Mupdf ライブラリとは?
Mupdf は PDF を操作するのに必要な機能を統合したフレームワークです。
オープンソースであり、自分のアプリに PDF をプレビューする機能を簡単に取り込んだり、PDF ファイルをパースして、何か処理を加えて書き出す事も出来ます。
Mupdf ライブラリは C 言語で書かれていますが、C++ で利用して、使う為の基本的な情報をまとめておきます。
※実装を見る限り、C++ 的設計を前提にしており、何故わざわざ C で実装されているのか不思議ですが、作者のこだわりなのでしょう・・
Mupdf ライブラリをインストールする
この方法は、MSYS2 上の clang64 環境を想定した解説ですが、OS-X、Linux でも同じように扱えると思います。
Mupdf ライブラリは、他のライブラリに強く依存しているので、それらのインストールが必要です。
又、このライブラリは、かなり古くからあり、更新が続けられて、機能が向上した事により、API の仕様が変更になり、昔のコードがコンパイル出来ないなどもあります。
ネットにあるサンプルは、古いバージョンのコードである場合などもあり、正しく動作しない(クラッシュしたり・・)場合もあります。
- MSYS2 では、pacman を使って、必要なライブラリをインストール出来ます。
- 昔は、自分でソースを取得してコンパイルしなければなりませんでした。
- 現代では、必要なパッケージは、pacman で全てインストール出来るようになっています。
- この記事は、2023年3月の状況を反映しています。
Mupdf 本体:
pacman -S mingw-w64-clang-x86_64-mupdf-libmupdf
- 本体には、「libmupdf、libmupdf-third」が含まれ、ライブラリをリンクする際指定します。
- 他に、「mingw-w64-clang-x86_64-mupdf-mupdf」があり、これは mupdf を使ったアプリケーションです。
- 他に、「mingw-w64-clang-x86_64-python-pymupdf」があり、これは、mupdf を python から利用する為の物のようです。
- また、利用する API によっては、必要なライブラリを追加でインストールする必要がありますが、ここでは、主に「fitz」と呼ばれる API 郡向けの解説です。
pacman -S mingw-w64-clang-x86_64-zlib
pacman -S mingw-w64-clang-x86_64-freetype
pacman -S mingw-w64-clang-x86_64-libpng
pacman -S mingw-w64-clang-x86_64-openjpeg2
pacman -S mingw-w64-clang-x86_64-libjpeg-turbo
pacman -S mingw-w64-clang-x86_64-gumbo-parser
pacman -S mingw-w64-clang-x86_64-jbig2dec
pacman -S mingw-w64-clang-x86_64-harfbuzz
- zlib は、定番の圧縮、解凍ライブラリです、libpng でも利用されます。
- freetype は、TrueType などのベクトルフォントをビットマップに変換するライブラリです。
- libpng は、PNG 画像を扱うライブラリです。
- openjpeg2 は、OpenJPEG 画像を扱うライブラリです。
- libjpeg-turbo は、JPEG 画像を扱うライブラリで、MMX 系命令を使って高速化する実装が入っています。
- 他の詳細は省きますが、Mupdf が使うライブラリです。
API の基本的使い方
- 良くあるのは、PDF ファイルを開いて、ビットマップ(RGBA のベタ配列)などを作る場合です。
- これを作れば、後は、いかようにも操作でき「つぶし」が利きます。
- 自分は、OpenGL を使った俺俺フレームワークを使い描画しています。
- Mupdf を C++ で扱う為に pdf_in.hpp を実装しています。
- 解説は、それをベースに簡略化したもので、実際のコードは、pdf_in.hpp を参照して下さい。
- レンダリングした画像は、img_rgba8.hpp で扱います。
Mupdf のコンテキストを作成する:
fz_context* context_;
context_ = fz_new_context(NULL, NULL, FZ_STORE_UNLIMITED);
fz_try(context_)
fz_register_document_handlers(context_);
fz_catch(context_) {
std::cerr << "cannot register document handlers: " << fz_caught_message(context_) << std::endl;
fz_drop_context(context_);
return false;
}
- コンテキストを生成する。(デフォルト状態)
- 標準のドキュメントハンドラーを登録する。(必ず必要)
-
fz_try、fz_catchはマクロ(;で終わっていない点に注意)で、C++ における例外のスローと補足を模したもののようです。 - こんな事をするなら、素直に C++ で実装すれば良いのにと思います。
- 使い終わったら廃棄を忘れずに。
PDF ファイルを開く:
fz_document* document_;
document_ = fz_open_document(context_, filename);
if(document_ == nullptr) {
// エラー
}
パスワードが設定されている場合:
if(fz_needs_password(context_, document_)) {
if(!fz_authenticate_password(context_, document_, password)) {
// エラー
}
}
- ドキュメントにパスワードが設定されている場合、パスフレーズを流し込み、ロックを解除します。
- この機能は実際には試していないので間違っているかもしれません。
- 一応、上記コードでエラー無くコンパイル出来ています。
ドキュメント全体のページ数を取得:
int page_count_;
fz_try(context_)
page_count_ = fz_count_pages(context_, document_);
fz_catch(context_) {
std::cerr << "cannot count number of pages: " << fz_caught_message(context_) << std::endl;
// エラー処理
}
- ドキュメントはページ単位に管理されます。
- 画像のレンダリングは、ページを指定して行います。
- ページ毎にサイズが異なるかもしれないので、そのケアが必要です。
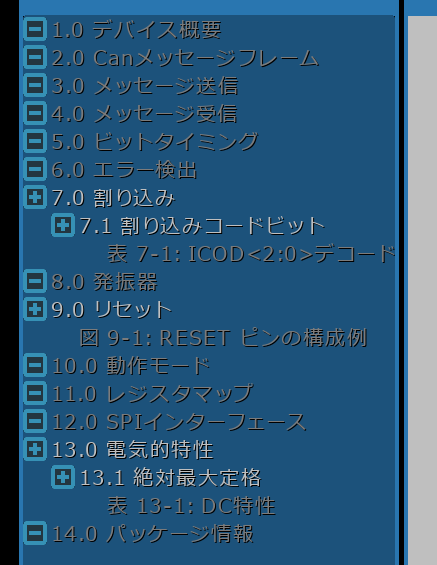
ドキュメント情報(アウトライン)の取得:
fz_outline* outline_;
std::string doc_title_;
outline_ = fz_load_outline(context_, document_);
if(outline_ != nullptr) {
}
- 「アウトライン」とは、ドキュメントの各注釈と、その位置情報などです。
-
fz_outline構造体のポインターが返ります。 - 扱う文字コードは UTF-8 となっています。
- PDF によっては存在しない場合もあり、その場合、ページだけで管理します。
typedef struct fz_outline
{
int refs;
char *title;
char *uri;
fz_location page;
float x, y;
struct fz_outline *next;
struct fz_outline *down;
int is_open;
} fz_outline;
-
titleは「注釈」となっています。 -
uriは位置情報です。(文字列) -
nextは、次の項目で、NULLになるまで続きます。 -
downは、項目中のサブ項目でNULLになるまで続きます。
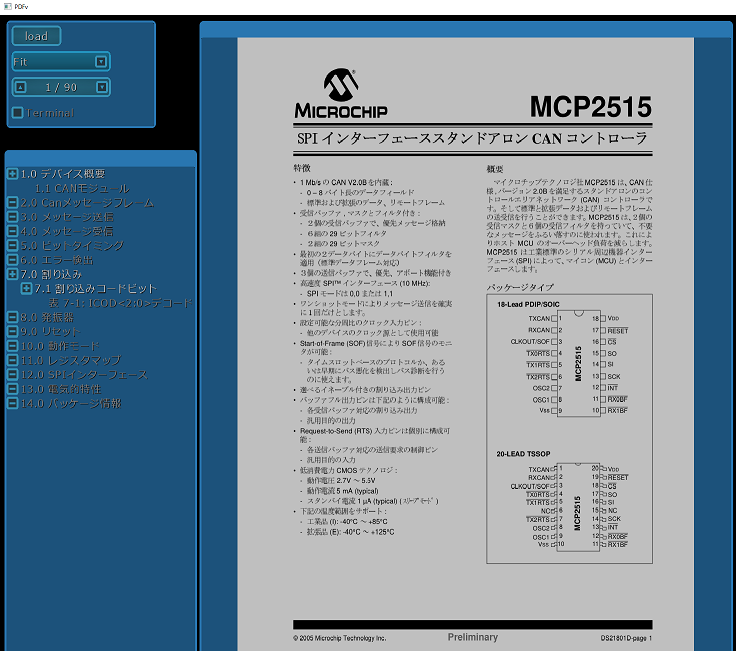
上記は、自分のテストアプリで、PDF をパースして表示した例です。
uri は #page=27&zoom=nan,71,70 のような文字列になっています。
ページのロード
auto page = fz_load_page(context_, document_, page_no_);
if(page == nullptr) {
std::cerr << "load page fail: " << fz_caught_message(context_) << std::endl;
return false;
}
- 指定のページをロードします。
-
pageは、ページを描画するのに基本となるインスタンスで、これを起点にして、描画を行います。 - 不要になったら廃棄を忘れずに。
描画サイズの取得と描画マトリックス計算:
float zoom = 1.0f;
float rotation = 0.0f;
fz_rect bound = fz_bound_page(context_, page);
auto xx = bound.x1 - bound.x0;
auto yy = bound.y1 - bound.y0;
fz_matrix m0 = fz_scale(zoom, zoom);
fz_matrix m1 = fz_pre_rotate(m0, rotation);
fz_matrix page_mat = fz_pre_translate(m1, -xx * 0.5f, -yy * 0.5f);
fz_irect tmp = fz_round_rect(fz_transform_rect(bound, pagem));
int w = tmp.x1 - tmp.x0;
int h = tmp.y1 - tmp.y0;
- Mupdf では、書類の左上が原点(0,0)です。
- なので、そのまま回転すると、書類の左上を中心に回転してしまいます。
- そこで、
fz_pre_translateで書類の中心へ原点を移動しています。 - その後、RGBA 描画の際に
fz_new_draw_deviceで描画座標をオフセットするマトリックスを与えて、中央に描画しています。 - プログラムでは「スケール ---> 回転 ---> 移動」の順番ですが、実際は逆の手順になります。
- この辺りが行列計算の深い処です。
- この手法は OpenGL のマトリックス計算と類似しています。
45度回転させて描画した例:

RGBA で描画:
struct rgba_t {
uint8_t r;
uint8_t g;
uint8_t b;
uint8_t a;
};
{
auto rgba = new rgba_t[w * h];
int alpha = 1;
int stride = w * sizeof(rgba_t);
auto p = reinterpret_cast<unsigned char*>(rgba);
fz_pixmap* pix = fz_new_pixmap_with_data(context_, fz_device_rgb(context_), w, h, NULL, alpha, stride, p);
fz_clear_pixmap_with_value(context_, pix, 0xff);
fz_matrix pix_mat = fz_translate(w * 0.5f, h * 0.5f);
fz_device* dev = fz_new_draw_device(context_, pix_mat, pix);
fz_run_page(context_, page, dev, page_mat, NULL);
fz_drop_device(context_, dev);
fz_drop_pixmap(context_, pix);
fz_drop_page(context_, page);
...
delete[] rgba;
}
- 上記の例では
rgba_t配列に対して、描画を行っています。 - 配列のポインタは
unsigned char*型で渡す必要があります。(void* にすべきだと思います。) -
strideは、横幅のバイト数で、この例では、単純に、横幅の4倍(RGBA)を指定しています。 -
alphaは、半透明を利用する場合に指定するようです。(0か1を指定、それ以外を指定しては駄目!) - ピクセルマップ、ページ、と別々にマトリックスを指定する為、混乱しがちです、注意を要します。
破棄:
if(outline_ != nullptr) {
fz_drop_outline(context_, outline_);
outline_ = nullptr;
}
if(document_ != nullptr) {
fz_drop_document(context_, document_);
document_ = nullptr;
}
- 配列を破棄する関数は、各構造体専用に用意されているようです。
- 基本的に
fz_drop_xxxに統一されているようです。
ライブラリのリンク
-lopengl32 -lglu32 -lglew32 -lopenal -lglfw3 -lcomdlg32
-lhid -lsetupapi -lksguid -lpthread
-lpng -ljpeg -lopenjp2 -lfreetype -lz -lmupdf -lmupdf-third -lharfbuzz -ljbig2dec -lgumbo -o pdfv.exe
- 上記は、pdfv アプリを生成する為のリンクコマンドの一部です。
- Mupdf を利用するのに不必要なライブラリもあります、Mupdf 関係では、主に3行目が重要と思います。
まとめ
いかがですか、意外と簡単に、PDF を操作出来る事に感動したのではと思います。
他にも、様々な機能があり、ここでは紹介しきれません。
プロジェクト全体を取得すれば、色々なアプリやツールのソースコードもあるので、それを読めば、やりたい事の手順も理解出来るものと思います。
最初にこのライブラリを見つけて、PDF ファイルを表示出来た時、凄く感動した覚えがあります。(数年前です)
このライブラリを使っている PDF リーダーで Sumatra PDF がオススメです。
この PDF リーダーは軽量で、高速、必要な機能はほぼ揃っており、非常に使いやすいです。
もう何年も、このアプリ一択です。
自分がテスト用に実装したアプリ pdfv のソースコード、フレームワークは、Github で公開しています。
関連リンク
glfw3_app(C++ フレームワーク)
glfw3_app/pdfv アプリ
ライセンス
私のコードは MIT
Mupdf 関係は、Mupdf のWEB を確認して下さい。