やること
-
Andrew Ng 教授 が Founder を務めている DeepLearning.AI が新しく動画を3本公開しました
- LangChain for LLM Application Development
- How Diffusion Models Work
- Building Systems with the ChatGPT API
-
何れも大規模言語モデル(LLM)を使用した、アプリケーション開発のオンライン講座になります
-
ただし、現時点 (2023/6/4) で文字起こし機能(以下の青枠で囲った "TRANSCRIPT" ボタン)が使えないため、動画の文字起こしと、日本語への翻訳を Whisper と DeepL API を使って実施します
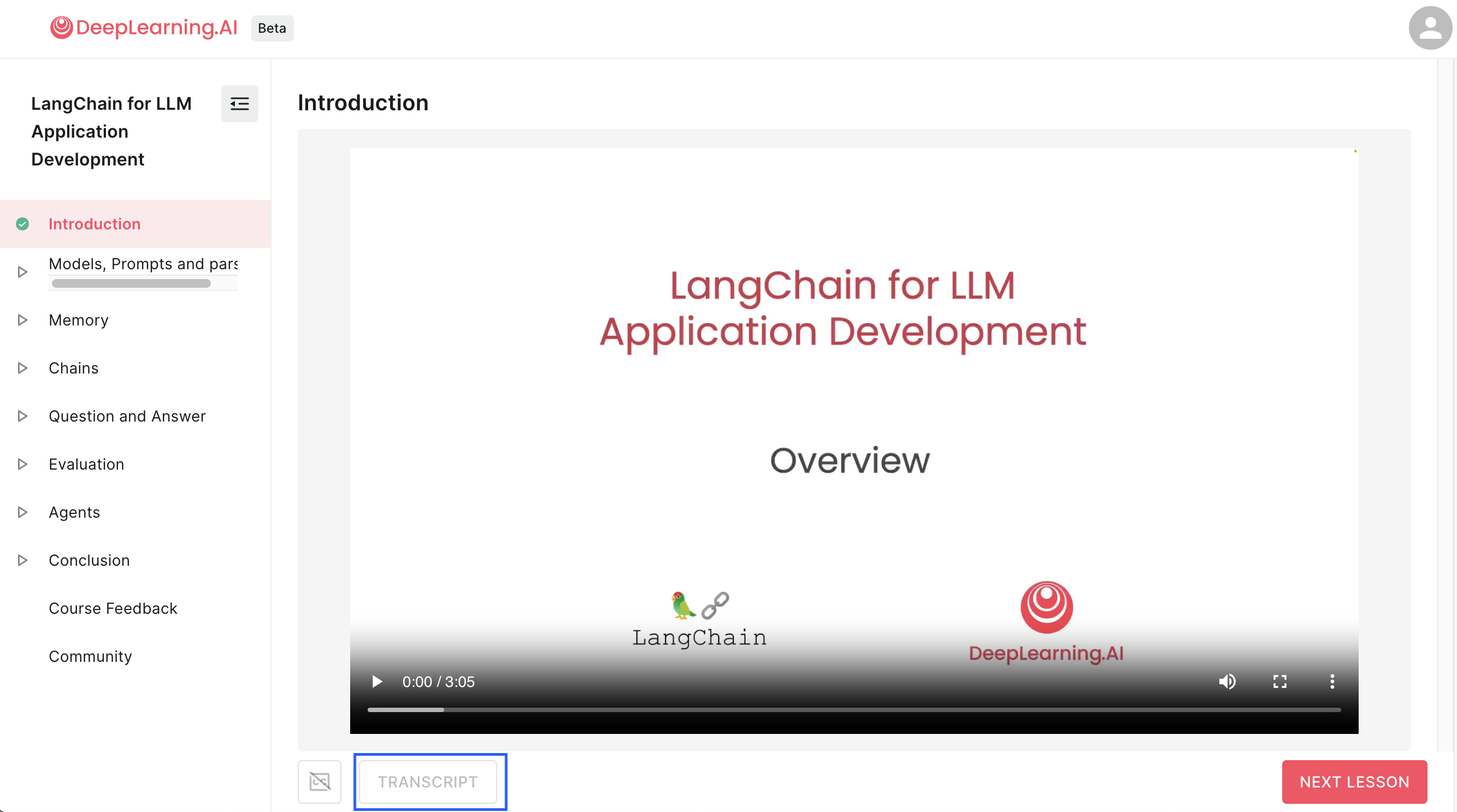
-
実行環境は、無料の Google Colaboratory 上で行います
概要
- 動画のダウンロード & 音声データへ変換
- 音声ファイルの文字起こし
- テキストデータの翻訳
- ファイル出力
- 結果の確認
1. 動画のダウンロード & 音声データへ変換
-
動画の右下「︙」を押下すると "Download" が選択できるので、これで動画ファイルをダウンロードします
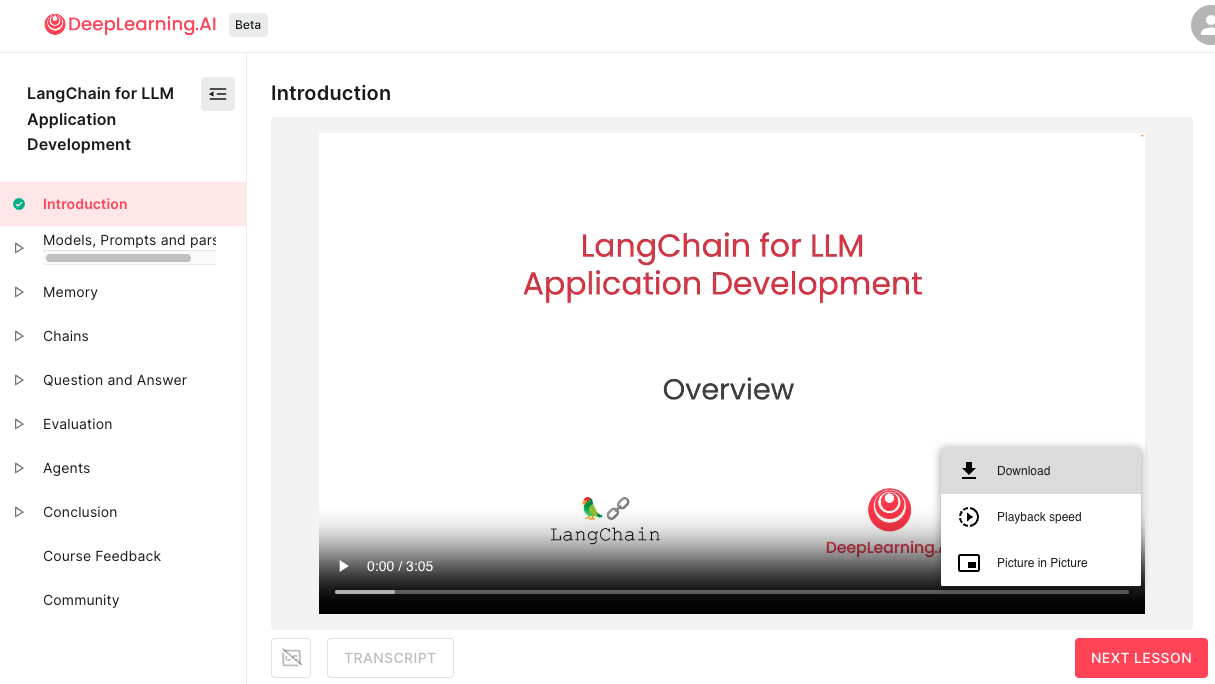
- 全動画をダウンロードした後、これらを音声データに変換していきます
先にダウンロードしたファイル名の先頭に連番を付与しています(0_XXX.mp4, 1_YYY.mp4)
そのあと、私は オーディオコンバータ というサイトで mp4 -> mp3 ファイルへ変換しました - この mp3 ファイルを Google Drive 上の任意のフォルダにアップロードしておきます
(後で Google Colab 上から利用します)
2. 音声ファイルの文字起こし
-
各 mp3 ファイルを OpenAI が公開している 自動音声認識システム(automatic speech recognition (ASR) system) である Whisper を使って文字起こしします
-
Google Colab を起動し、ランタイムのタイプを GPU へ変更しておきます
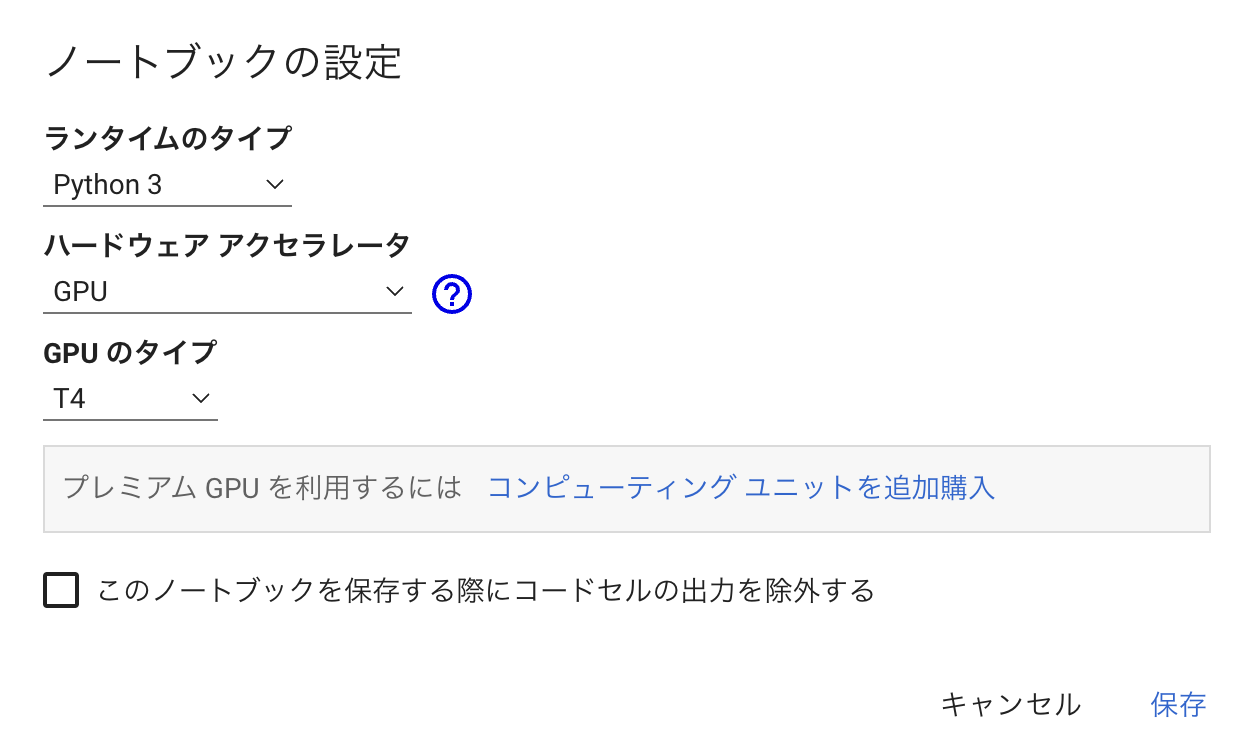
-
Whisper をインストールします
!pip install git+https://github.com/openai/whisper.git
- Whisper の文字起こしに使うモデルを選択します
今回は 'base' を使用していますが、以下 のように複数のモデルがあります。
model = whisper.load_model("base")
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
- #1 で格納した mp3 ファイルのパスを取得します
Google Drive をマウントし、その後に mp3 の全ファイルのパスを取得します
# mount google drive
from google.colab import drive
drive.mount('/content/drive')
# file path
files = glob.glob("/content/drive/My Drive/<#1のmp3ファイル格納先フォルダ>/*.mp3")
- 全ファイルの文字起こしを実施します
#1 でファイル名の先頭に連番を振っていましたが(0_XXX.mp3, 1_YYY.mp3)、この先頭の数字を results (dict 型) のキーとしています
results = {}
# transcription of all file
for file in files:
results[(os.path.basename(file))[:1]] = model.transcribe(file)
3. テキストデータの翻訳
- 文字起こしされたテキストデータを日本語に翻訳します
- 翻訳は、DeepL が公開している「DeepL API Free」というAPI経由で利用できるサービスを使います
1か月に50万文字まで無料で翻訳できます - 「DeepL API Free」を利用するためには、DeepL のアカウントを作成して API キーを取得する必要があるので、以下のサイトを参考にしました。
- DeepL をインストールします
!pip install --upgrade deepl
- 取得した API キーを使って、翻訳を実行します
Translator の使い方は GitHub を参照
# preparing the translator
auth_key = "<DeepL API 認証キー>"
translator = deepl.Translator(auth_key)
results_ja = {}
# translation of all data
for key in results.keys():
results_ja[key] = translator.translate_text(results[key]["text"], target_lang="JA").text
4. ファイル出力
-
結果をテキストファイルへ出力します
(英語の場合は「.」(ピリオド)の後、日本語の場合は「。」(読点)の後に改行を入れています) -
出力先を指定(任意のフォルダ)
# output path
out_path = "/content/drive/My Drive/<#1のmp3ファイル格納先フォルダ>/output-text/"
- 文字起こしした英語のテキストを音声データ別に出力
for key in results.keys():
tmp = results[key]['text'].replace('. ', '.\n')
with open(out_path + str(key) + "_en.txt", 'w', encoding='utf-8') as f:
f.write(tmp)
- 文字起こし & 翻訳した日本語のテキストを音声データ別に出力
for key in results_ja.keys():
tmp = results_ja[key].replace('。', '。\n')
with open(out_path + str(key) + "_ja.txt", 'w', encoding='utf-8') as f:
f.write(tmp)
5. 結果の確認
- ざっと見てみると、以下のような新しい単語?が正しく文字起こしされていないですが、概ねよさげな気がします。。。
- Lanchane -> LangChain
- LLO -> LLM
0_en.txt
Welcome to this short course on Lanchane for large language model application development.
By prompting an LOM or large language model is now possible to develop AI applications much faster than ever before.
But an application can require prompting an LOM multiple times and parsing as output.
・・・
0_ja.txt
大規模言語モデルアプリケーション開発のためのLanchaneに関するこのショートコースへようこそ。
LOMや大規模言語モデルをプロンプトにすることで、AIアプリケーションをこれまでよりずっと速く開発することができるようになりました。
しかし、アプリケーションでは、LOMを何度もプロンプトし、出力としてパースする必要があります。
・・・
ソースコード (GitHub)
(2023/06/06 追記) 各動画の翻訳結果
LangChain for LLM Application Development
(LangChain による LLM アプリケーション開発)
- Introduction
- Models, Prompts and parsers
- Memory
- Chains
- Question and Answer
- Evaluation
- Agents
- Conclusion