はじめに
この記事は、SLP-KBIT Advent Calendar 2019 の9日目の記事です。
日本語プログラミング言語といえばなでしこやプロデルなどがあります。英語が苦手な私でもプログラミングを行うことができるのでとてもありがたいですね。興味をそそられて日本語プログラミング言語、ogengoを自作したので紹介していきます。
言語処理系について
プログラミング言語の自作ということで、言語処理系についてです。
言語処理系とは、プログラムを計算機で実行するためのソフトウェアのことで、大きく分けてコンパイラとインタプリタがあります。コンパイラは、ソースコードを機械語に翻訳するものを指します。ソースコードを翻訳して実行もするものをコンパイラと呼ぶこともあります。それに対しインタプリタは、ソースコードを解釈しながら実行していきます。
今回は、日本語で書かれたプログラムを対話形式で実行するインタプリタを作成していきます。
開発環境
- macOS Big Sur
- python 3.8.5
使用したライブラリ
- ply
- MeCab
実装
インタプリタを作成するには字句解析器、構文解析器を実装する必要があります。字句解析器や構文解析器を一から作成するのは大変なので、plyを利用して実装しました。
事前処理
英語で書かれたプログラムは、単語間がスペースで区切られていますが、日本語のプログラムは単語が連結しており、単語の区切りを見つけるのが大変そうです。
そこで、事前処理として、MeCabを用いて分かち書きします。
桃太郎は10
の文を分かち書きすると
桃太郎 は 10
となります。
この文はこれで良いのですが、
攻撃力は10
のような文の場合
攻撃 力 は 10
ではなく
攻撃力 は 10
となって欲しいので、後述する予約後以外の名詞が連続して出現するときは連結することにします。
上記のことをコードにしたものがw_separator関数です。1行分のコードの単語と単語の間に空白を加えていきます。
def w_separator(line):
tagger = mecab.Tagger()
words = tagger.parse(line).split('\n')
wordsList = []
code = ""
for v in words:
w = v.split()
if w == ['EOS']:
break
word = {'value': w[0], 'kind': w[1].split(',')[0]}
wordsList.append(word)
for i in range(len(wordsList)-2, -1, -1):
if wordsList[i+1]["value"] in reserved:
continue
if wordsList[i+1]["kind"] == '名詞' and wordsList[i]["kind"] == '名詞':
wordsList[i]["value"] += wordsList[i+1]["value"]
wordsList.pop(i+1)
for v in wordsList:
code += v["value"] + ' '
return code
字句解析
字句解析は、ソースコードを解析して、トークンに分割することです。
例えば
def func():
を
"def", "func", "(", ")", ":"
に分割します。
plyで字句解析器を作成するには、トークンリストを作成する必要があります。扱うトークンは以下のようにしました。
tokens = (
'ID',
'TASU',
'HIKU',
'NUMBER',
'VAR',
'NI',
'WO',
'HA',
'NO',
'KARA',
)
次に、各トークンの定義を決めていきます。
t_ignore = ' \t'
t_VAR = r'[一-龥ぁ-んァ-ン_][一-龥ぁ-んァ-ン0-9_]*'
def t_NUMBER(t) :
r'[0-9]+'
t.value = int(t.value)
return t
def t_newline(t):
r'\n+'
t.lexer.lineno += len(t.value)
def t_error(t):
print("Invalid Token:",t.value[0])
t.lexer.skip(1)
予約語を決めていきます。
reserved = {
'足す' : 'TASU',
'引く' : 'HIKU',
'に' : 'NI',
'を' : 'WO',
'は' : 'HA',
'の' : 'NO',
'から' : 'KARA',
}
def t_ID(t):
r'[一-龥ぁ-んァ-ン_][一-龥ぁ-んァ-ン0-9_]*'
t.type = reserved.get(t.value,'VAR')
return t
最後に字句解析器を構築します。
lexer = lex.lex()
構文解析と実行
構文解析は、トークン間の関係性を解析して、構文木を作る等します。
例えば
1+2*(3-4)
を構文木にすると
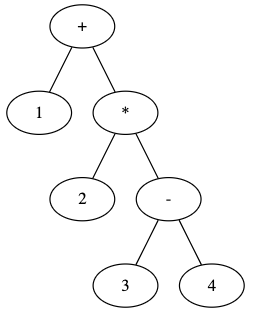
になります。
それでは実際に作っていきます。
まず、変数を保持するための辞書を用意しておきます。
names = {}
plyの構文解析器ジェネレータは、構文解析ようの関数はp_という名前で始まり、関数の最初に構文規則を記述するというルールがあります。記述した構文規則の順番に数字が割り当てられており、下記のp_prog()関数では、p[0]がprogを表し、p[1]がsentenceを示しています。
以下に構文解析と実行を行う関数を示します。
def p_prog(p):
'prog : sentence'
p[0] = p[1]
def p_sentence(p):
'''sentence : formula
| assign
| against'''
p[0] = p[1]
def p_assign1(p):
'assign : VAR HA formula'
if p[1] not in names:
names[p[1]] = {}
names[p[1]] = p[3]
p[0] = names[p[1]]
def p_assign2(p):
'assign : VAR NO VAR HA formula'
if p[1] not in names:
names[p[1]] = {}
if p[3] not in names[p[1]]:
names[p[1]][p[3]] = {}
names[p[1]][p[3]] = p[5]
p[0] = names[p[1]][p[3]]
def p_against1(p):
'''against : VAR NI formula WO TASU
| VAR KARA formula WO HIKU'''
if p[5] == '足す':
names[p[1]] += p[3]
elif p[5] == '引く':
names[p[1]] -= p[3]
p[0] = names[p[1]]
def p_against2(p):
'''against : VAR NO VAR NI formula WO TASU
| VAR NO VAR KARA formula WO HIKU'''
if p[7] == '足す':
names[p[1]][p[3]] += p[5]
elif p[7] == '引く':
names[p[1]][p[3]] -= p[5]
p[0] = names[p[1]][p[3]]
def p_formula(p):
'formula : term'
p[0] = p[1]
def p_term(p):
'''term : term TASU factor
| term HIKU factor
| factor'''
if len(p) < 3:
p[0] = p[1]
elif p[2] == '足す':
p[0] = p[1] + p[3]
elif p[2] == '引く':
p[0] = p[1] - p[3]
def p_factor_num(p):
'factor : NUMBER'
p[0] = p[1]
def p_factor_var1(p):
'factor : VAR'
p[0] = names[p[1]]
def p_factor_var2(p):
'''factor : VAR NO VAR'''
p[0] = names[p[1]][p[3]]
上記に当てはまらない構文が登場したときにエラーを吐くための関数がp_error関数です。
def p_error(p):
print(p)
print("Syntax error in input!")
最後に構文解析器を構築します。
parser = yacc.yacc()
成果物
実際に動かしたらこんな感じになります。
$ python3 ogengo.py
>桃太郎の攻撃力は100
100
>犬の攻撃力は150
150
>猿の攻撃力は150
150
>雉の攻撃力は150
150
>鬼の体力は3000
3000
>鬼の体力から桃太郎の攻撃力足す犬の攻撃力足す猿の攻撃力足す雉の攻撃力を引く
2450
>
出来上がったソースコードはこちらです。
おわりに
この記事では、日本語プログラミング言語を自作していきました。
ライブラリを利用すればプログラミング言語もサクッと作れるのでいいですね。
参考
https://www.yoshiislandblog.net/2017/12/31/lex-yacc-python/
https://typea.info/tips/wiki.cgi?page=Python+PLY