はじめに
こちらはzennの記事の転載となります。
sweeep CTOの平下です。先日CADDiさん主催のこちらで「BFFとmicroservicesアーキテクチャ」というテーマでLTさせていただきました。そのときのLT内容を記事にしました。
発表したスライドです。
以下記事の内容です。
- BFFとmicroservicesアーキテクチャ採用の背景
- GraphQL/BFF導入のメリットと課題
- まとめと今後の課題
1. BFFとmicroservicesアーキテクチャ採用の背景
モノリスなアーキテクチャ
プロダクトローンチから3年経過し、技術負債がかなりたまっていました。
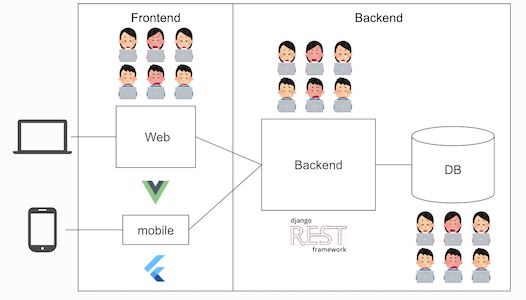
モノリスなアーキテクチャには以下の課題がありました。
- モノリスなアーキテクチャを同時修正でコンフリ
- 単一DBでデータの肥大化。マイグレーションなど大変
- 凝集度が低く修正箇所漏れ
そのためコンフリやデグレで開発速度低下や機能リリース遅れが生じていました。
microservicesアーキテクチャ
そこで、アーキテクチャーをmicroservicesアーキテクチャへ刷新しました。
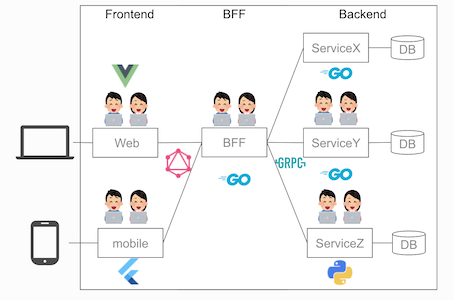
microservicesでモノリスなアーキテクチャの技術負債を以下のように解消しました。
- モノリスなアーキテクチャを同時修正でコンフリ
→ microservicesを少人数で各service修正 - 単一DBでデータの肥大化。マイグレーションなど大変
→ microservices毎にDBをもつ - 凝集度が低く修正箇所漏れ
→ 適切なドメインで凝集度上げる
microservicesの課題
しかし、microservicesにも以下のような課題があります。
- 複数DBにおける情報の集約化
ex. :支払情報とユーザ情報など別DB - 複数リソースにおけるFEの工数増・肥大化
ex. :上記支払情報にあるuser_idとユーザ情報を紐付け
そのため、以下のサンプルのようにBFFで情報の集約と紐付けを実施し、GraphQLで集約した情報を返すようにしています。
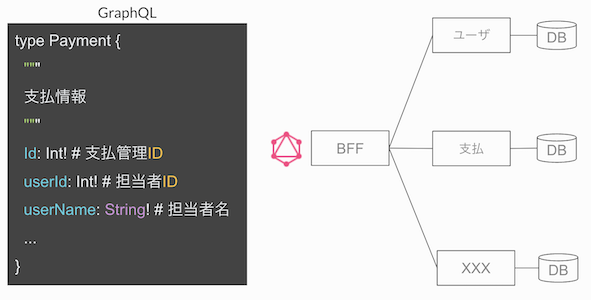
また、情報取得と同様に、更新でも複数リソース同時更新のユースケースもあります。
2. GraphQL/BFF導入のメリットと課題
GraphQLメリット
GraphQLのメリットとして、以下のメリットがあります。
- スキーマ駆動開発
- スキーマからClient/Server生成
- クエリライクで複数リクエストなしに情報を取得できる
以下スキーマ駆動開発とスキーマからClient/Server生成について説明します。
スキーマ駆動 & mockで並行開発
スキーマ駆動開発で、定義ファイルからクライアントとサーバーのプログラムを自動生成したものを使用し、クライアントとサーバー間で齟齬が生じないようにしています。また、定義ファイルを元にMockを作成することで、サーバーの開発が終わっていなくてもクライアントがMockへアクセスし通信部分の開発や動作確認できるようにしています。
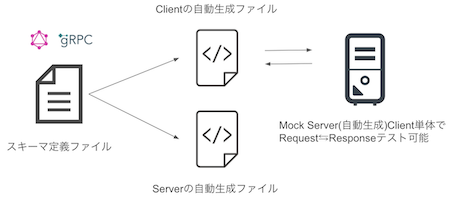
GraphQLスキーマからClient/Server生成
以下のサンプルのようにGraphQLスキーマからClientとサーバー(BFF)のプログラムを自動生成しています。
- Client (TS) → client/model生成
$npm run graphql-codegen --config ./path/to/config.yml
- config.yml
/schema: http://localhost:3000/graphql
documents: ./src/**/*.graphql
generates:
./src/types.ts:
plugins:
- typescript
- typescript-operations
- BFF (Go) → resolver/model生成
$go run github.com/99designs/gqlgen generate
- gqlgen.yml
schema: "*.graphql"
exec:
filename: generated.go
model:
filename: models_gen.go
resolver:
type: Resolver
layout: follow-schema
dir: .
models:
...
BFFメリット
BFFのメリットとして、以下のメリットがあります。
- 各microservicesリソースをFEの必要な情報に束ねて返す
- EndpointがBFF一箇所で済む
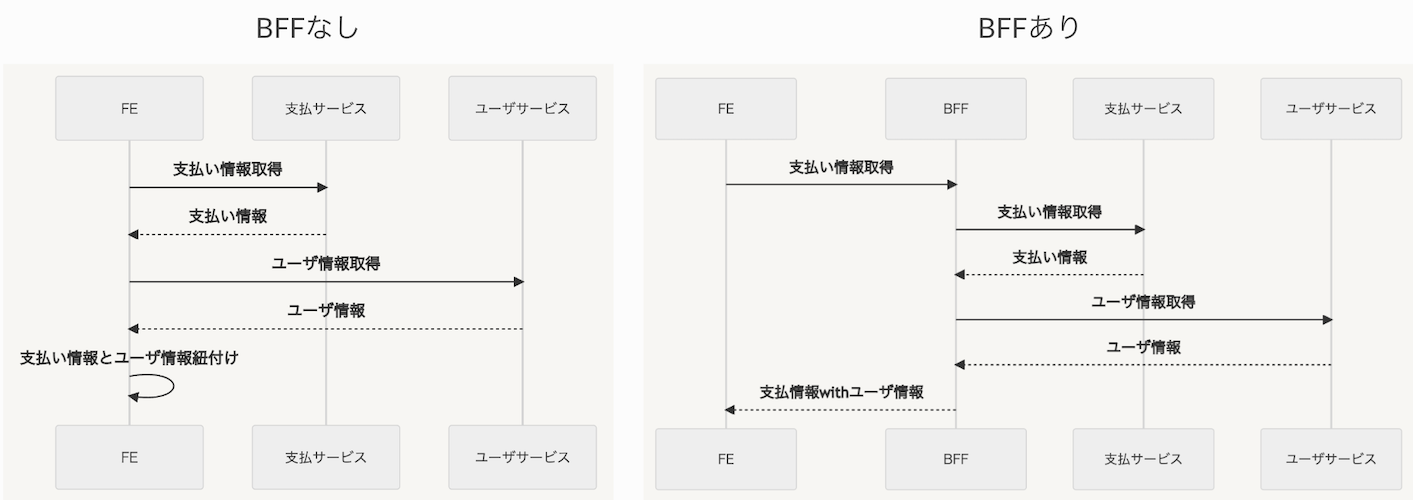
BFF無とBFF有の比較 (情報の集約)
以下のサンプルのように、BFFがない場合はUser情報と支払い情報をそれぞれ取得して、FEで情報の紐付けが必要です。
BFFがある場合はUser情報 + 支払い情報を束ねることで、FEで情報の集約が必要なくなります。
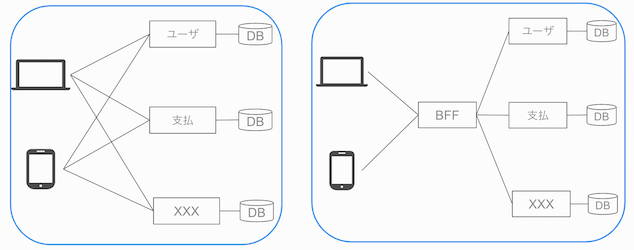
BFF無とBFF有の比較 (Endpointの集約化)
以下のように、BFFがない場合はクライアントがそれぞれのBE (microservices)を意識する必要があります。
BFFがある場合は、Endpointは集約されているのでクライアントはBFFへリクエストを投げれば良いです。
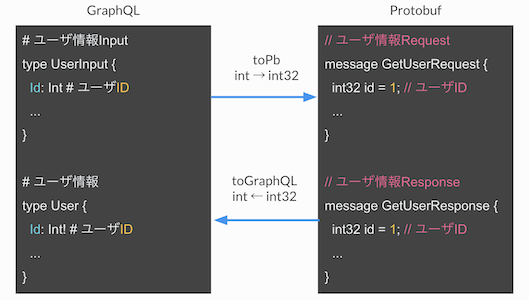
GraphQLの課題
クライアント ↔ BFF通信ではGraphQL、BFF ↔ BE通信ではgRPC(Protobuf)を採用していますが、GraphQL ↔ Protobufの値の詰め替えが発生します。
- Request: model.xxxInput → pb.xxxRequest
- Response:model.xxx ← pb.xxxResponse
たとえば、GraphQLではintしかサポートしていないがProtobufだとint32/64の場合、以下のようにユーザIDの値の詰め替えが発生します。
BFF課題
BFFにも以下のような課題があります。
- BFF開発分の工数増・メンテ増
- ただmicroservices → BFF → FEと透過的に情報を渡しているだけで冗長に感じることがある
- 反面、BFFでいろいろやらせる(=やらせたくなる)とFatになるので気をつける
もっとBFFを薄く作った方がよかったかな、と思います。
3. まとめと今後の課題
まとめ:GraphQL & BFFメリット
以下GraphQL & BFFメリットのまとめになります。
- GraphQLはスキーマ駆動・情報の集約という点でメリット
- BFFはmicroservicesの仲介役・Endpointの集約でメリット
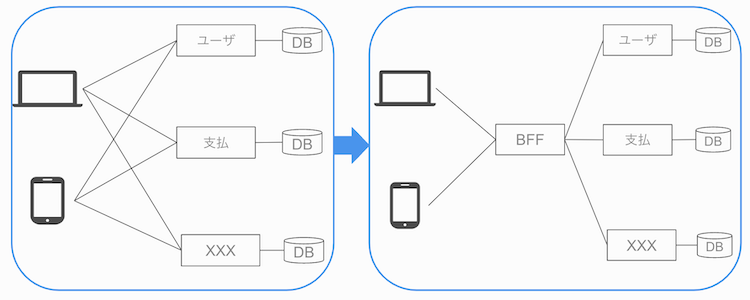
また、BFFを後から入れるのは以下のようにインパクトが大きく最初に決断してよかったと思います。
- BFFの新規開発
- スキーマやEndpoint変更に伴うクライアント側の対応工数
- インフラや運用の追加など
今後の課題
- BFF開発分の工数増で冗長に感じることも多いが、ない場合はFEで頑張らないといけなかったりする。
→ 次回適用する際はGraphQL Gatewayなど検討したい。 - GraphQL & BFFは現在Web & Mobile共通のため、同時リリース。
→ 共通化やアジリティを下げない仕組みに課題。
おわりに
今回はBFFとmicroservicesアーキテクチャに採用したGraphQL/BFFのメリットとその課題について説明しました。
私はBFF/BEの開発を担当しており、少人数での開発だったためBFF開発の工数は結構きつかったです。しかし、後から入れるのは恐らく難しいだろう、と最初に導入を決めました。その判断はある程度正しかったとは思います。
ただ、アーキテクチャにも「銀の弾丸」はないので今後も改善し続けていきたいと思います。
ここまで読んでいただきありがとうございました!