はじめに
Lambda@Edge(以後、L@E)で、bodyの一部を書き換えてレスポンスを返す方法についてまとめました。
L@Eでbodyを書き換えるには、ビューアーリクエストもしくはオリジンリクエストで可能です。2つの違いは以下になります。
ビューワーリクエスト
- CloudFront がビューワーからリクエストを受け取ると、リクエストされたオブジェクトが CloudFront キャッシュにあるかどうかを確認する前に関数が実行されます。
オリジンリクエスト
- CloudFront がリクエストをオリジンに転送したときにのみ、関数が実行されます。リクエストされたオブジェクトが CloudFront キャッシュ内にある場合、関数は実行されません。
L@Eでbodyを書き換える際の制限は他にもあり、下記のドキュメントに記載されています。
L@Eのリクエストボディへのアクセスの例になります。
やりたいこと
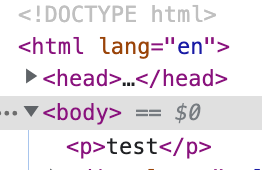
リクエスト時、L@Eによって、bodyタグ内の<body>直下に<p>test</p>を追加し、レスポンスをする。
特定のビヘイビアのみにL@Eを有効にすることで、特定のパスのみ、body内を修正した内容をレスポンスすることができます。(今回は、<p>test</p>を追加)
理想は、レスポンス時にL@Eでできれば良いのですが、前述の通り、bodyの読み書きは、リクエスト時にしかできません。
実現方法
L@Eでは、オリジンレスポンスやビューアーレスポンスでは書き換えができないため、今回はオリジンリクエストをトリガーとし、sync-requestを使用します。
sync-requestモジュールは、同期処理でHTTP通信を行うことができ、同期処理というのがポイントになります。
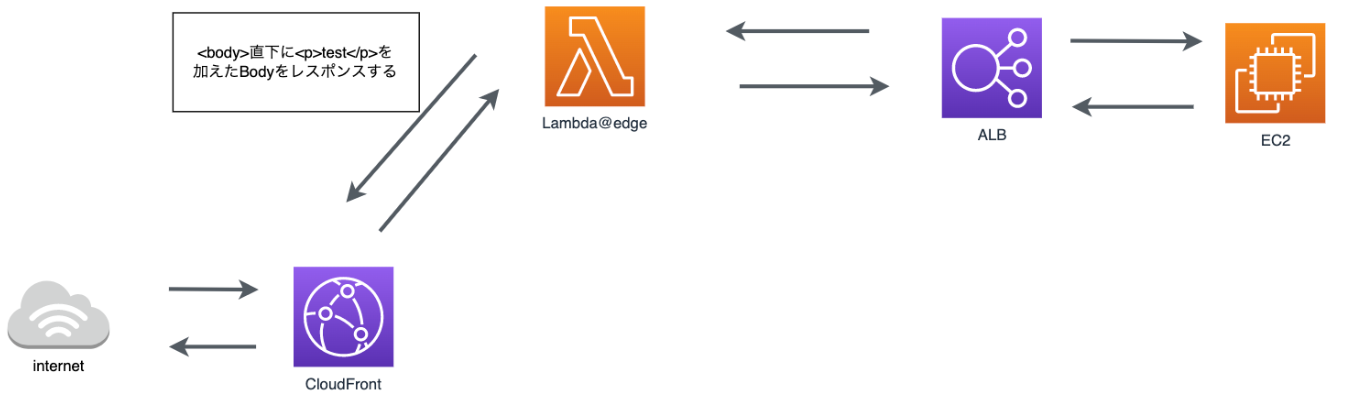
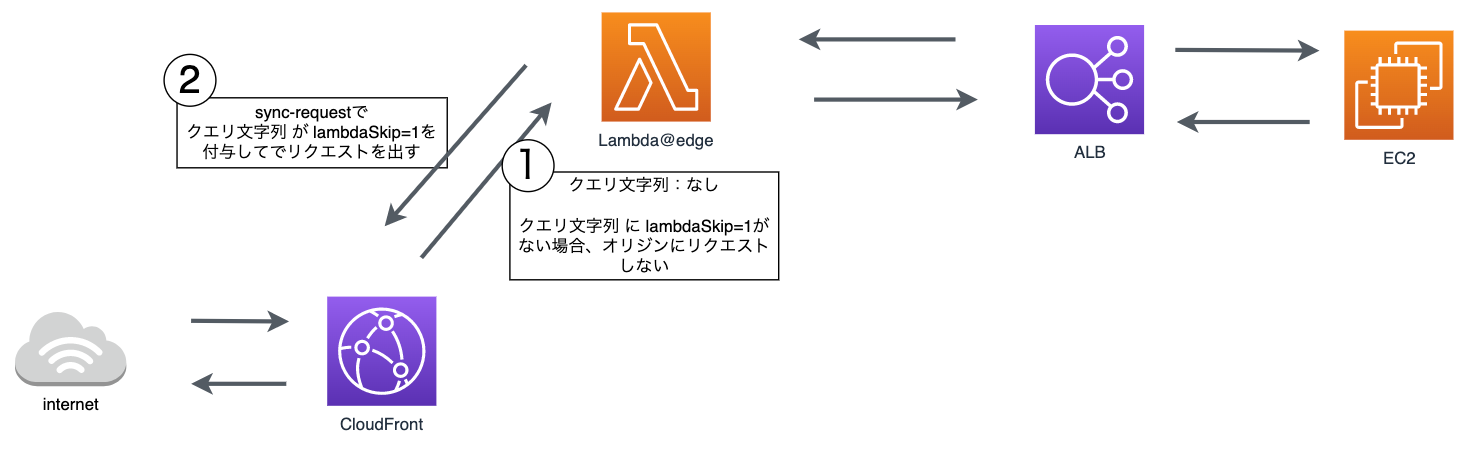
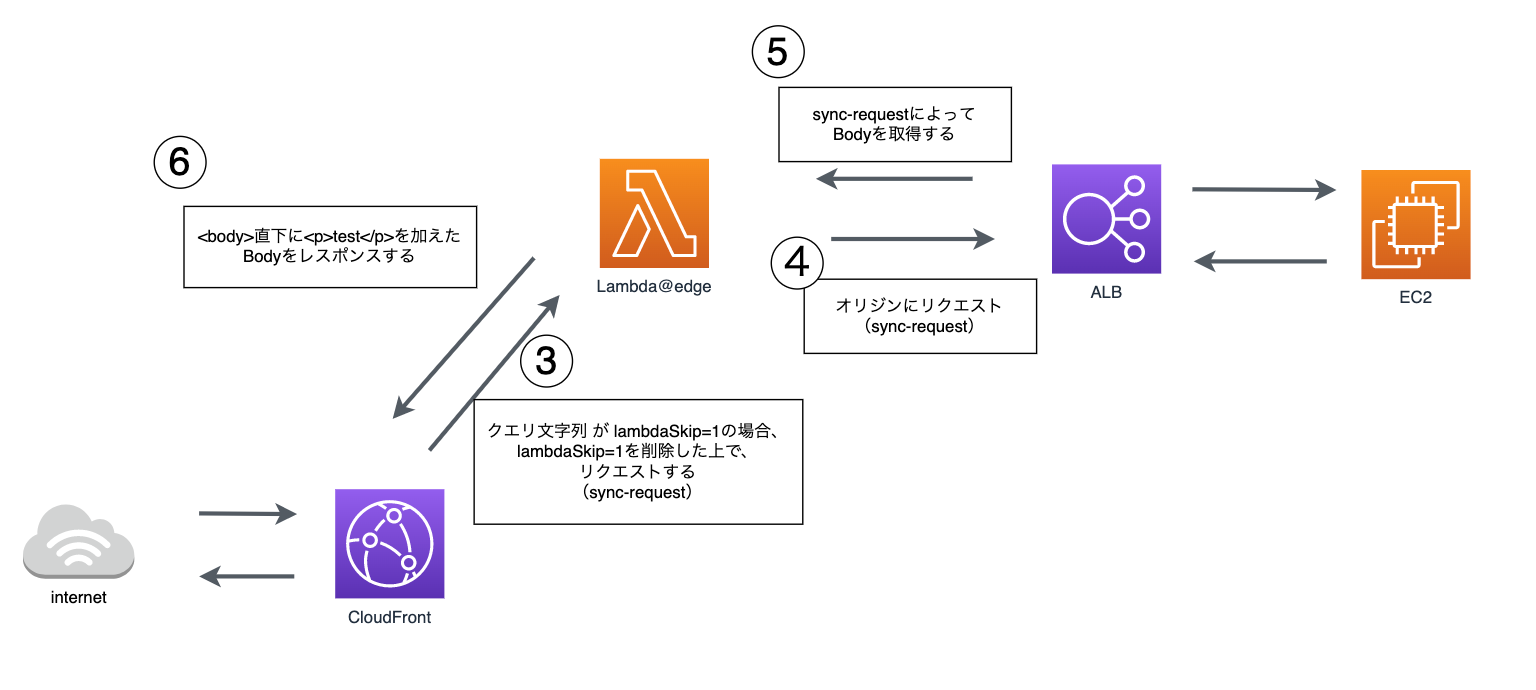
L@Eの処理の流れについて説明します。
- リクエストが来た際、CloudFrontのL@Eがトリガーされ、
sync-requestによって同じurlにリクエストします。その際、L@Eはオリジンへのリクエストはせず、sync-requestの処理を待ちます。 -
sync-requestで同じurlでリクエストする際、クエリ文字列で任意の文字列を付与します(今回は、lambdaSkip=1) -
sync-requestによって、① と同様にCloudFrontのL@Eがトリガーされますが、L@Eでは、クエリ文字列としてlambdaSkip=1があった場合、lambdaSkip=1を外し、オリジンにリクエストする処理を行います。 -
sync-requestによってリクエストしたbodyがL@Eにレスポンスされます。 - L@Eは、受け取ったbodyを書き換え、オリジンにリクエストせず、レスポンスを返します。
この処理の流れについて、sync-requestがリクエストした(同期処理した)箇所は、②〜⑤であり、L@Eはsync-requestの②〜⑤の処理を待ち、⑥でレスポンスを返します。
図にすると以下の流れになります。
前提
- CloudFront,オリジン先を作成済み。今回オリジン先は、ALBです。
L@E作成
L@Eは、バージニア州で作成します。
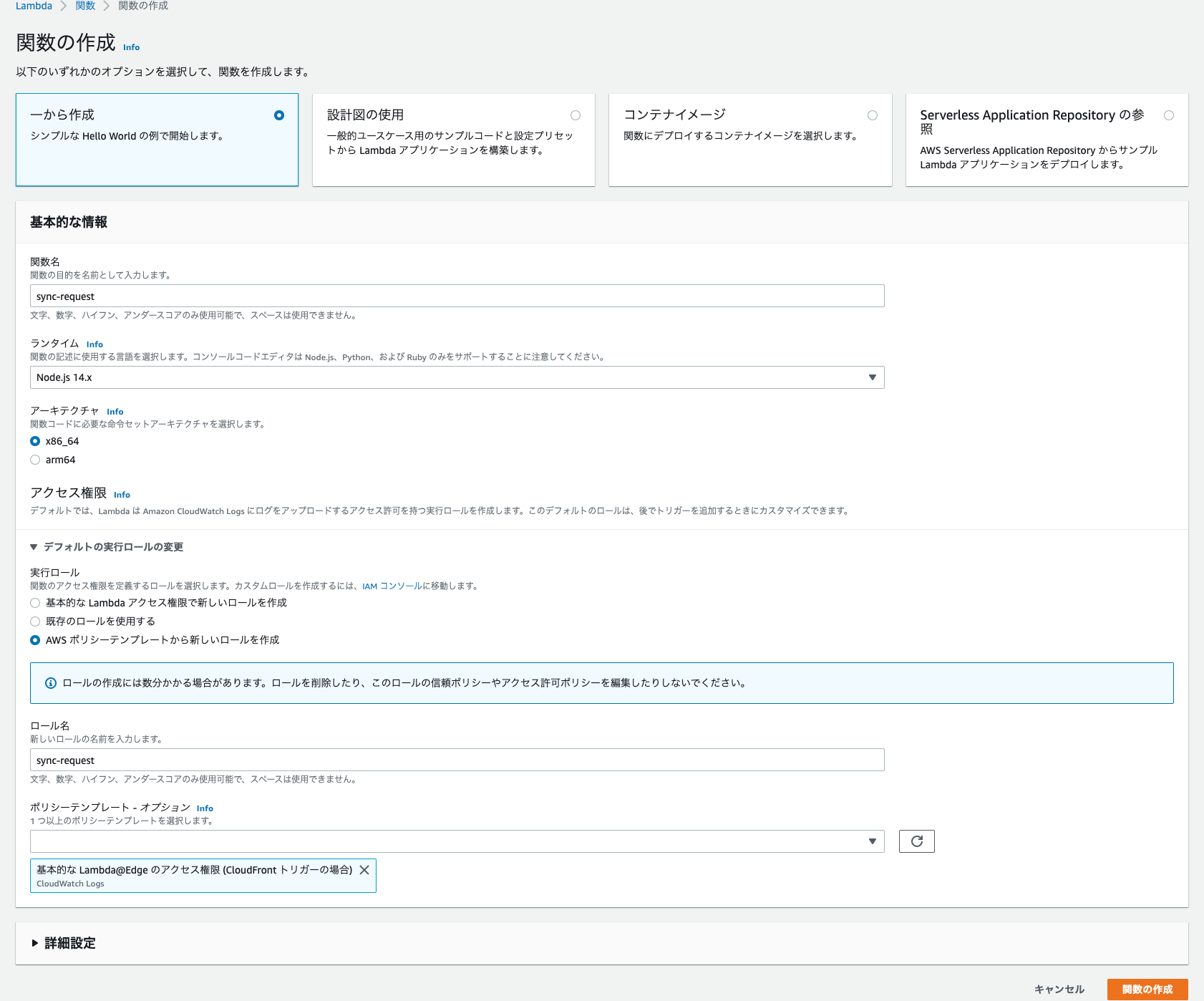
L@Eの実行タイムアウトは、3秒→30秒に変更します。
sync-requestモジュールをL@Eにアップロード
ローカルでsync-requestモジュールをインストールし、L@Eにアップロードします。
% mkdir nodejs
% cd nodejs
nodejs % npm i sync-request
added 40 packages, and audited 41 packages in 7s
6 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
nodejs % ls
node_modules package-lock.json package.json
nodejs % touch index.js
nodejs % ls
index.js node_modules package-lock.json package.json
nodejs % zip -r project.zip *
project.zipを作成したL@Eにアップロードします。
ディレクトリの配置は、以下のようになります。
index.js
index.jsに以下のコードを貼り付けます。
L@Eのオリジンリクエストの構造 (json形式のコード) を見ると理解しやすいかと思います。
また、Lambdaでテストする際のイベント構造は、以下のjson形式のコードをコピペするとよいです。

const host = "www.fuga.com";
const syncRequest = require("sync-request");
const { URLSearchParams } = require("url");
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
console.log("Received event:", JSON.stringify(request, null, 2));
const params = new URLSearchParams(request.querystring);
const lambdaSkip = params.get("lambdaSkip");
//クエリ文字列lambdaSkipがある場合、クエリ文字列を外して、オリジンにリクエストを出す
if (lambdaSkip) {
request.querystring = "";
callback(null, request);
} else {
// sync-requestがクエリ文字列lambdaSkip付きでリクエストを出す
const uri = request.uri;
const url = "http://" + host + uri + "?lambdaSkip=1"; // httpsでも可
const syncResponse = syncRequest("GET", url, { timeout: 28000 });
// sync-requestのレスポンスを受け取る
const syncResponseBody = syncResponse.getBody("utf8");
// 受け取ったレスポンスのbodyを書き換える
const bodyAddScript = "<body><p>test</p>";
const syncResponseBodyRewrite = syncResponseBody.replace(
"<body>",
bodyAddScript
);
console.log(syncResponseBodyRewrite);
const BodyRewriteResponse = {
status: 200,
statusDescription: "OK",
headers: {
"content-type": [
{
key: "Content-Type",
value: "text/html; charset=UTF-8",
},
],
},
body: syncResponseBodyRewrite,
};
// bodyを書き換えたものをレスポンスする
callback(null, BodyRewriteResponse);
}
};
index.jsの一部コード解説
const { URLSearchParams } = require("url");
const { } = は分割代入と言われています。
この{}はオブジェクトを参照していて分割代入は配列でも使うことができます。
例えば、以下のコードがあったとします。
const { apple } = { orange: 1, apple: 2, grape: 3 }
console.log(apple)
//2
これを実行すると、appleの値である2が表示されます。
また、require("url")は、以下の構造になっております。
console.log(require("url")) ;
//結果
{
Url: [Function: Url],
parse: [Function: urlParse],
resolve: [Function: urlResolve],
resolveObject: [Function: urlResolveObject],
format: [Function: urlFormat],
URL: [class URL],
URLSearchParams: [class URLSearchParams],
domainToASCII: [Function: domainToASCII],
domainToUnicode: [Function: domainToUnicode],
pathToFileURL: [Function: pathToFileURL],
fileURLToPath: [Function: fileURLToPath],
urlToHttpOptions: [Function: urlToHttpOptions]
}
つまり、URLSearchParamsの値が変数として定義されたということになります。
new URLSearchParams(string)
new URLSearchParams(string)は、stringをクエリ文字列として 解析し、それを使用して新しいURLSearchParamsオブジェクトをインスタンス化します。
今回の場合、stringは、lambdaSkip=1になります。
params.get("string")
params.get("lambdaSkip")は、lambdaSkipがあれば、1を返し、ない場合、nullを返します。
下記の記事では、クエリ文字列の様々な処理方法が記載されており参考になります。
L@Eデプロイ
後は、L@Eを特定のCloudFrontのビヘイビアにデプロイします。
ボディを含めるにチェックしてください。
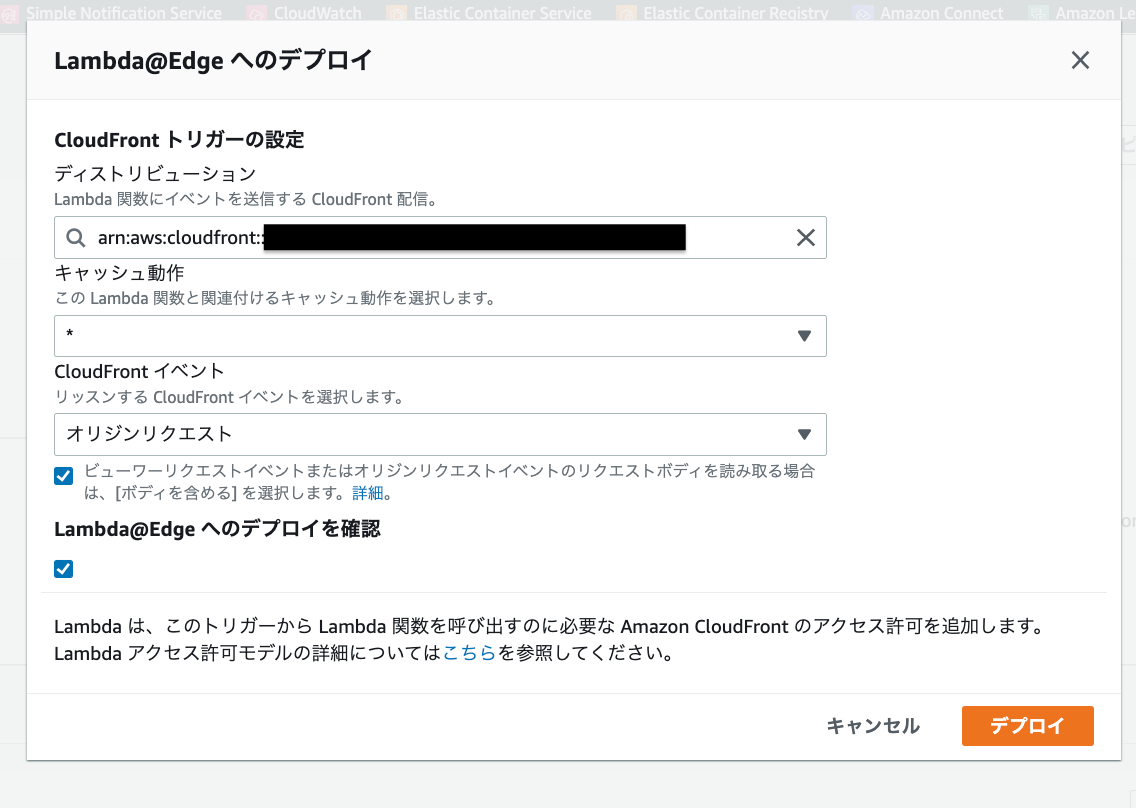
CloudFrontの設定
キャッシュポリシー
L@EにをデプロイしたCloudFrontのビヘイビアのキャッシュポリシーを修正します。
キャッシュポリシーで、クエリ文字列のlambdaSkipを含めるようにします。
これがない場合、クエリ文字列をつけてsync-requestでリクエストした際、lambdaSkipが付与した状態でキャッシュされます。
続いて、キャッシュされた状態でリクエストした場合、lambdaSkipが付与した状態のurlがレスポンスされてしまい、503が返されます。
そこで、キャッシュポリシーにクエリ文字列のlambdaSkipを含めることで、lambdaSkipがあるurlとないurlがそれぞれキャッシュされ、レスポンス時、lambdaSkipがない正常なものがレスポンスされます。
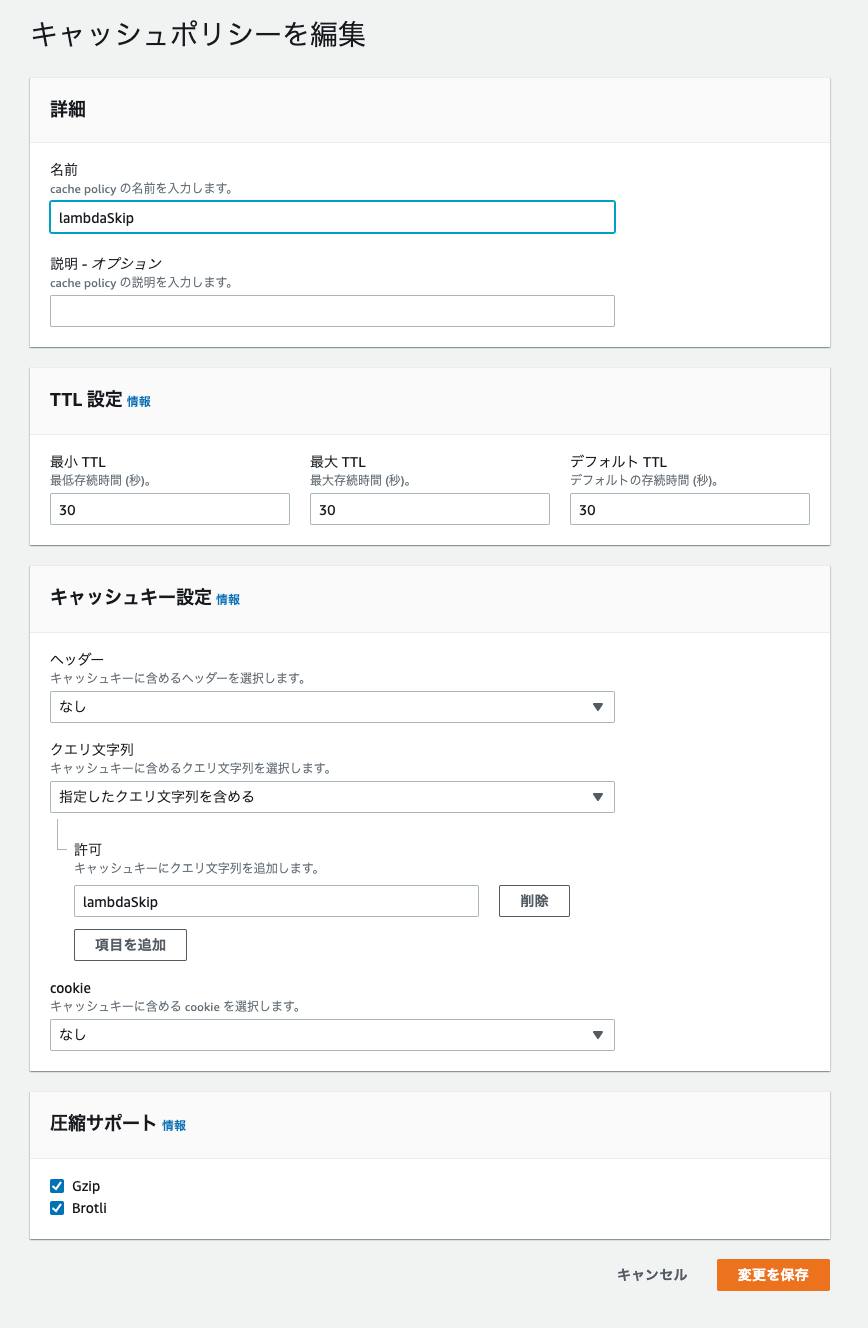
キャッシュの時間は何でも構いません。キャッシュ時間0でもよいです。
作成したポリシーをビヘイビアに反映させます。
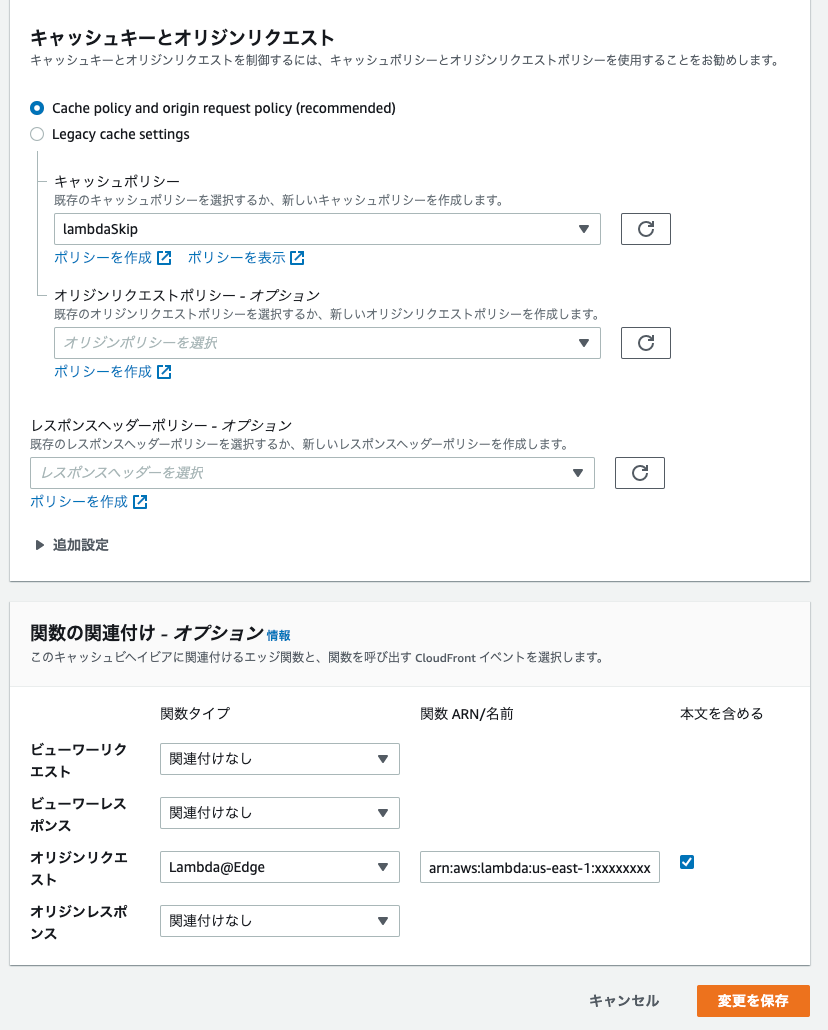
オリジンリクエストポリシー
オリジンリクエストポリシーは、あってもなくてもよいです。
アクセスしてみる
では、ブラウザにurlを記載し、にアクセスしてみましょう。
ビヘイビアで指定したパスでアクセスすると、<body>直下に<p>test</p>が付きました!
logの確認
ログは、エッジサーバーのリージョンでCloudWatchLogsで出力されます。
日本でリクエストした場合、東京リージョンにログが出力されるでしょう。
ブラウザで503エラーが出た場合、logを手がかりにでエラーの原因を特定しましょう。
Basic認証している場合
CloudFrontやALBでBasic認証もしくは、Bearer認証の設定をしている場合、sync-requestのヘッダーにAuthorizationと値を付与する必要があります。
- const syncResponse = syncRequest("GET", url, { timeout: 28000 });
const syncResponse = syncRequest("GET", url, {
timeout: 28000,
headers: {
authorization:
"Basic <token値>",
},
});
const syncResponseBody = syncResponse.getBody("utf8");
レスポンスまでの時間がかかる場合
L@Eの処理でsync-requestを使うと、レスポンスまでの時間が遅いと感じる場合があるかと思います。
その場合の対処法は、2つが挙げられます。
- L@Eのメモリのスペックをデフォルトの128MBから上げる。
- L@Eのコード内の
console.log()を削除する
参考