経緯
単語間の類似度を測るにあたって自然言語処理の勉強をしていました。その際に読んでいた”自然言語処理の基礎”という本にwordnetというものを知ったので、これを使って単語間の類似度を求めてみようと思いました。
しかし、ネットで「wordnet 類義語」とか調べても日本語版wordnetのqiitaの記事ばかりで英語版を書いてる人がすくなかったです。そこで初の投稿をしてみようと思いました。
((え、記事がない=需要がない?
自然言語処理の基礎のamazonリンク
私のwordnetに関する基本的知識はこの本です!
wordnetとは
wordnetは、シソーラス、概念階層という単語辞書を使って単語間の類似度を出します。
シソーラスは、似ている単語同士は近くに,そうでない単語同士は遠くに位置するような辞書です!
シソーラスはこれ↓
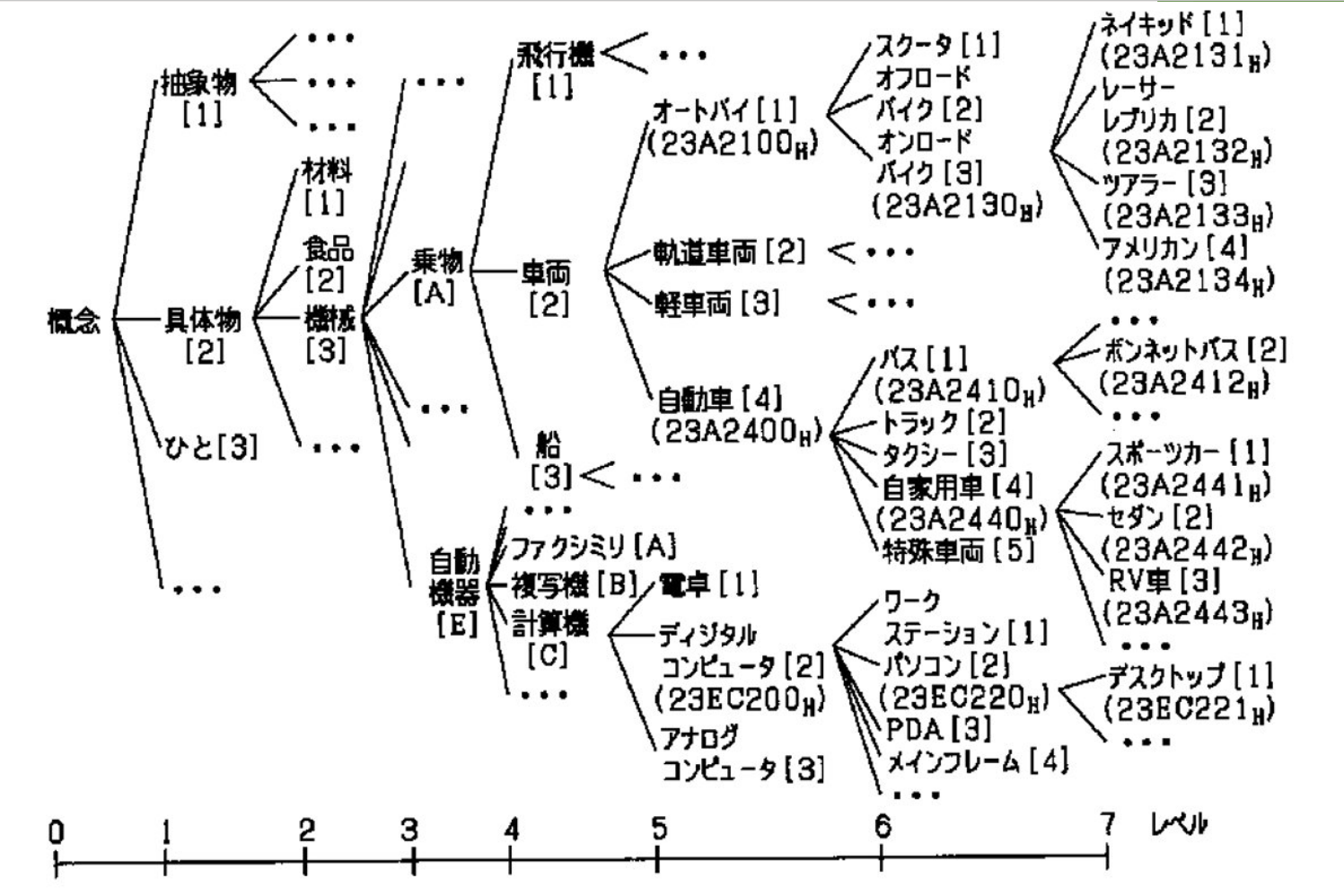
引用: http://astamuse.com/ja/published/JP/No/2010129025
さて、これを使ってどうやって類似度を求めるのでしょう?
任意の2つの単語の類似度は、このシソーラスから、2つの単語の共通する単語の深さをもとに計算できます。2つの単語のシソーラス中での根からの深さをそれぞれ、a, b,2つの単語の共通の上位語の根からの深さをcとすると、
類似度(sim) = (a+b)\(c✕2) (0≦sim≦1)
となります!
このシソーラスから飛行機と自動車の類似度を求めてみる
概念から飛行機までの足の長さは4、自動車までは5ですね!
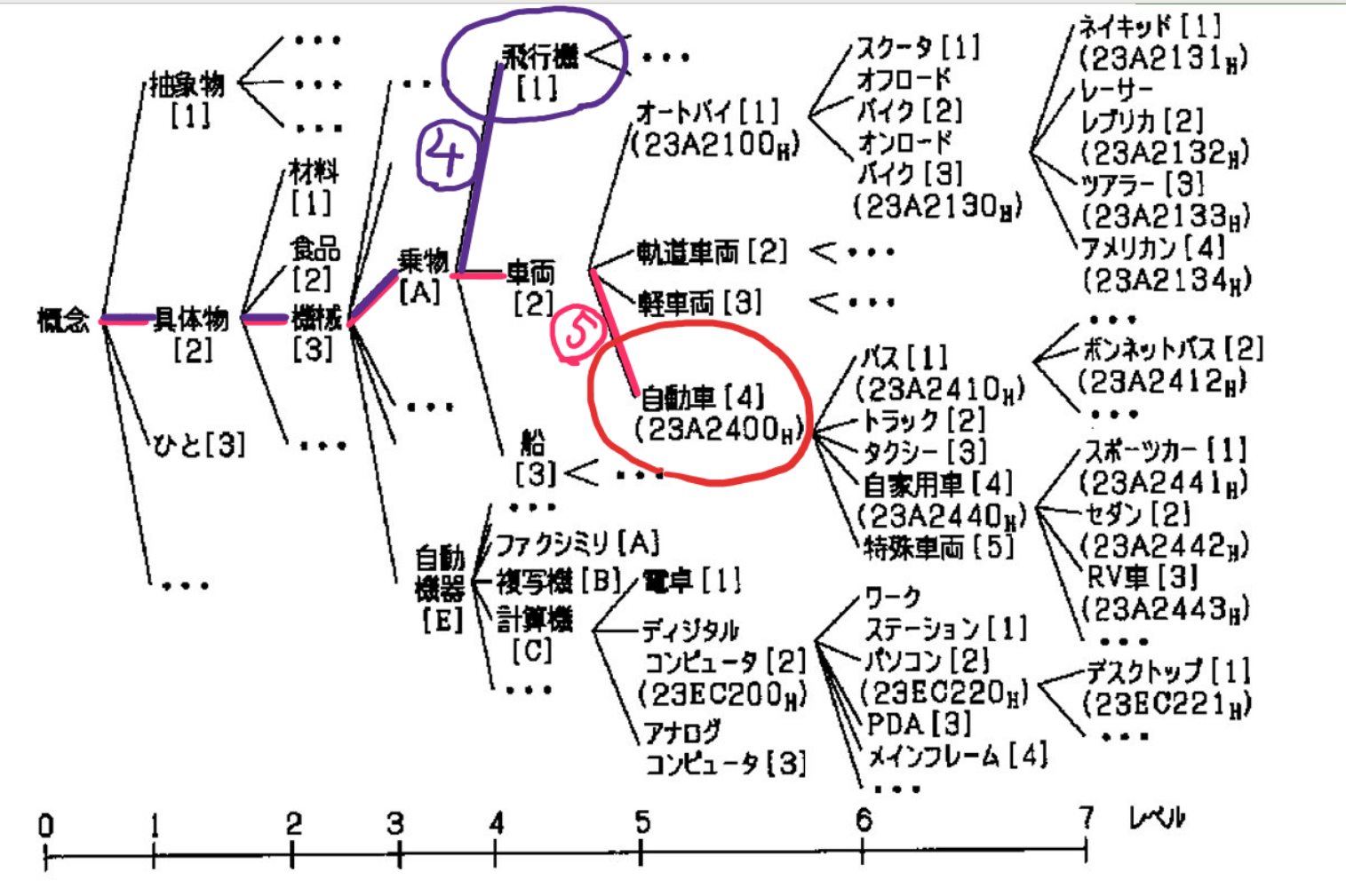
これらの2つの単語の共通上位語は乗り物で、そこまでの足の長さは3!

以上より、
類似度(sim) = (4+5)\(3✕2) = 0.666666...
飛行機と自動車の類似度は0.666...ですのでまあまあ似てるって感じ?
早速pythonで使ってみよう
環境
python3
ubuntu 18.04
基本的な使い方は以下のリンクを参考↓
WordNet Interface
wordnetのインストール
これを実行すればインストールされると思います
また、データセットの更新もこのコードを実行すればできます
import nltk
nltk.download("wordnet")
pythonで上の飛行機と自動車の類似度を出してみる
手計算で出した上の0.6666...になればいいけど、、
from nltk.corpus import wordnet
word = ["plane", "car"]
w1 = wordnet.synset(word[0]+'.n.01')
w2 = wordnet.synset(word[1]+'.n.01')
print(word[0] + "と" + word[1] + "の類似度:" + str(w1.wup_similarity(w2)))
結果↓
planeとcarの類似度:0.6666666666666666
いい感じ!
Happyの類義語と対義語を出してみる
単にwordnetを使って類義語とかだすと、"_"や"-"を含んだ単語をも出てきてやだったので、これらは省きました。
from nltk.corpus import wordnet
synonyms = []
antonyms = []
for syn in wordnet.synsets("happy"):
for l in syn.lemmas():
if "_" not in l.name() and "-" not in l.name():
synonyms.append(l.name())
if l.antonyms():
antonyms.append(l.antonyms()[0].name())
print("類義語")
print(list(set(synonyms)))
print("対義語")
print(list(set(antonyms)))
結果↓
類義語
['glad', 'felicitous', 'happy']
対義語
['unhappy']
felicitous ...?
調べてみたら、”幸運な”って意味らしいのでhappyの類義語として良さそう!
使えそう!
次回
次回は、英語版word2vecについてや、実際にwordnetを使って、
質疑応答の精度を上げる
入力された文章の類似文章を作る
とかのqiita書きたいです
参考
https://wordnet.princeton.edu/
http://www.nltk.org/howto/wordnet.html
https://pythonprogramming.net/wordnet-nltk-tutorial/