ICLR 2018で発表された論文「SEMANTICALLY DECOMPOSING THE LATENT SPACES OF GENERATIVE ADVERSARIAL NETWORKS」[1]の概要まとめです。
GANの一種であるSD-GANsの提案論文です。
概要
- 特定の対象(人物や製品)を固定しながら、ポーズや照明といった写り方にバリエーションをもたせた画像を生成することができるSemantically Decomposed GAN (SD-GANs)の提案
- GANの潜在表現を、画像の写った特定の対象を表すidentity(e.g. 個々の人物)の部分と、写り方を表すobservation(e.g. 照明、ポーズ、背景)を表す部分に分解する
- DCGANもしくはBEGANをベースとして、画像の真偽に加えて与えられた画像ペアが同一のidentityであるかを判定基準としてDiscriminatorに学習させる
- 提案手法から生成した画像を、顔画像データセットと靴画像データセットで定量的・定性的に評価した
提案手法とネットワーク構成
GANにおいて画像を生成するGeneratorは、低次元特徴に相当する潜在表現$z$をもとに画像を生成($z$から画像へのマップ)するが、SD-GANsの構成ではこの潜在表現$z$を分解して、identityを表す部分を$z_{I}$、observationを表す部分を$z_{O}$として$z = [z_{I} ; z_{O}]$を考える。
Generatorはidentity部分を固定した状態でobservation部分を変えると、$G(z_{1}), G(z_{2}) \sim P_{G}( z | Z_{I}=z_{i})$となって同じidentityを指定した偽画像のペアを生成することになる。一方、同じidentityをもつ本物の画像のペアは$x_{1}, x_{2} \sim P_{R}(x | I=i)$となる。
Discriminatorは、この本物と偽物それぞれの画像ペアの真偽を判定する。通常のGANであれば、真偽の判定のみだが、SD-GANsの構成は同じidentityかどうかを判定基準に取り入れる。つまり、Discriminatorは次の2つのいずれかの条件に該当する場合に偽と判定する。
(1) Generatorが生成した偽画像のペアである
(2) 同じidentityの画像ペアではない
真と判定させるのは、本物ペアかつ同じidentityであるとき。
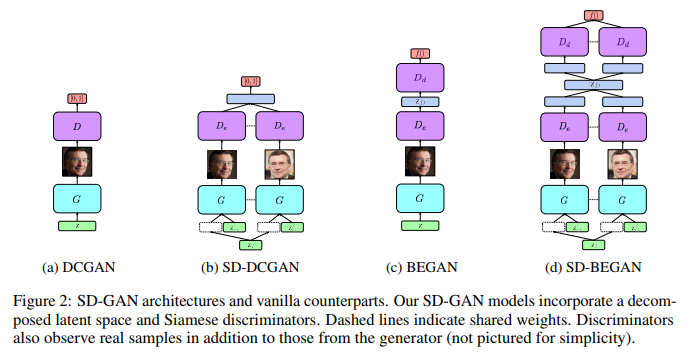
この関係を模式的に表したものが、下記のFigure 2である(SD-GANsは(b)および(d))。
点線で結ばれているコンポーネントはパラメータ重み共有となっている。
この構成におけるロス関数と、学習アルゴリズムは以下の通り。
identityが同一の画像ペアをGeneratorおよび本物画像(同一identityかわかるように準備が必要)から取得して、それぞれfake、realのラベルを与えてパラメータを更新する。
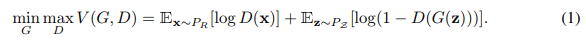

ネットワークアーキテクチャーはFigure 2にあるように、DCGANとBEGAN(※)を使ったものの2種類が提案されている。SD-GANsでは、画像の真偽に加えて、ペアのidentityの同一性も判定するので、Discriminatorは2つで構成する(Generatorは変更なし)。それぞれのDiscriminatorが画像を1枚ずつ受け取って、その両方からエンコードされた特徴にさらにもう1層畳み込み層をかませて真偽を判定する。このペアのデータを与えて類似性を評価するという構造は、過去に提案されたSiamese Networks(※)の構成をヒントにしているという。
※ BEGAN(Boundary Equilibrium Generative Adversarial Networks)[2]
Discriminatorがオートエンコーダーの形をとっており、入力と復元の誤差の分布のWasserstein距離ベースのロス関数にすることで、画像の高画質化と学習安定化を図ったGAN
※ Siamese Networks[3]
重みを共有した2つのネットワークに、ペアのデータを入力し同一かどうかを学習の対象とする。
実験
提案手法を定量的・定性的に評価する。
2つのデータセットで実験
(1) Faces : MS-Celeb-1M
有名人の顔画像データセット。12500を選んで、各人ごとに8枚の画像を選択して使用
(2) Shoes : Amazon dataset
Amazonが収集した靴製品のデータセット。約3000種の靴の写り方の方向や距離を変えたものを使用
画像生成結果
SD-BEGANとSD-DCGANの生成結果。いずれもidentityの$z_{I}$を固定して、observationの$z_{O}$を変化させて生成している。


定量的評価
-
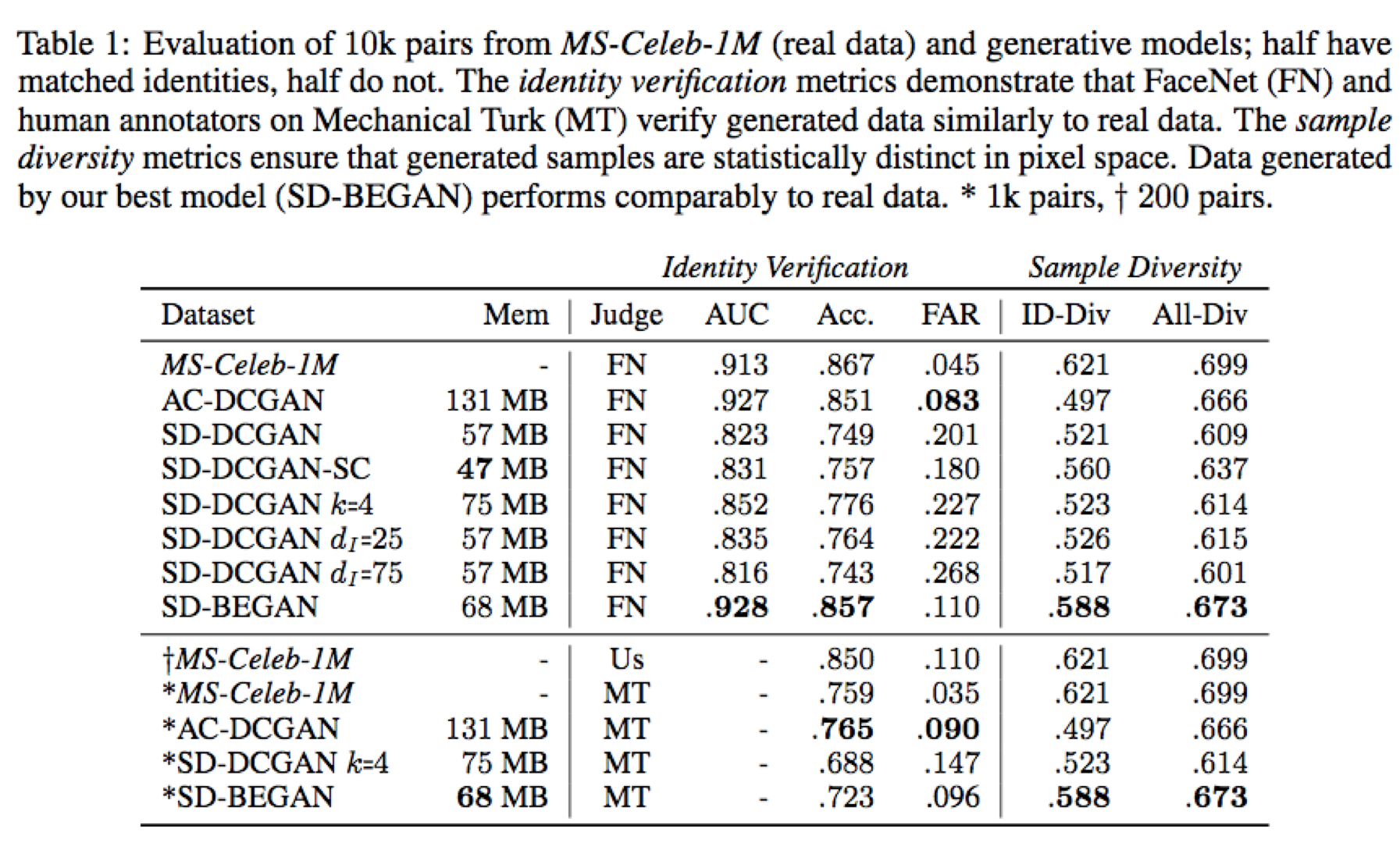
Facesのデータセットから、同じidentityの5000ペアと異なるペア5000の本物データを用意。
またSD-GANで同じ$z_{I}$から5000ペア、異なる$z_{I}$で5000ペアを生成($z_{O}$はランダムにサンプリング)。 -
$z$は一様分布から100次元のベクトルとしてサンプリングして使用し、$z_{I}$はその内50次元とする。
比較対象として、AC-DCGANという手法や、SD-DCGANの$z_{I}$の次元を25、75と変化させた場合、Discriminatorが判定する画像数($k$)を2から4に増やした場合を比較している。
※その他の詳細なアーキテクチャーや学習パラメータは論文参照 -
MS-Celeb-1Mを対象に、顔画像で学習させたFaceNet(※)[4]で同一の人物の画像であるか判定する。
FaceNetは画像から特徴を抽出するので、画像ペアの特徴量の$L_{2}$距離を非類似度(値が小さい方が類似)として扱い、閾値以下であれば同じ人物であると判定する。
AUCおよび、ある閾値の場合のFAR(False Acceptance Rate、同一ペアでないのに誤って同一と判定した率)で画像ペアの同一性判定を精度評価する。 -
もう1つ、手法の評価として生成画像の多様性を評価する。
指標としてペア画像の類似度を測るMS-SSIMを使う。MS-SSIMは$0$ ~ $1$の間の値をとり$0$に近いほど類似度が高い。
identityがマッチした画像ペアのMS-SSIMの平均を$1$から引いたものをID-Div、また、identityをランダムに選んだ画像ペアのMS-SSIMの平均を$1$から引いたものをAll-DivとしてTable 1に示している。
結果は、FARを除く指標でSD-BEGANが最良となっている。
※ FaceNet
類似した顔画像を学習させ、画像から特徴量を抽出(低次元空間へのマップ)する手法。特徴量を使って類似度計算やクラスタリングを行う。
定性的評価
- 人間に実際に画像ペアを見せ、同一人物かどうかを判定する(FaceNetでやったことの人版)。
Amazon Mechanical Turkというクラウドソーシングの一種のよう。
上記Table 1の下段が結果だが、AC-DCGANが最良であり、SD-GANsは及ばず。しかしながら、画像の多様性ではSD-GANsの方が高いので、多様性があるからこそ人間の目でみたときは同一判定の精度が低くでているのではないかと著者らは推測している。
論文を読んだ感想
- 対象を固定しながら、ポーズなどのバリエーションを変えて生成したいという応用場面はありそう
- $z$の分布を事前に指定しなくてよいというGANの良さは残しているし、 (論文中でも言及していいるが)conditional GANのように、ラベルを別途用意しなくて良い(同じidentityかどうかは必要)のでラベル付けの手間削減や、クラス数にともなうパラメータ数増大はさけられる
- ラベルが入力にない分学習後、画像のidentityを取り出す仕組み(Encoderなど)が必要になりそう
- $z_{I}$の次元を増やすと、identityを重視して生成されるのでFaceNetの判定精度が良くなると思ったがそうなっていないし、かといってdiversityが向上しているわけでもない(Table 1)点は興味深い
参考文献
[1] Chris Donahue, Zachary C. Lipton, Akshay Balsubramani, and Julian McAuley. SEMANTICALLY DECOMPOSING THE LATENT SPACES OF GENERATIVE ADVERSARIAL NETWORKS, arXiv, 2018.
https://arxiv.org/pdf/1705.07904.pdf
[2] David Berthelot, Tom Schumm, and Luke Metz. BEGAN: Boundary Equilibrium Generative Adversarial Networks. arXiv, 2017.
https://arxiv.org/pdf/1703.10717.pdf
[3] Jane Bromley. Signature Verification using a "Siamese" Time Delay Neural Network. NIPS, 1994.
https://papers.nips.cc/paper/769-signature-verification-using-a-siamese-time-delay-neural-network.pdf
[4] Florian Schroff, Dmitry Kalenichenko, and James Philbin. FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv, 2015.
https://arxiv.org/pdf/1503.03832.pdf