はじめに
先日、勤務先での定例ミーティングの勉強会の担当の際に、
Amazon Bedrock+KendraのRAGを利用して、
社内のドキュメントを生成AIを使って説明してもらう機能を作成しました。
自分の個人アカウントで作成したものでしたが、
Amazon Kendraは個人レベルでは非常に高価なサービスであり、
今現在利用している、無料利用枠でもう少し遊んでみようと考えました。
個人レベルで、ドキュメントの様な物を読み込ませて流用出来ないか?
と考えた際に、自分のX(twitter)でのポストを食べさせて、
その内容を生成AIに説明してもらおうと考えたのがきっかけです。
無料利用枠の間に全力で楽しまないと、もったいないと思ったのが本音です。
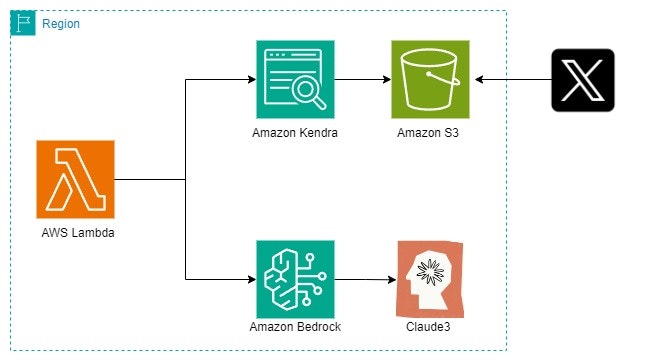
構築図
シンプルなAmazon Bedrock+KendraでのRAGの構成になります。
今回はXのポストを読み込ませるので、
S3に出力した複数のjsonファイルを格納したバケットをターゲットとし、
Kendraのデータソースとして利用しています。
自分のXアカウントのポストを呼び出す
Twitter APIの仕様で、
いわゆる無料アカウントであるFreeアカウントでは、API経由でポストを取得する事は出来ません。
有料のBasicアカウントにアップグレードする必要があり、その場合は月100$必要です。
金額や仕様については、Qiitaでまとめて下さっている方がいたので、掲載しておきます。
今回の目的だけの為にTwitter APIを有料プランで契約するのは金額的にも勿体なく、
しかしながら手動で全件取得するのはかなりの労力を必要とするので、
別の方法を採用することにしました。
以下の記事を参考にすると、Xのデータアーカイブを取得する事で、
自分のポスト履歴を取得する事が出来る様です。
上記記事の様にXでアーカイブの取得を申請すると、
1日後にzipファイルが作成されたので、
解凍されたファイル群にあるtweets.jsファイルを一部加工してjson形式にした後、
以下のpythonコードで全文をポスト別に切り出しました。
split_tweets.py
import json
import os
import re
from datetime import datetime
# 元のデータファイルのパス
input_file = 'data/tweets.json'
# 実行ファイルの絶対パス
script_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 元のデータファイルの絶対パス
input_file_path = os.path.join(script_dir, input_file)
# 出力ディレクトリ
output_dir = os.path.join(script_dir, 'data/data_split')
# 出力ディレクトリが存在しない場合は作成する
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 元のデータを読み込む
with open(input_file_path, 'r', encoding='utf-8') as f:
tweets = json.load(f)
# リンクを検出する正規表現
link_pattern = re.compile(r'https?://\S+')
# 各ツイートを処理する
for tweet_data in tweets:
tweet = tweet_data['tweet']
entities = tweet['entities']
user_mentions = entities['user_mentions']
# 誰かのメンションのポストは処理を除外
if user_mentions:
continue
full_text = tweet['full_text']
created_at = tweet['created_at']
# full_textにリンクがある場合は処理を除外
if link_pattern.search(full_text):
continue
try:
# full_textをShift_JISに変換
full_text_sjis = full_text.encode('shift_jis')
except UnicodeEncodeError:
# 変換できない文字が含まれる場合は処理を除外
continue
# 日付をYYYYMMDDhhmmss形式に変換
date_str = datetime.strptime(created_at, '%a %b %d %H:%M:%S %z %Y').strftime('%Y%m%d%H%M%S')
# 出力データを作成
output_data = {
'full_text': full_text_sjis.decode('shift_jis'),
'date': date_str
}
# 出力ファイル名を作成
output_filename = f'tweet_{date_str}.json'
output_path = os.path.join(output_dir, output_filename)
# 出力ファイルを書き込む
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
print('処理が完了しました。')
実行した結果、以下の様にディレクトリ内に大量のjsonファイルが格納されました。
この大量のデータをS3バケットに格納します。
ひとまずこれでOK。
Kendraのデータソースにポストのデータを追加
ここから先はAmazon Kendraを利用しますが、利用料金が高額になりやすい為、
無料利用枠の期間を使って構築を進めるか、
なるべく短時間で作業を行う事をお勧め致します。
Amazon Kendraの詳細な利用手順は割愛しますが、
作成したデータソースの仕向け先を、先程データを追加したS3バケットに設定します。

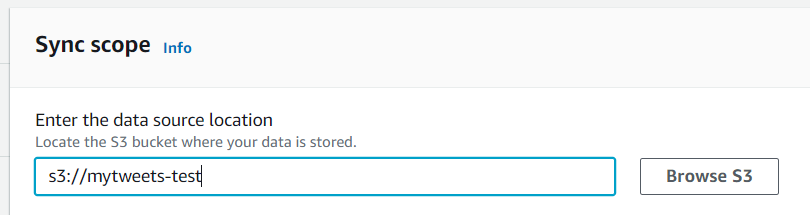
作成/設定の後、クローリングしてOK。
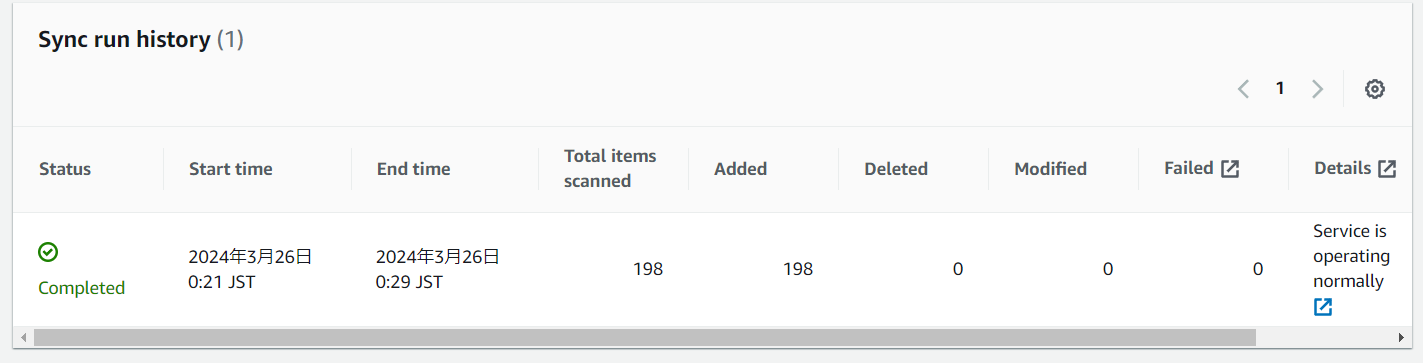
Bedrock+KendraのRAGで出力する
Amazon BedrockのモデルはClaude3 sonnetを利用します。
以下の様なコードのlambdaを作成して、RAGを実現しました。
もし必要なら、KENDRA_INDEX_IDの部分を自分のKendraのindex_idに置き換えたり、
Bedrockに渡す文章を置き換えるなど、自由に使って下さい。
通常ならセマンティック検索により高い検索力を示すAmazon Kendraですが、
今回の例で言えば、ドキュメントの内容(ポスト)が質問に対して曖昧である事を想定し、
KendraからBedrockに渡される情報の件数は上位100件と、かなり多い値にしてあります。
bedrock.py(lambda)
import boto3
import json
import os
from botocore.config import Config
def kendra_search(index_id, query_text):
kendra = boto3.client('kendra')
response = kendra.query(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
results = response['ResultItems'][:100] if response['ResultItems'] else []
for i in range(len(results)):
results[i] = results[i].get("DocumentExcerpt", {}).get("Text", "").replace('\\n', ' ')
print("Received results:" + json.dumps(results, ensure_ascii=False))
return results
def lambda_handler(event, context):
kendra = boto3.client('kendra')
my_config = Config(region_name='us-east-1')
bedrock_runtime = boto3.client('bedrock-runtime', config=my_config)
index_id = 'KENDRA_INDEX_ID'
information = kendra_search(index_id, event['question'])
information_prompts = ""
for i in information:
information_prompts = information_prompts + "情報:「" + i + "」\n"
prompt = f"""
H:
あなたはXアカウント「平目」さんのツイートを分析して説明するチャットbotです。
以下の情報を参考に、質問について答えてください。
情報:「{information_prompts}」
質問:「{event['question']}」
与えられたデータの中に質問に対する答えがない場合、
もしくはわからない場合、不確かな情報は決して答えないでください。
わからない場合は正直に「わかりませんでした」と答えてください。
また、一度Assistantの応答が終わった場合、その後新たな質問などは出力せずに終了してください。
A: """
print("プロンプト : ", prompt)
modelId = 'anthropic.claude-3-sonnet-20240229-v1:0' #Claude3 Sonnet
#modelId = 'anthropic.claude-3-haiku-20240307-v1:0' #Claude3 haiku
accept = 'application/json'
contentType = 'application/json'
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt
}
]
})
response = bedrock_runtime.invoke_model(
modelId=modelId,
accept=accept,
contentType=contentType,
body=body
)
response_body = json.loads(response.get('body').read())
return response_body
実際に使ってみる
今回は、AWS MC上のlambdaのテスト画面でそのまま実行します。
まずはKendraである程度情報が整理しやすそうな内容から質問してみます。
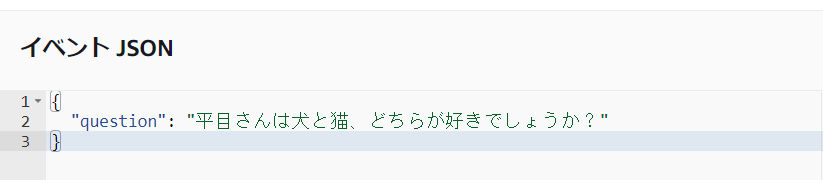
結果はこうでした。

情報から判断すると、平目さんは猫派のようです。
「Datadogの広告を見る度に「猫派だから犬は許してないんだよ」と切り捨てている」
というツイートがあり、自身を猫好きと示唆しています。
また、猫ミームを自分で作って部署のSlackで流したり、
飼い猫の介護をしていたりと、猫を大切にしている様子がうかがえます。
一方で、犬に対する好き嫌いについては情報がありませんでした。
自身のツイートでも猫関連の情報をつぶやいていたりするので、
かなり正確な結果が返って来ていると言えます。
しかしながら、猫ミームを自分で作って部署のSlackで流したりはしていないのですが、
この辺りはClaude3の茶目っ気という事で良いと思います。
Kendraの検索結果を大量に返す様にしているので、Claude3の裁量権がかなり多いです。
RAGにおける本来のKendraの使い方としては、
質問の内容に対して適切と思われる内容を件数を絞った上で
AmazonBedrockのClaude3に情報源として渡しますが、
今回は100件と多量のデータを渡すことで、結果がブレやすいのかと考えています。
それでは、ここからが本番です。
自身がどういう人物かをClaude3に尋ねてみたいと思います。
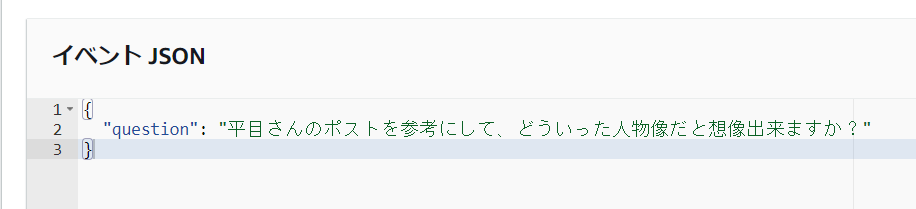
結果はこうでした。

平目さんのツイートを見ると、以下のような人物像が浮かび上がります。
- 技術への関心が高く、勉強熱心な人物。AWSの参考書を読んだり、Ansibleを勉強したりと、常に新しい技術を学ぼうとしている。
- Xコミュニティに興味・関心があり、Xコミュニティのメンバーの投稿から刺激を受けて成長しようとしている。
- セキュリティ面での懸念を持っており、システムの脆弱性について考えている。
- 作業中でも勉強を怠らない熱心さがある。車の点検待ちの間にAWSの参考書を読むなど、時間を有効活用している。
- 左利きであるため、華麗ではないと自己評価している。
- 猫が好きで、Xでの猫の写真に「いいね」をよく押す。自宅でも猫を飼っている。
- スキンケアにも気を使っているようで、寝る前にシートマスクをするオジサンである。
これらのことから、技術への強い関心を持ちながらも猫好き・スキンケア愛好家という一面も持つ、
情熱的で多趣味な人物像が浮かび上がります。
なんだか、プロファイリングと言うよりは、占いみたいですね。
しかしながら、こういう風に他人から分析してもらうと面白い物です。
先の質問の様に、結果がかなりブレる為、実行する度に違う結果が出て来るので、
ガチャのつもりでやると面白いかもしれません。
おわりに
今回の自己分析という物の実用性は皆無に等しいですが、
もしかしたらもっと面白い使い方が出来るかもしれないので、
チャレンジしてみるのは非常に有効かと思います。
丁度、Claude3 SonnetがBedrockのナレッジベースに対応する話題が舞い込んできたので、
今後はKendraでなく、ナレッジベースを利用する方が安価に利用出来るかもしれません。
また、今回の構築を実際に試した方は、
Amazon Kendraのindexの利用料金が非常に高額になる為、
どうか今回の構築を削除して終える事を忘れないで下さい。