ICLR 2017で発表された論文「ADVERSARIALLY LEARNED INFERENCE」の概要まとめ。
論文の鮮度は気にせず、気になった論文の概要まとめを書いていきます。
GAN(Generative Adversarial Networks)をはじめとした生成モデルは、文字通り実在しない画像などのデータを生成する手法となりますが、どれだけ多様なデータを生成できるかに加え、いかにしてデータから表現力の高い特徴抽出を行えるかも重要なポイントになります。この論文では、GANをベースとした拡張手法として、データから特徴抽出するALIという手法を提案しています。
概要
- 生成モデルの一種であるGANをベースに、データからその特徴を推論(inference)する手法としてAdversarially learned inference(ALI)を提案している
- GeneratorをEncoderとDecoderの2つで構成し、データだけでなく推論で得られた潜在表現との結合分布をつかって、データの真偽をDiscriminatorで判定する構成にする
- データから潜在空間へ写像がより忠実に行われるか、SVHNやCIFAR-10などのデータセットを使って、データの生成や再構成により質的に評価した
提案手法とネットワーク構成
ネットワーク構成
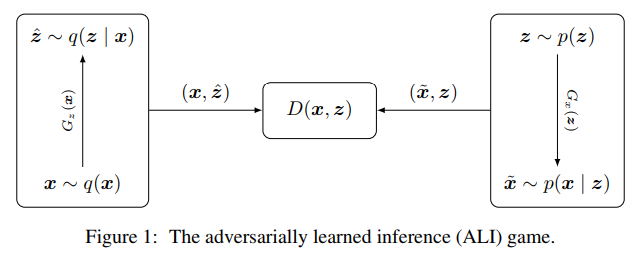
- Decoder $G_{x}(z)$ : ランダムサンプルしたノイズ$z$の属する潜在空間から、データ空間へマップして$\tilde{x}$を得る
- Encoder $G_{z}(x)$ : データ空間の$x$を潜在空間へマップして、$\hat{z}$を得る
- Discriminator $D(x, z)$ : Decoderが生成したデータと$z$の組$(\tilde{x}, z)$と、Encoderが生成した$z$とデータの組$(x, \hat{z})$の真偽を判定する
※通常のGANでは、GeneratorはDecoderのみであるが、本論文ではEncoderも合わせてGeneratorと呼ぶ。
この関係を分布で捉えると、Decoderは$z$を与えてデータを生成するので、$\tilde{x} \sim p(x|z)$で、 Encoderは$x$を与えて潜在ベクトルを生成するので、$\hat{z} \sim q(z|x)$となり、Discriminatorは偽物データのペア$(\tilde{x}, z)$か、本物データのペア$(x, \hat{z})$か、どちらの結合確率分布から生成されたものかを判定する。この点が単にデータ$x$の真偽を判定するGANと異なる。EncoderとDecoderの結合分布を書き下すと以下のとおり。
\begin{aligned}
&q(x, z) = q(x)q(z|x) \\
&p(x, z) = p(z)p(x|z)
\end{aligned}
GANと同様に、DecoderやEncoderへの入力は確率密度を明示的に設定せずともよく、逆誤差伝播が計算できればよいので、ランダムノイズを基に出力がほしい分布になるようにパラメトリゼーションすることも可能。
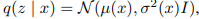

ロス関数と最適化問題
上記のネットワーク構成においてロス関数は次のようになり、GANのセッティングと同じようにmin-max最適化として定式化できる。
Generator(EncoderとDecoder)と、Discriminatorはロス関数をもとに、各自のパラメータを更新していく。
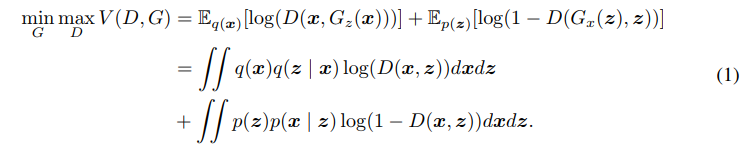
実験
上記で提案されたALIを、データセットを使った実験を行って評価していく。
画像サンプリングと再構成
SVHN、CelebA、CIFAR-10、Tiny ImageNetの4種類のデータセットを使って、Decoderによるサンプル画像の生成と、画像の再構成(元画像からEncoderで$z$を取りだし、それをDecoderに入力して画像を復元)の実験を行っている。再構成においては、EncoderとDecoderのマッピングがうまくいっていると、元の画像データが復元できると期待できる。
以下の図がその例(左列がサンプリング、右列が再構成)で、サンプル生成については、元データセットに近しいデータのサンプルが生成できている。画像再構成については、忠実に復元できておらず元画像の物体の配置、色、スタイルなどが再現できていないものもある(奇数列が元画像でその右隣りが再構成に対応)。特にCIFAR-10はその傾向が強く、データセットに含まれる画像のパターンが多く複雑で、モデルが未学習(underfitting)の状態にあるのではないか、と筆者らは推測している。




半教師あり学習
ラベル付きデータと、ALIで生成したラベルなしデータの両方を使った半教師あり学習で潜在表現を用いる。
-
Encoderから取り出した特徴を利用した場合
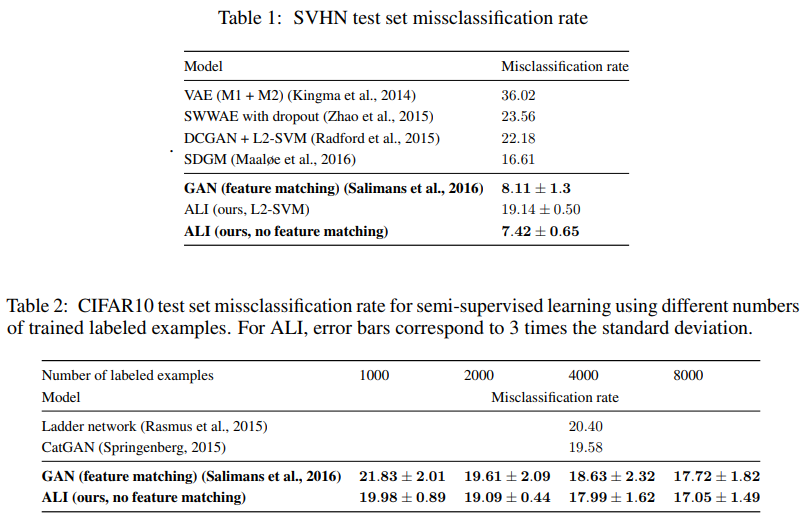
まず、SVHNでALIを学習させる(ラベルは用いない)。Encoderの隠れ層の最後3層の出力を取りだしたものを特徴ベクトル(8960次元)として、1000枚のラベル付きデータから作り出した特徴ベクトルを使って、L2-SVMで分類モデルを学習させる。このモデルで誤分類率で評価したものが、Table 1に掲載されているが、同様の実験をしているDCGAN+L2-SVM[2]と比較して約3ポイントの改善ができている(DCGANはDiscriminatorの畳込み層から28672次元の特徴ベクトルを使用)。 -
Discriminatorの特徴を利用した場合
ラベル付きデータの$(x, z)$のペアの場合はKクラスのいずれかに、Generatorが生成した$(x, z)$のラベルなしデータの場合はK+1クラスに分類するDiscriminatorとしてALIを学習させる。
SVHNでは1000のラベル付きデータを使用して学習させ、このDiscriminatorを分類器とした場合、上記のL2-SVMを使った場合より誤分類は12ポイント近く改善している(Table 1)。feature matchingを使ったGAN[3]と比べても少し改善している。CIFAR-10を使った場合でも同様に、feature matchingありのGANよりも良くなっている(Table 2)。
条件付き画像生成
データに加えて学習時にラベル$y$も各コンポーネントに与えて学習させた場合について。conditional GANのセッティングのように、画像をサンプルするときもラベルを指定して、画像を生成している(ラベルを付与して学習させない場合はランダムにサンプルされるので)。
ラベルを各ネットワークの入力に加える場合、ロス関数は以下のように書き換えられる。
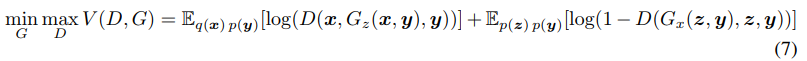

(a)列はサンプルした潜在ベクトル$z$からに対応する画像(Ⅰ~Ⅳ)で、その$z$は固定して、各属性(黒髪、茶髪、金髪など)に対応させたラベルを付与して生成した画像が(b)~(l)列に並ぶ。属性が反映されcGANと同じことができている。
マッピングによるデータや潜在ベクトルの分布の考察
EncoderやDecoderはデータ空間の潜在空間の間のマッピングになっているが、生成モデルの一つの指標としてマッピングされた分布がどれだけ元の分布とマッチしているか(例えば、Decoderが学習させた本物データの分布にどれだけ近い分布となっているか)がポイントとなる。以下では、2次元データにおいて、マッピングの分布を各手法を比較する。
まず、データの分布$q(x)$を、25個のモードをもつ2次元の混合ガウシアンとする(下図の1行目の図)。
その他の図はそれぞれ、
2行目の図 : $q(x)$から得たサンプルを、Encoderに通した$z$の分布
3行目の図 : 再構築して得られたデータの分布(データ$x$をEncoder → Decoderと順に通して得られたものの分布)
4行目の図 : $p(z)$の分布
5行目の図 : $p(z)$から得た$z$のサンプルを、Decoderに通して得られたデータ$x$の分布
となっている。
図で分布をビジュアル化して、ALIと他の手法と比較する。比較対象手法は以下。
- learned inverse mapping : GANを学習させたのち、$z$およびDecoder → Encoderと順に通して再構成した$z$の間の2乗平均誤差を最小化してEncoderを学習させた場合。下の図の2列目
- post-hoc learned inference : 2段階で学習させる場合。1段階目は、GANと同様にDecoderとDiscriminatorを学習させ、2段階目はDecoderは固定してEncoderとDiscriminatorで学習を進める。ALIのようにEncoderとDecoderの相互作用が学習中に発生しない。下図の3列目
- VAE : 下図の4列目
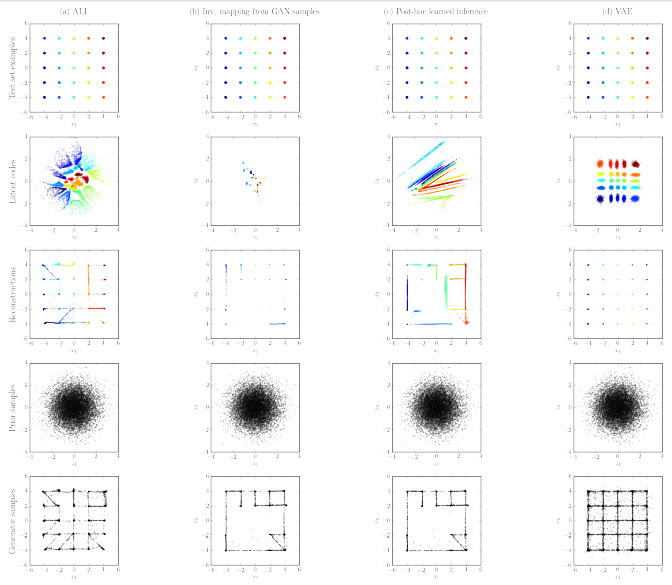
- 2行目の結果をみると、ALIは、$q(z)$の分布が、$p(z)$の分布にかなり良くマッチしている。他手法は部分的にしかマッチしておらず、カバレッジが低い
- learned inverse mappingやpost-hoc learned inferenceは、$p(x)$の分布(5行目)においても、$q(z)$の分布においても(2行目)、再構築で得た$p(x)$の分布においても、元の分布をカバーできていない。
- VAEはすぺてのモードをカバーできており、再構成性能もよい。一方で、$q(z)$の分布(2行目)や、$p(x)$の分布(5行目)においては、元の分布と異なった分布になっている。
論文を読んでの感想
- ALIの構成においても、Adversarial trainingが有効に働くことがわかったが、他手法によるデータセットの画像生成や再構成の結果も比較として見たかった
- 学習させたデータセットの類似画像がサンプルできるのはGANと同様であるが、画像の再構築となるといまいちな例(画像に移っている物体自体が異なるものを再構築)もいくつかあり、まだまだEncoder/Decoderのマッピングの改善が必要だと思う。ALIでは再構築のマッピングの関係はロス関数に反映されていないので、ロス関数にいれると改善するかと思った。
- データの再構築を利用した応用例としては異常検知があるので、そのあたりの改善手法としても今回の手法は使えるのかもしれない。
- GANのデータ生成の面だけでなく、潜在ベクトルをどう利用するかにも興味があって読んだ論文だが、似た研究としてBiGAN[4]もあるので違いを含め今後見てみたい。
参考文献
[1] Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Alex Lamb, Martin Arjovsky, Olivier Mastropietro, and Aaron Courville. Adversarially learned inference. OpenReview, 2016.
https://openreview.net/pdf?id=B1ElR4cgg
[2] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv:1511.06434, 2015.
https://arxiv.org/pdf/1511.06434.pdf
[3] Tim Salimans, Ian J. Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved Techniques for Training GANs. NIPS, 2016.
https://papers.nips.cc/paper/6125-improved-techniques-for-training-gans.pdf
[4] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial feature learning. arXiv:1605.09782, 2016.