = {
"text": f"Notebook でエラーが発生しました: {message}", # メッセージにメンションを追加,
"markdown": True # markdown 形式を有効にする
}
response = requests.post(webhook_url, data=json.dumps(payload), headers=headers)
if response.status_code != 200:
print(f"Teams への通知に失敗しました: {response.text}")
df3 = pd.read_excel("/lakehouse/default/Files/wrong/product2.xlsx", sheet_name = "補足" ,header=1, usecols="B:C")
missing_count = df3.isnull().sum().sum()
# 欠損値がある場合にエラーメッセージを表示
if missing_count > 0:
# 欠損値がある列名を取得
missing_cols = df3.columns[df3.isnull().any()].tolist()
error_message = f"{', '.join(missing_cols)}が入力されていません"
send_teams_message(error_message)
raise ValueError(error_message) # エラーを再発生させる (必要に応じて)
from pyspark.sql import SparkSession
# SparkSessionを作成
spark = SparkSession.builder.appName("SaveDataFrameAsTable").getOrCreate()
# pandas DataFrameをSpark DataFrameに変換
spark_df = spark.createDataFrame(df2)
#保存先のテーブル名と形式を指定
table_name = f"`製品テーブル_{df3.iloc[0,0]}`" # テーブル名を指定
format = "parquet" # 保存形式を指定 (parquet, csv, jsonなど)
# テーブルとして保存
spark_df.write.saveAsTable(table_name, format=format, mode="overwrite", orderBy="index") # mode="overwrite" で既存のテーブルを上書き
最後に
ここまで、Microsoft Fabricにおいてエクセルファイルを取り込み、データテーブルを保存する方法と、エラーメッセージを表示する方法に関してお伝えしました。
また、Teamsのチャネルのメンバーに対しメンションをつけてエラーメッセージを送る方法を現在検討中です。メンションを付ける方法が分かり次第また投稿します。
お読みいただきありがとうございました。