はじめに
スクレイピングや機械学習が得意なPythonを使って、食べログのコメントによる分類をやってみました。ここでは主に三つのプログラムによって処理を行っています。最初に食べログの店ごとのコメントを取得するために、エリア(白金、目黒、五反田)とジャンル(ラーメン)を絞り、店舗ごとの店舗名、ID、エリアなどの情報を取得しました。次に、取得した店舗のIDを使用して、店舗ごとのコメントページからコメントのテキスト情報を取得しています。その後、取得した店舗ごとのコメントを形態素解析し、ストップワード処理を行って、特徴ベクトルに変換したものをクラスタリングをして、コメントごとにラベリングをしました。最後に、そのラベリング情報をTableauを使って可視化してみました。
このプログラムを処理するために必要な環境
BeautifulSoup、pandas、numpy、gensim、scikit-learnなどのライブラリがインストールされている。(anacondaなどのパッケージを推奨、gensimのみ別途インストールが必要)
mecabをpythonで使用できる環境が整っていて、かつ、mecab-ipadic-NEologdなどの辞書が入っている。
ここで紹介しているプログラムはコマンドラインの「python ファイル名.py」で実行できますが、スクレイピングに関するプログラムについては、PyCharmなどの統合開発環境、形態素解析からクラスタリングまでのプログラムは、jupyter notebookを使用して試行錯誤しながら進めたほうが良いと思います。
主なプロセス
この分析は以下の三つのプログラムを順を追って実行していくことで処理できます。
・食べログからラーメンごとのIDなどをスクレイピングする。→scraping_tabelog_ramen.py
・食べログの各ラーメンにおけるコメントをスクレイピングする→tabelog_ramen_comment.py
・コメントを形態素解析し、クラスタリングする。→review_tabelog_ramen01.py
・Tableauで可視化
食べログのコメントをスクレイピングする。
食べログのコメントをスクレイピングするためには、サイトがどのような構造になっているかを調べる必要があります。食べログのサイトを見てみると、ジャンルとエリアを絞り込めるようになっており、絞り込みをおこなうと店舗の基本情報が掲載されているページになります。そこからさらに、店舗のページに移動すると口コミというタブがあり、それをクリックすると店舗ごとの口コミ一覧を見ることができます。ですので、各店舗ごとの口コミ情報をスクレイピングするためには、サイトで設定している店舗ごとのIDを取得する必要があります。その取得したIDを使用して各店舗ごとのコメントをスクレイピングします。なので、最初に店舗名や店舗のIDをスクレイピングするプログラムと、店舗ごとのコメントを取得するプログラムの二つに分けて処理を行ってみました。
取得するエリアを絞り、ラーメン屋ごとのID、店名などをスクレイピングする。
以下のプログラムでは、エリア(白金、目黒、五反田)とジャンル(ラーメン)を絞った時のサイトのURLを使用して、店舗のID、店舗名、評価ポイント、口コミ数を取得しています。そして取得したデータをtabelog_ramen.csvというファイル名でCSVファイルとして書き出す処理までを行っています。
import csv
import requests
import codecs
import time
from bs4 import BeautifulSoup
f = codecs.open('tabelog_ramen.csv', 'w', 'utf-8')
f.write("code,name,area,point,count" "\n")
target_url = 'https://tabelog.com/tokyo/A1316/rstLst/ramen/{0}/'
for i in range(1, 6):
r = requests.get(target_url.format(i)) #requestsを使って、webから取得
req = requests.Request(r)
soup = BeautifulSoup(r.text, 'html5lib') #要素を抽出
codes = soup.find_all('a',{'class':'list-rst__favorite-rvwr js-follow-reviewer-fav'})
names = soup.find_all('a',{'class':'list-rst__rst-name-target cpy-rst-name'})
areas = soup.find_all('span',{'class':'list-rst__area-genre cpy-area-genre'})
points = soup.find_all('span',{'class':'c-rating__val c-rating__val--strong list-rst__rating-val'})
counts = soup.find_all('em',{'class':'list-rst__rvw-count-num cpy-review-count'})
for code, name, area, point, count in zip(codes, names, areas, points, counts):
print(code.attrs['data-rst-id'], name.text, area.text, point.text, count.text)
f.write(str(code.attrs['data-rst-id']) + ',' + name.text + ',' + area.text + ',' + point.text + ',' + count.text + "\n")
time.sleep(1)
f.close()
取得したIDからコメントのテキストデータを取得する。
先ほどのプログラムで取得した店舗ごとのIDを使用してコメントのテキストデータをスクレイピングしています。前のプログラムで取得したCSVファイルと関連性を持たせるために、店舗のIDを再度取得し、さらにデータの重複などがないかを確認するために投稿日付も取得し、tabelog_ramen_review01.csvとしてCSVファイルとして保存しています。
import requests
import codecs
from bs4 import BeautifulSoup
import pandas as pd
import itertools
import numpy as np
import re
import time
f = codecs.open('tabelog_ramen_review01.csv', 'w', 'utf-8')
f.write("code,date,review" "\n")
target_url = 'https://tabelog.com/tokyo/A1316/A131601/{0}/dtlrvwlst/COND-0/smp1/?lc=0&rvw_part=all&PG={1}'
tabelog01 = pd.read_csv('tabelog_ramen.csv',dtype = 'object')
tabelog02 = tabelog01['code'].values.tolist()
list2 = np.array([j for j in range(1,24)])
list3 = list(itertools.product(tabelog02, list2))
for i,j in list3:
r = requests.get(target_url.format(i,j)) #requestsを使って、webから取得
soup = BeautifulSoup(r.text, 'html5lib') #要素を抽出
codes = soup.find_all('div',{'class': 'rvw-item js-rvw-item-clickable-area'})
dates = soup.find_all('div',{'class':'rvw-item__date'})
reviews = soup.find_all('div',{'class':'rvw-item__rvw-comment'})
for code, date, review in zip(codes, dates, reviews):
print(re.sub(r'\D','',code.attrs['data-detail-url'])[10:18], date.text.replace("\n", ' ').replace(" ",''), review.text.replace("\n", ' ').replace(" ",'').replace(",",' '))
f.write(re.sub(r'\D','',code.attrs['data-detail-url'])[10:18] + ',' + date.text.replace("\n", ' ').replace(" ",'') + ',' + review.text.replace("\n", ' ').replace(" ",'').replace(",",' ') + "\n")
time.sleep(1)
f.close()
形態素解析について
形態素解析は、文章を名詞、助詞、動詞、形容詞などの品詞に分類して単語ごとに分割する作業で、MeCabなどの形態素解析エンジンなどが知られています。例えば、「すもももももももものうち」を形態素解析すると、以下のように分割します。
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
PythonでMecabを使用できるようにする。
PythonでMeCabを使用できるようにするには、MeCabをマシンにインストールし、mecab-python3をインストールする必要があります。MeCabのインストール(Mac)の方法は、以下のブログを参考にしてみてください。インストールの手順としては、MeCabのインストール、IPA辞書のインストール、環境設定という手順になります。
次にマシンへのMaCabのインストールができたら、以下のコマンドでPythonでMeCabを使用できるライブラリをインストールします。
pip install mecab-python3
辞書を使えるようにする。
MeCabをインストールしても問題が残ります。それは以下のような「攻殻機動隊」と言った固有名詞を形態素解析した場合に、固有名詞が必要以上に分割されていまうということがあります。
攻殻機動隊
攻 名詞,固有名詞,人名,名,*,*,攻,オサム,オサム,,
殻 名詞,接尾,一般,*,*,*,殻,ガラ,ガラ,,
機動 名詞,一般,*,*,*,*,機動,キドウ,キドー,,
隊 名詞,接尾,一般,*,*,*,隊,タイ,タイ,,
EOS
この問題を解決するには、辞書登録をする必要があります。辞書登録する方法として、幾つかありますが、最近の方法としては、mecab-ipadic-NEologdをインストールするのがもっとも簡単だと思います。以下のブログでmecab-ipadic-NEologdのインストール方法を紹介しています。このほかには、WikipediaのタイトルをMeCabの辞書として登録する方法などもあります。今回の形態素解析では前者の方法で辞書登録しています。
macにmecab-ipadic-NEologdをインストールする
実際に辞書登録をしてから形態素解析をすると以下のような感じになります。
mecab
攻殻機動隊
攻殻機動隊 名詞,固有名詞,一般,*,*,*,攻殻機動隊,コウカクキドウタイ,コウカクキドータイ
EOS
スクレイピングしたコメントを形態素解析する。
ここでは、先ほど取得したコメントのテキストデータを形態素解析して特徴ベクトルに変換できるような前処理を行っていきます。ここからの処理は、一つ一つの処理ごとにjupyter notebookで実行しながら確認していくことをお勧めします。
必要なライブラリのインポート
最初に、データフレームを使用できるようにするpandasや形態素解析に必要なライブラリのMeCab、特徴ベクトルに変換するときに必要なgensim、クラスタリングに必要なkmeansなどのライブラリをインポートします。
import pandas as pd
import MeCab
import gensim
import numpy as np
from sklearn.cluster import KMeans
CSVファイルをデータフレームとして読み込む
前のプログラムで取得したCSVファイル(tabelog_ramen_review01.csv)をデータフレームとして読み込みます。
reviews = pd.read_csv('tabelog_ramen_review01.csv')
形態素解析の処理
以下のコードは、形態素解析の関数です。
mecab = MeCab.Tagger("-Ochasen")
def wakatico(x):
kekka = mecab.parse(x)
lines = kekka.split('\n')
words = []
for line in lines:
cols = line.split("\t")
words.append(cols[0])
return words
データフレームに新しく形態素解析したデータを追加
ここでは、reviewsのデータフレームにwakatiという新しいカラムを追加しつつ、そこに形態素解析した結果を保存するという処理を行っています。
reviews["wakati"] = reviews.apply(lambda row: wakatico(str(row['review'])),axis=1)
形態素解析した文字列をストップワード処理する。
形態素解析したテキストデータには、「は」や「を」などの単語としては意味をもたいない文字や、今回の分析には不必要な数字や英文字記号などが含まれてしまっていますので、それらの文字列を削除するようなストップワード処理を行っています。
ストップワード処理の関数
ここでは、ストップワード処理を行う文字列として、三つの変数に正規表現を記述しています。一つ目は、ひらがな2文字の文字列、次が数字、三つ目がEOSと...という記号です。それらをあらかじめ変数で用意しておいて、ストップワード処理を行う関数で記述してます。また関数では、1文字より大きい文字列という条件も追加しています。
pair = r"^[ぁ-ん]{2}$"
numb = r"^[0-9]+$"
kigou = r"^[EOS,...]+$"
import re
def stopword(words):
return [x for x in words if len(x) > 1 and re.match( numb, x ) is None and re.match(pair,x) is None and re.match(kigou,x) is None]
データフレームに新しくストップワード処理したデータを追加
次の処理では、データフレームにストップワード処理をしたデータをwasというカラムに保存するということをしています。以降はこのカラムを使用して特徴ベクトルの変換を行っています。
reviews["was"] = reviews.apply(lambda row: stopword(row["wakati"]),axis=1)
参考:形態素解析してストップワード処理をした単語を集計してみる。
次の処理は今回のプログラムでは必ずしも必要ではないですが、この次に行うフィルター処理のパラメータをどうするかを検討するときの参考になるので、実行して集計結果を確認してみると良いです。以下のコードを実行すると、登場回数の多かった順に形態素分析した文字列が表示されます。特徴ベクトルに変換する際に、あまり登場回数の多い単語、例えばラーメンなどや、1回や数回しか出てこない単語などはクラスタリングする際にうまく分類されないことがあります。そのために、単語の登場回数と形態素解析された文字列の総数などの情報からフィルター処理の設定をしておく必要があります。
def wordcount(dic, items):
for item in items:
if item not in dic:
dic[item] = 1
else:
dic[item]+=1
return dic
from functools import reduce
kekka = reduce(lambda d, tokens: wordcount(d, tokens), list(reviews.was),dict())
df = pd.DataFrame(list(kekka.items()),columns=['word','count'])
sorted_df = df.sort_values('count', ascending=False)
sorted_df
ストップワード処理をしたデータを特徴ベクトルに変換する
ここでは、先ほど形態素解析し、ストップワード処理をしたテキストデータをクラスタリングができるようなデータに変換します。具体的には、各形態素解析されたテキストデータをgensimを使って一旦辞書にします。次にその辞書にしたデータにフィルター処理を行い、出現回数の多い単語と、出現回数の少ない単語を削除します。その後、そのデータを特徴ベクトルに変換します。特徴ベクトルとは、文字列であったデータを文字があるかないかで1か0という形式のデータに置き換えたものを言います。これによってクラスタリングが行えるようになります。
gensimで辞書に変換する
ここでの処理は、gensimを使って配列データから辞書に変換します。この辞書に変換すると、単語ID・単語・単語出現回数を持つデータに変換されます。
jisho = gensim.corpora.Dictionary(list(reviews.was))
フィルターをかけて出現回数の多すぎる単語と少なすぎる単語を削除する。
この処理は、先ほど変換した辞書のうち、出現回数の多すぎる単語と出現回数が少なすぎる単語を削除するという処理を行います。no_belowは出現回数が30回以下の単語を削除するという意味で、no_aboveは出現単語率がN%より上(N%は除かれない)の単語を削除するという意味になります。このフィルターの数値は、先ほど紹介した単語の集計処理のプログラムを実行するなどして、多すぎる出現回数の単語や少なすぎる単語を調べてから行う必要があります。
jisho.filter_extremes(no_below=30,no_above=0.2)
gensimでフィルターをかけた辞書を特徴ベクトルに変換する。
この処理は、先ほど変換しフィルター処理を行った辞書とストップワード処理をした配列データを使用して、特徴ベクトルに変換する処理を行っています。これを行うことによって、ある形態素解析された文章の配列データの文章が、辞書にある単語かそうでないかを0または1で表現したデータとして保存されます。
terms = len(jisho)
T = [gensim.matutils.corpus2dense([jisho.doc2bow(doc)],num_terms=terms, dtype=None).T[0] for doc in list(reviews.was)]
t = np.array(T)
kmeansでクラスタリングを行う。
特徴ベクトルに変換された0または1で表現された文章のデータをkmeansを使用してクラスタリングを行います。この処理を行うことで、クラスタリングされたデータにラベルが貼られていきます。
クラスター分析の設定を行う。
kmeansの処理を行うためには分割数を指定する必要があります。今回は5分割でクラスタリングを行いましたが、うまい結果が出るためには何度か分割数を変更して試行錯誤してみる必要があります。
model = KMeans(n_clusters=5, random_state=10).fit(t)
label = model.labels_
クラスタリングしたデータをCSVファイルとして保存する。
最後に、クラスタリングしたデータをCSVファイルとして保存します。クラスタリングした0から4まで(5分割)にラベリングされたデータをここではtypeとして保存しています。
import codecs
f = codecs.open('tabelog_ramen_learn.csv', 'w','utf-8')
f.write('type,code,date' + "\n")
for lab, code, date in zip(label, list(reviews.code), list(reviews.date)):
f.write(str(lab) + ',' + str(code) + ',' + str(date) + "\n")
f.close
形態素解析からクラスタリングまでのソースコード
以下のソースコードは、先ほどまで説明した、コメントを形態素解析し、クラスタリングするまでの処理を一気に処理するプログラムです。jupyter notebookで一つず試しながら進めても良いですし、以下のソースコードを実行して一気に処理しても良いと思います。
import MeCab
import gensim
import numpy as np
from sklearn.cluster import KMeans
reviews = pd.read_csv('tabelog_ramen_review01.csv')
mecab = MeCab.Tagger("-Ochasen")
def wakatico(x):
kekka = mecab.parse(x)
lines = kekka.split('\n')
words = []
for line in lines:
cols = line.split("\t")
words.append(cols[0])
return words
reviews["wakati"] = reviews.apply(lambda row: wakatico(str(row['review'])),axis=1)
pair = r"^[ぁ-ん]{2}$"
numb = r"^[0-9]+$"
kigou = r"^[EOS,...]+$"
import re
def stopword(words):
return [x for x in words if len(x) > 1 and re.match( numb, x ) is None and re.match(pair,x) is None and re.match(kigou,x) is None]
reviews["was"] = reviews.apply(lambda row: stopword(row["wakati"]),axis=1)
jisho = gensim.corpora.Dictionary(list(reviews.was))
jisho.filter_extremes(no_below=30,no_above=0.2)
terms = len(jisho)
T = [gensim.matutils.corpus2dense([jisho.doc2bow(doc)],num_terms=terms, dtype=None).T[0] for doc in list(reviews.was)]
t = np.array(T)
model = KMeans(n_clusters=5, random_state=10).fit(t)
label = model.labels_
import codecs
f = codecs.open('tabelog_ramen_learn.csv', 'w','utf-8')
f.write('type,code,date' + "\n")
for lab, code, date in zip(label, list(reviews.code), list(reviews.date)):
f.write(str(lab) + ',' + str(code) + ',' + str(date) + "\n")
f.close
Tableauで可視化
Tableauは、データの分析やビジュアル化を直感的な操作で行えるツールです。ここでは、Tableauを使って、先ほどのプログラムでスクレイピングしたCSVファイルと、クラスタリングしたCSVファイルの二つのデータを使用して可視化を行います。
ファイルの読み込み
Tableauを開くと、テキストファイルを選べる項目があるので、そこから先ほどのプログラムで実行した際に保存された2つのファイル、「tabelog_ramen.csv」と「tabelog_ramen_learn.csv」を開きます。すると、2つのファイルは店名のcodeで結合されるようになります。ファイルが読み込めたら、画面下のシート1をクリックします。
データの可視化
シート1の画面になったら、左下のメジャーの「tabelog_ramen_learn.csv」からtypeを選び、画面上の行にドラッグします。そして、typeはデフォルトだと合計になっているので、平均に変更しておきます。次に、レコード数を列にドラッグします。次に、左上にあるディメンジョンの「tabelog_ramen.csv」からnameを選び、画面中央にドラックします。そして、メニュー画面から行と列の向きを変更すると、下のような画面になります。
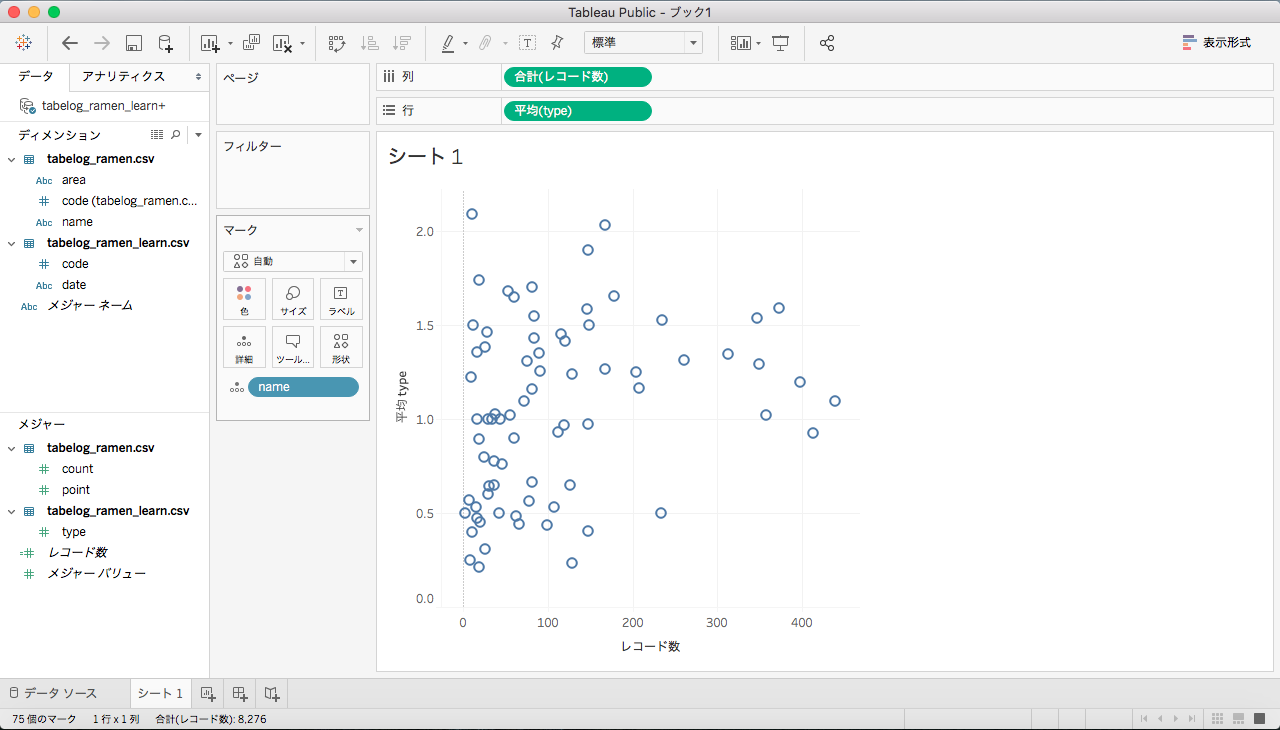
最後に、文字を表示したり、罫線の太さや種類、色などを変えたり、画面の比率を調整したりしていきます。すると、以下のような分析結果をビジュアル化することができます。
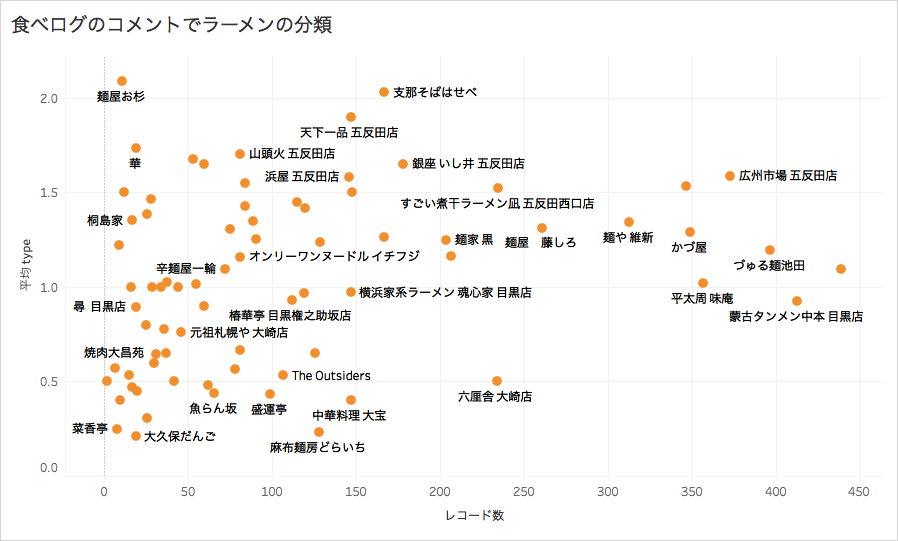
参考
ここでの分析は以下の動画を参考にさせていただきました。特に、形態素解析したデータを特徴ベクトルに変換する処理や、Tableauで可視化するやり方などが動画でわかりやすく説明されています。
機械学習で日本酒をクラスタリング Part3 コーパス編
機械学習で日本酒をクラスタリング Part4 K-means(k平均法)編