Soccer On Your Tabletop
サッカー動画から半自動的に選手の3Dメッシュを作る SoccerOnYourTabletop をAWS上に環境構築し、HoloLensにデプロイした。その際、依存しているライブラリなどの影響で思いのほか修正する必要が出たので、それを共有しようと思う。

(画像クリックすると再生します)
環境構築編
SoccerOnYourTabletop が依存しているライブラリは
- Detectron
- COCO API
- OpenPose
- OpenCV3.1 + OpenCV_contrib
- Eigen3
それに加えて pip3 で入れるものもある(ただ自分は conda で既に入れていたものもあったので、一部だけを pip で)
初期環境
- AWS DeepLearningBaseAMI
- Ubuntu 16.04
- CUDA-8.0/cudnn7.1.4
- はじめから caffe とかが動作する AMI を使うのがいいかも
- AMI の種類については MarketPlace から
- p2.xlarge
- Python 3.6 と 2.7
- どのように管理するかは任せるが自分は anaconda で環境を作った
- リモートデスクトップ接続環境
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/connect-to-linux-desktop-from-windows/ を参照のこと
- SoccerOnTabletop で動画内のサッカーコートを正しく認識するため(カメラパラメータ推定のため)に GUI 操作が必要になるため必要(後述)
Detectron
Facebook が state-of-the-art な物体検出アルゴリズムを複数実装したもの。Caffe2 で書かれている。
Python2 を使っているので 環境を Python2 に切り替えて から以下の操作を行うこと。
**
- Caffe2 のインストール
- https://caffe2.ai/docs/getting-started.html?platform=windows&configuration=compile に従う
- ソースビルドしてもいいが、自分は
conda install -c caffe2 caffe2-cuda8.0-cudnn7でインストールした - 【要注意】 cudnn7 とあるが、 cudnn7.0.4 や cudnn7.0.5 では動かない。 cudnn7.1.4 が必要
**
2. COCO API のビルド
- COCO は物体検出用に作られた大規模な画像データセットで、このライブラリにはそれを扱うための API が用意されている
- ビルドは以下を実行
# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python2 setup.py install --user
**
3. Detectron のビルド
- 以下を実行
# DETECTRON=/path/to/clone/detectron
# Detectron リポジトリのクローン
git clone https://github.com/facebookresearch/detectron $DETECTRON
# Python の依存パッケージのインストール
cd $DETECTRON && pip install -r requirements.txt
# Python モジュールのセットアップ
make
# Detectron のテスト
python2 $DETECTRON/detectron/tests/test_spatial_narrow_as_op.py
OpenPose
人体のボーンを推定するライブラリ。 cudnn5.1 が求められているが、 caffe2 をインストールする都合上 cudnn7.1.4 のまま続行(結果としてはうまくいった)。
**
- リポジトリのクローン
git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose
**
2. CMake GUI のインストール
sudo apt-get install cmake-qt-gui
- CMake は GUI を使うほうが設定しやすい。せっかくリモートデスクトップ環境が用意できているので GUI を推奨
**
3. 他の依存ライブラリのインストール
sudo apt-get --assume-yes install libatlas-base-dev libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get --assume-yes install --no-install-recommends libboost-all-dev
-
インストールガイドでは
sudo bash ./ubuntu/install_cmake.shすることを推奨しているが、cudnn5.1 が勝手に入れられてしまうので、必要な部分だけ抽出
**
4. OpenCV3.1.0+contrib のビルド
3.4.1 や 2.4.13 などで試してみたが、エラーが出たため、 OpenCV3.1.0 が必要
- 詳細はUbuntu Desktop 16.04上で、OpenCV3.1.0をビルドするを参考にした
- Soccer On Tabletop では OpenPose の Python API は使用しないため、 OpenCV 側も Python API をインストールする必要がない。なので Python 部分は飛ばしてよい。その場合 CMake する際に
BUILD_opencv_python2とBUILD_opencv_python3のチェックを外しておく
- Soccer On Tabletop では OpenPose の Python API は使用しないため、 OpenCV 側も Python API をインストールする必要がない。なので Python 部分は飛ばしてよい。その場合 CMake する際に
- 以下のページで OpenCV3.1 と Contrib が手に入る
**
5. Eigen3 のインストール
- OpenPose をビルドする際に
WITH_EIGENにチェックを入れれば自動でビルドしてくれる。それか以下を実行する。
sudo apt-get install libeigen3-dev
**
6. OpenPose のビルド
- 基本的にインストールガイドに従う
- Caffe をまだインストールしていない場合は、
BUILD_CAFFEにチェックを入れる- make する際に
#error This file was generated by a newer version of protoc which isというようなエラーが出たら、 Caffe をビルドする際の protobuf のバージョンが求められているものより高いということになる。 -
protoc --versionを実行し、 2.6.1 より高い場合、 conda 等でインストールしたものが使われている可能性がある。 -
which protocを実行するとどの場所にインストールされているかわかるので、conda でインストールしたものっぽいと思ったら、環境変数PATHをecho $PATHで確認する。 -
PATHの上位にwhich protocのフォルダが含まれていたら、そのフォルダをPATHの下位に来るよう書き換える -
protoc --versionで正しいバージョンになっているかを確認する - 例)
- make する際に
$ which protoc
/home/ubuntu/.pyenv/shims/protoc
$ echo $PATH
/home/ubuntu/.pyenv/shims:/usr/bin
# /home/ubuntu/.pyenv/shims が前に来ているので後ろにする
$ export PATH="/usr/local/bin:/home/ubuntu/.pyenv/shims"
/usr/bin:/home/ubuntu/.pyenv/shims
$which protoc
/usr/bin/protoc
# 変更された
- OpenCV を自分でビルドした場合は
-
OpenCV_CONFIG_PATHに/usr/local/share/OpenCV/ -
OpenCV_DIRに/usr/local/share/OpenCV/をセットする
-
**
7. OpenPose の確認
- https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/quick_start.md#quick-start にあるようなサンプルをいくつか試してみる
3Dメッシュ生成編
Detectron や OpenPose は SoccerOnTabletop プロジェクトの Readme が作られてからバージョンアップに伴う仕様変更が発生していたため、実際は数か所の修正が必要となった。
修正済みのコードは本家からフォークしたリポジトリ
https://github.com/robonich/soccerontable
に用意したので、よかったら使ってください。
**
- プロジェクトのクローンと Python パッケージのインストール
# SOCCERCODE=/path/to/soccercode
git clone https://github.com/krematas/soccerontable $SOCCERCODE
# pip をするかは状況に合わせて
pip3 install -r requirements.txt
# 後ほど使うコードのビルド
bash compile.sh
**
2. 入力動画(フレーム毎にjpgで保存されている)のサンプルをダウンロード
wget http://grail.cs.washington.edu/projects/soccer/barcelona.zip
unzip barcelona.zip
# DATADIR=/path/to/barcelona
**
3. Detectron による人物検出
mkdir $DATADIR/detectron
# DETECTRON=/path/to/clone/detectron
cp utils/thirdpartyscripts/infer_subimages.py ./$DETECTRON/tools/
cd $DETECTRON
python2 tools/infer_subimages.py --cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml --output-dir $DATADIR/detectron --image-ext jpg --wts https://s3-us-west-2.amazonaws.com/detectron/35861858/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml.02_32_51.SgT4y1cO/output/train/coco_2014_train:coco_2014_valminusminival/generalized_rcnn/model_final.pkl $DATADIR/images/
- このまま実行すると import エラーとなるので、コード変更を加える
- Detectron 側でフォルダ構成が変更されており、core や utils フォルダが detectron の下に入ったため
変更前
# infer_subimages.py:40
from core.config import assert_and_infer_cfg
from core.config import cfg
from core.config import merge_cfg_from_file
from utils.timer import Timer
import core.test_engine as infer_engine
import datasets.dummy_datasets as dummy_datasets
import utils.c2 as c2_utils
import utils.logging
import utils.vis as vis_utils
import pycocotools.mask as mask_util
# infer_subimages.py:217
utils.logging.setup_logging(__name__)
変更後
# infer_subimages.py:40
from detectron.core.config import assert_and_infer_cfg
from detectron.core.config import cfg
from detectron.core.config import merge_cfg_from_file
from detectron.utils.timer import Timer
import detectron.core.test_engine as infer_engine
import detectron.datasets.dummy_datasets as dummy_datasets
import detectron.utils.c2 as c2_utils
import detectron.utils.logging
import detectron.utils.vis as vis_utils
import pycocotools.mask as mask_util
# infer_subimages.py:217
detectron.utils.logging.setup_logging(__name__)
- 次にこのようなエラーが起こる
Traceback (most recent call last):
File "tools/infer_subimages.py", line 222, in <module>
main(args)
File "tools/infer_subimages.py", line 106, in main
model = infer_engine.initialize_model_from_cfg()
TypeError: initialize_model_from_cfg() takes at least 1 argument (0 given)
- model 作成部分(
infer_engine.initialize_model_from_cfg()) が、新しいバージョンではweight_fileを引数に取るようになったから
# detectron/core/test_engine.py:324
def initialize_model_from_cfg(weights_file, gpu_id=0):
- なので以下のように infer_subimages.py を書き換える
変更前
# infer_subimages.py:102
model = infer_engine.initialize_model_from_cfg()
変更後
# infer_subimages.py:102
model = infer_engine.initialize_model_from_cfg(args.weights)
-
しょうもないTypo も修正する
変更前
# infer_subimage.py:111
for ii, im_name in enumerate(im_list):
# infer_subimage.py:144
if i == 0:
# このまま実行すると i なんてないと怒られる
変更後
# infer_subimage.py:111
# i に直す
for i, im_name in enumerate(im_list):
# infer_subimage.py:144
if i == 0:
-
weight_fileはローカルにある重みファイルのパスを要求しているので、 `model_final.pkl' をダウンロードしてから再度プログラムを実行する
$ wget https://s3-us-west-2.amazonaws.com/detectron/35861858/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml.02_32_51.SgT4y1cO/output/train/coco_2014_train:coco_2014_valminusminival/generalized_rcnn/model_final.pkl
$ python2 tools/infer_subimages.py --cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml --output-dir $DATADIR/detectron --image-ext jpg --wts model_final.pkl $DATADIR/images/
-
実行後は
$DATADIR/detectronに以下のような人物のマスク画像が生成されているはず

-
もし真っ黒の画像しかなかった場合は Detectron が正常に動いていないので Caffe2 をインストールしなおしてみるなどをおすすめする
- 筆者はここで結構時間がかかった
**
4. カメラキャリブレーション
試合撮影に使われたカメラのパラメータを推定する。このとき画像と理想のサッカーコートの対応点を4つ手動で教える必要があり、GUI操作が発生するので、リモートデスクトップ接続をしながら以下のコマンドを実行する。
-
demoフォルダに入っている Python ファイルの先頭にすべてimport sys; sys.append('.')を追記する- 一部のモジュールが読み込めなくなるため
- 以下を実行し、キャリブレーションを開始する
cd $SOCCERCODE
python3 demo/calibrate_video.py --path_to_data $DATADIR
-
- このとき、謎の
Segmentation Faultが発生したら、matplotlibが描画に使用するバックエンドを疑うとよい。筆者の場合 Qt がうまく動いていなかったため、 TkAgg に切り替えることで事なきを得た - 先ほど追記したものの 直後の行* に
import matplotlib as mlp; mlp.use('TkAgg)を挿入し再度実行
- このとき、謎の
-
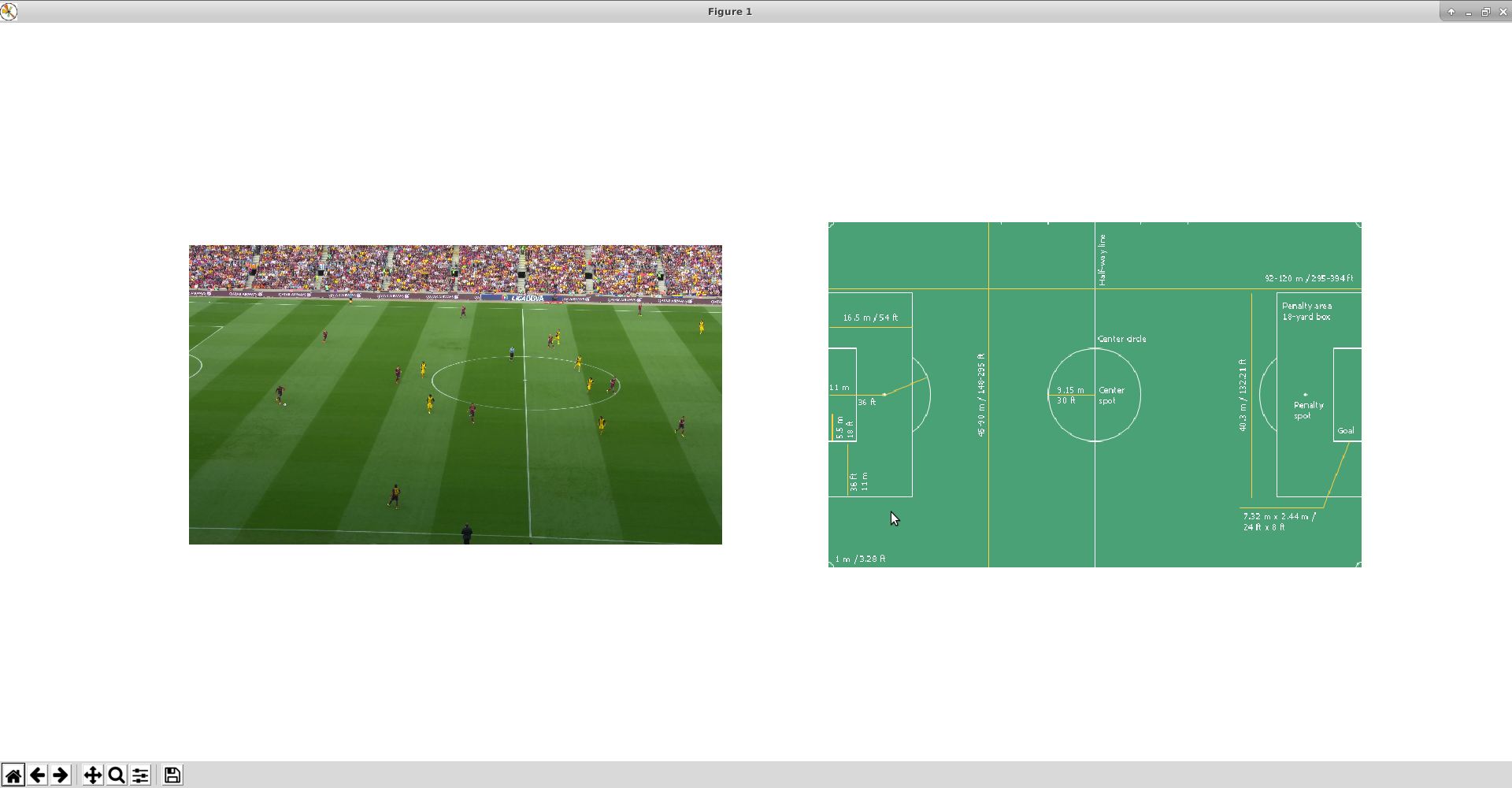
以下の画面が出現する
-
実画像とサッカー場の対応点を4つ選択する
- このときはなるべくばらけるように対応点を教えてあげるとよい(カメラの歪みが分かるように)
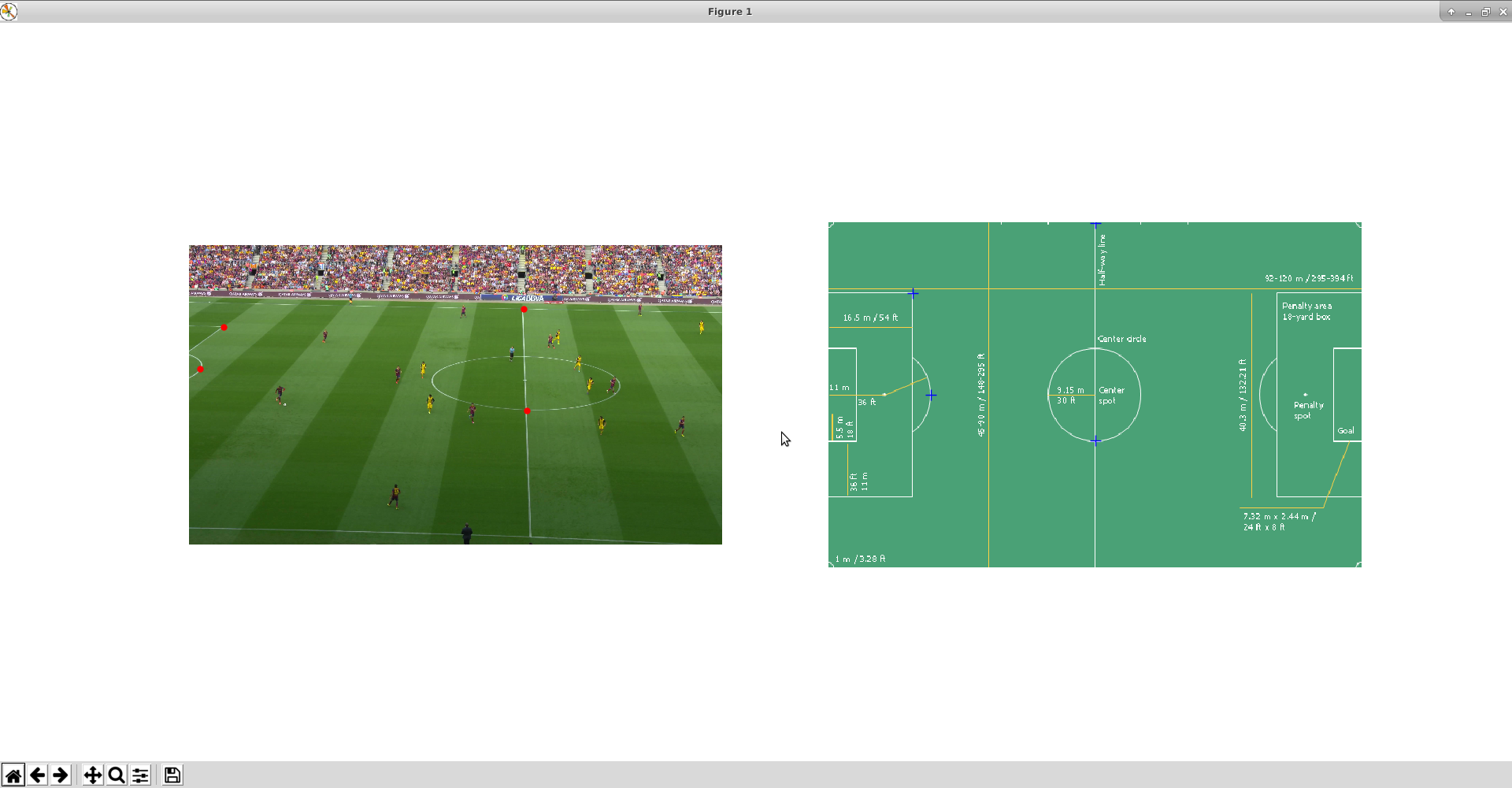
- このときはなるべくばらけるように対応点を教えてあげるとよい(カメラの歪みが分かるように)
-
ウィンドウを閉じるとキャリブレーションが始まり、しばらくするとキャリブレーション結果を表示してくれるので、問題がなさそうなら右側の
Save optを押す。満足いかないなら Discard を押して最初から
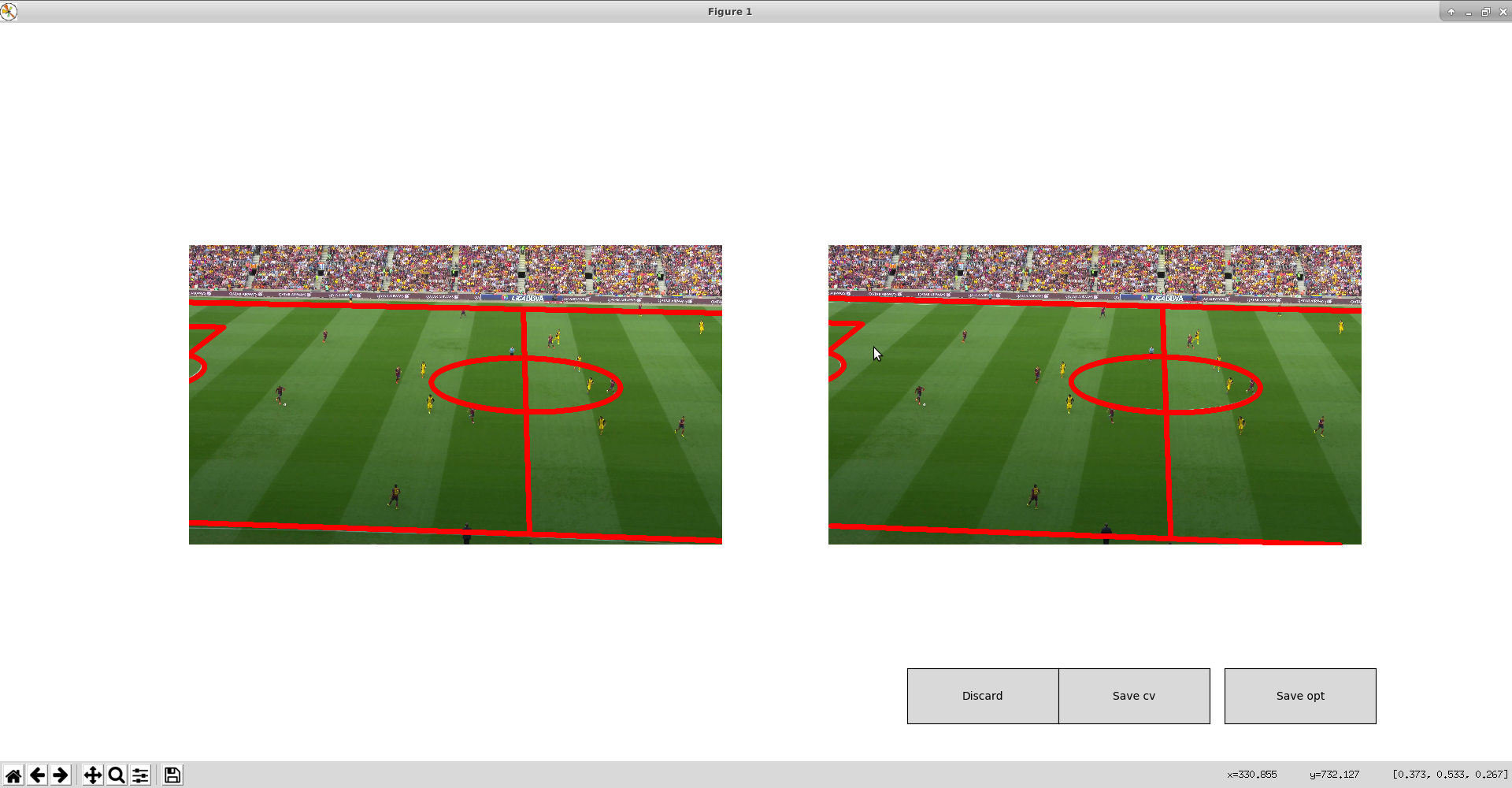
-
プログラムが無事に終わると
$DATADIR/calib.mp4が生成されているはずなので、確認してみるとよい
**
5. OpenPose による選手のポーズ推定
- 以下を実行する
# OPENPOSEDIR=/path/to/openpose/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64/
python3 demo/estimate_poses.py --path_to_data $DATADIR --openpose_dir $OPENPOSEDIR
- するとエラーが発生する
Traceback (most recent call last):
File "demo/estimate_poses.py", line 23, in <module>
db.refine_poses(keypoint_thresh=7, score_thresh=0.4, neck_thresh=0.4)
File "./soccer3d/core.py", line 335, in refine_poses
poses = [poses[ii] for ii in keep2]
File "./soccer3d/core.py", line 335, in <listcomp>
poses = [poses[ii] for ii in keep2]
IndexError: list index out of range
-
$DATADIR/tmpに残されている、一部の OpenPose による選手の姿勢検出結果が正しそうであれば、その姿勢検出結果を読み込む際に何かしらの不具合が発生している、つまりposesに正しく結果が格納されていないことが分かる - 原因は OpenPose のバージョンアップに伴う、検出結果を格納する
ymlファイル中の記述方式が変わったことにあった -
soccer3d/core.pyではsizesというキーがなければ推定された姿勢はないとしているが、ymlにはそもそもsizesキーが存在せず、代わりにrowsがその役割を果たしていた
# soccer3d/core.py:267
with open(join(join(self.path_to_dataset, 'tmp'), '{0}_pose.yml'.format(j))) as data_file:
for iii in range(2):
_ = data_file.readline()
data_yml = yaml.load(data_file)
if 'sizes' not in data_yml: # sizes というキーは存在しない!
continue
sz = data_yml['sizes']
n_persons = sz[0]
keypoints = np.array(data_yml['data']).reshape(sz)
- 実際の
ymlファイル
pose_0: !!opencv-matrix
rows: 1
cols: 18
dt: "3f"
data: [ 2.09722397e+02, 1.72544205e+02, 8.75938118e-01,
2.12439835e+02, 1.84927582e+02, 8.21689487e-01, 1.93255615e+02,
1.89076950e+02, 8.30192327e-01, 1.71222092e+02, 2.04145599e+02,
9.45078433e-01, 1.68364136e+02, 2.28972809e+02, 8.77120316e-01,
2.26218674e+02, 1.82248367e+02, 9.07761514e-01, 2.34456604e+02,
2.04210846e+02, 7.27888823e-01, 2.34459930e+02, 2.16570267e+02,
4.25617874e-01, 2.05596100e+02, 2.37232941e+02, 8.36183906e-01,
2.26199478e+02, 2.81217010e+02, 8.69147360e-01, 2.26268295e+02,
3.25345306e+02, 8.77623141e-01, 2.23434952e+02, 2.37217804e+02,
8.03246856e-01, 1.93230988e+02, 2.68889832e+02, 8.75034094e-01,
1.61544891e+02, 2.90896118e+02, 8.80115747e-01, 2.04266312e+02,
1.71097534e+02, 9.56580102e-01, 2.13780472e+02, 1.69820312e+02,
9.55266714e-01, 2.02746841e+02, 1.71110229e+02, 7.24748433e-01,
2.16576248e+02, 1.69770874e+02, 8.13678980e-01 ]
- そのため先ほどの
ymlファイル読み込み部分を以下のように書き換える
# soccer3d/core.py:267
with open(join(join(self.path_to_dataset, 'tmp'), '{0}_pose.yml'.format(j))) as data_file:
for iii in range(2):
_ = data_file.readline()
data_yml = yaml.load(data_file)
# 変更開始
if 'rows' not in data_yml:
continue
sz = (data_yml['rows'], data_yml['cols'], -1)
# 変更終了
n_persons = sz[0]
keypoints = np.array(data_yml['data']).reshape(sz)
- もう一か所 OpenPose のアップデートによる変更がある
変更前 (--no_display というオプションはもうない)
# soccer3d/core.py:254
command = '{0} --model_pose COCO --image_dir {1} --write_keypoint {2} --no_display'.format(openposebin,
変更後(--display 0 --render_pose 0 を代わりにつける)
# soccer3d/core.py:254
command = '{0} --model_pose COCO --image_dir {1} --write_keypoint {2} --display 0 --render_pose 0'.format(openposebin,
- ほかの OpenPose のオプションに関してはここを参照
- これで再度実行し、
$DATADIR/poses.mp4が以下のように正しく選手の上にボーンを重畳させている形で生成されていたら成功

**
6. 各選手の切り出しを行う
検出されたポーズの情報を使って、選手を中心とした画像の切り出しを行う。その後 Instance Segmentation によって選手のみの切り出しをする。
- 以下を実行する
# 選手を中心とした画像の切り出し
python3 demo/crop_players.py --path_to_data $DATADIR
export OMP_NUM_THREADS=8
# ステップ1 で instancesegm のビルドが終わっている必要がある
# 選手の Instance Segmentation
./soccer3d/instancesegm/instancesegm --path_to_data $DATADIR/players/ --thresh 1.5 --path_to_model ./soccer3d/instancesegm/model.yml.gz
-
$DATADIR/playersフォルダが作られ、各フレーム中に出現する選手を切り出した画像(images)や、そのマスク画像(cnn_masks)、姿勢画像(poseimgs)、姿勢マスク(pose_masks)が生成される- 姿勢マスクは完全に Instance Segment されたもの
- 補足: Instance Segmentation について
- 領域分割(Segmentation)というタスクがあり、これは画像内のピクセルごとにラベルを予測する問題
- Segmentation には以下の二つのラベル付けの仕方がある
- Semantic Segmentation
- 各ピクセルにクラスのラベルを付与する
- 同じクラスに分類されるピクセルには同じラベルを付ける
- Instance Segmentation
- 個々の物体ごとに別のラベルを付与する
- 同じクラスであっても、別々のラベルを付与する
- Semantic Segmentation
- 今回は選手ごとに分けたいから Instance Segmentation
- 例) http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html
| 元画像 | Semantic | Instance |
|---|---|---|
 |
 |
 |
**
7. 深度情報を算出する
先ほどの二つのマスクを統合して、そのマスクを入力すると深度情報を出力してくれるネットワークに通す
- 深度ネットワークの重みをここから事前に
MODELPATH=/path/to/model/にダウンロード - 以下を実行
# MODELPATH=/path/to/model/
python3 demo/combine_masks_for_network.py --path_to_data $DATADIR
python3 soccer3d/soccerdepth/test.py --path_to_data $DATADIR/players --modelpath $MODELPATH
- 統合されたマスク(masks) と深度情報(predictions)が生成されていることを確認
**
8. 深度情報を点群データに、そしてメッシュにする
まずは深度情報を点群データに変換し、選手ごとにトラッキングして選手ごとのメッシュデータを作成する
- 以下を実行
# 点群データへ
python3 demo/depth_estimation_to_pointcloud.py --path_to_data $DATADIR
# 選手のトラッキング
# GUI 出力があるので RemoteDesktop で実行
python3 demo/track_players.py --path_to_data $DATADIR
# メッシュ生成
# GUI 出力があるので RemoteDesktop で実行
python3 demo/generate_mesh.py --path_to_data $DATADIR
-
点群データは
$DATADIR/players/meshesに保存される -
トラッキング実行時に以下のような画面が確認できる
-
また
$DATADIR/tracks.mp4が生成される -
テクスチャとメッシュデータは
$DATADIR/scene3dに保存される
HoloLens デプロイ編
- Unity プロジェクト のダウンロード
-
$DATADIR/scene3dをローカルにダウンロード- テクスチャとメッシュデータが混在しているので、事前に
meshesとimagesのフォルダに分けておく - こんな感じで
cd $DATADIR/scene3d; mkdir images; mkdir meshes; mv *.jpg images; mv *.obj *.mtl meshes;
- テクスチャとメッシュデータが混在しているので、事前に
- プロジェクトの起動、youtube シーンを開き、シーンを別名で保存
-
Assets/Resources/Imagesにテクスチャ、Assets/Resources/Meshes/Playersにメッシュデータを配置- 既存のデータが入っているので、それらは消去しておく
- Hierarchy で、 Scene->Players オブジェクトの子を消去してから、新しいメッシュデータを Players の子としてドロップ
- このとき Players のインスペクタでLayerを
Do not showに切り替える(子も同時に切り替える) - 選手がフィールドに半分埋まる状態になるので、全選手の y 座標を 1 にする
- このとき Players のインスペクタでLayerを
- Hierarchy で、 MainCamera の AssignTextureToObj を変更
-
STARTFRAMEには最初のフレーム番号(00はなくていい) -
ENDFRAMEには最後のフレーム番号(00はなくていい) -
GAMEOBJECT_PREFIXはフレーム番号の前に prefix があれば埋める。なければ空欄 -
GAMEOBJECT_POSTFIXはフレーム番号の後、拡張子の前に postfix があれば埋める。なければ空欄 -
IMAGE_PREFIXも同様 -
IMAGEPATHはAssetsからの相対パス
-
- MainCamera の ShowOneLayerPerFrame を変更
-
STARTFRAMEENDFRAMEGAMEOBJECT_PREFIXGAMEOBJECT_POSTFIXは同上 -
FPSは動画のFPS -
GOOD_LAYER表示したいレイヤーの番号(ここだと9) -
BAD_LAYER表示したくないレイヤーの番号(ここだと8)
-
- あとは通常の HoloLens アプリ通り UWP でビルドして、VisualStudio で HoloLens へデプロイ
このような画面が出ていればOK

終わりに
筆者は他の動画でも試したいと思って元動画の別のシーンから切り出してみたが、 カメラキャリブレーションのフェーズで最初の数フレームはうまくできていても、後半になるとズレていくようになった。
| 成功フレーム | 失敗フレーム |
|---|---|
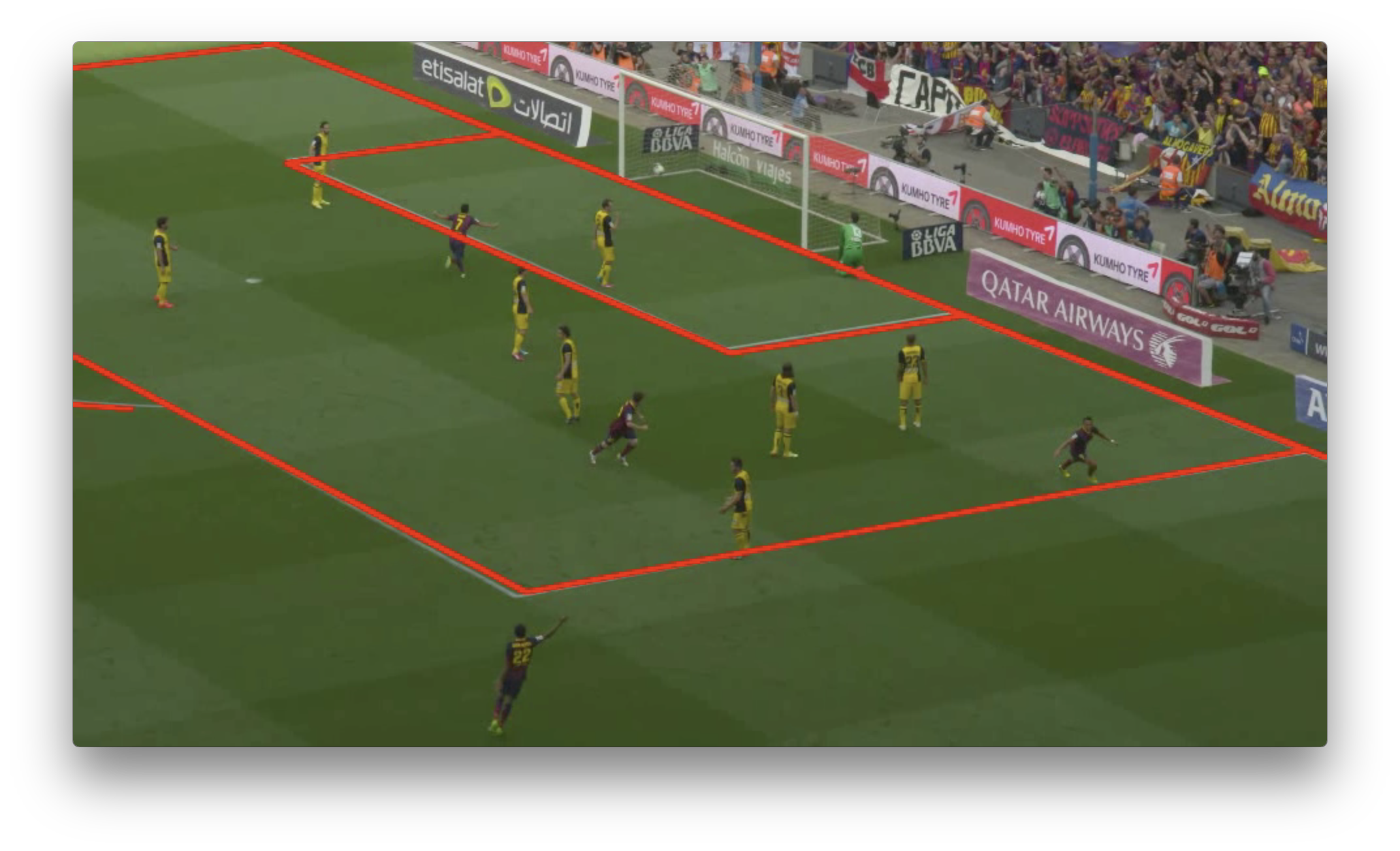 |
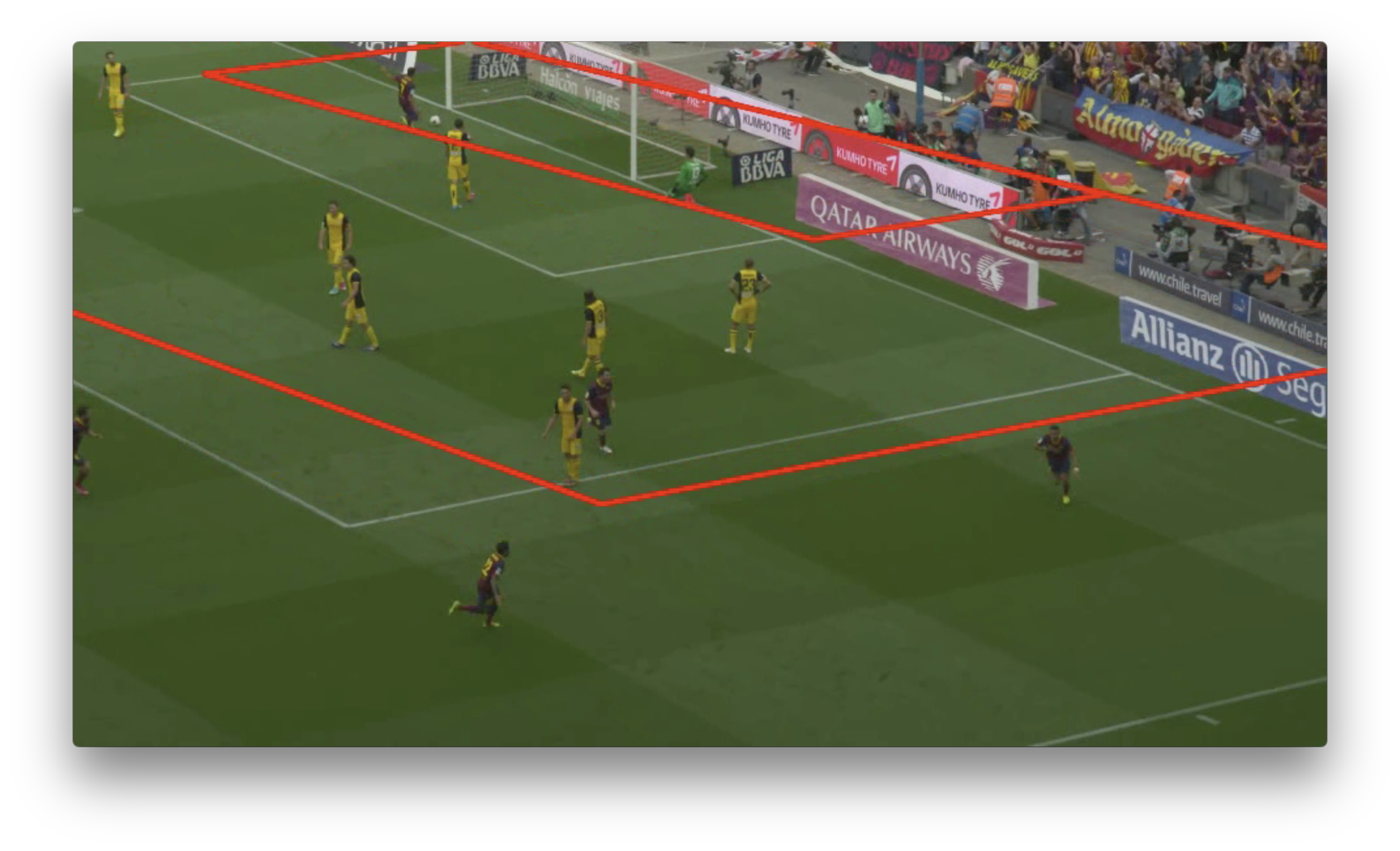 |
キャリブレーションフェーズではまず動画の最初のフレームのサッカー場との対応点を手動で指定することでカメラパラメータを求めるが、それ以降は、カメラパラメータはズームイン・ズームアウトによって変化してしまうため、補正を掛ける必要がある。
元プロジェクトでは calibrate_camera の 内の、 calibration.calibrate_from_initialization にて、最初のフレーム以降のカメラパラメータを推定しようとしているが、ここがうまくいっていないため、キャリブレーションの失敗が発生している。
本エントリではこの問題の解決に至っていないため、新しい動画を3D化したいと思う方は
- カメラのズームイン・ズームアウトが発生しないサッカー動画を見つける
- すべてのフレームを手動でキャリブレーションをする
-
calibration.calibrate_from_initializationでの推定精度を向上させる
という3つの選択肢があることだけ述べておく。