はじめに
機械学習に興味があり、最近勉強し始めましたが備忘録としてQuitaに記事を上げたいなと思って記事を書きました。もしなにか間違ってるところがあれば教えてくれるとありがたいです。
wandbとは
そもそもwandbとは実験結果の管理やモデルの最適化を補助してくれるありがたいサービスなのです。実験結果を見直したいなと思ったとき、わざわざモデルを実行してmatplotlibとかで描画しなくても、いつでもWandbのサイトから見ることができるのが特徴です
さらにレポート機能みたいなのがあるので、大学生とかであれば研究発表としても使えるんじゃないでしょうか。(レポート機能はまだ使ってないので間違ってたらごめんなさい)
こんな人向け
- web上で実験結果を保存していつでも見直せるようにしたい
- Wandbの使い方がいまいちよくわからない
とった人向けに作ってます。今回はWandbを使ったモデルの最適化とモデルの描画について書きたいと思います。
今回Kearsを用いてますが、Tensorflowとか別のフレームワークでも書けます。また気が向いたらそっち向けにも作ります
準備
まずpipを使ってwandbをインストールします
pip install wandb
その後wandbでサイトから会員登録をしてください。会員登録はすぐできますし、gitとの連携とかですぐログインすることができます。
その次にターミナルで
wandb.login()
をすると、APIキーを打つような指示が出てくるのでそれに従ってAPIキーを打ち込んでください。右上の設定からAPIキーを得ることができます
Wandbの実装
冒頭に以下のコードを記入します。
import wandb
wandb.init(project = 'project')
config = wandb.config
projectには適当な名前を入れてください。これがプロジェクト名であり、プロジェクトごとにデータをまとめることができます。便利ですね。
次にconfigメソッドに保存したい引数をいれてください。このとき、configメソッドは辞書型で保存する必要性があるのでそこは注意してください。
CONFIG = dict(
NUM_FRAMES = 10,
BATCH_SIZE = 5,
EPOCHS = 8,
IMG_SIZE = 256,
NUM_IMAGES = 64,
lr = 1e-4
)
あとmodel.fitのcallbacksに一行追加するだけでできます(Kerasの場合)
model.fit(
train_dataset,
validation_data=valid_dataset,
epochs=CONFIG['EPOCHS'],
shuffle=True,
verbose=1,
callbacks = [WandbCallBack()],
)
callbacksをこんな感じで書くだけであとは学習結果をWandbに保存してくれます。
このときWandb上はこんな感じになってます。これでいつでも実験結果をweb上から見ることができます。ほんと数行でできるのはすごいですよね。
Wandbを用いたグリッドサーチ
先ほどの結果を踏まえて、ちょっとパラメータ変えてみたいなってときにSweepというのを使います。これはWandbが勝手に先ほどの学習結果を踏まえてグリッドサーチをしてくれるっていう機能です。これは文献が少なくて少し苦労しました。
Sweepの実装
まずWandbサイトのプロジェクトから以下の写真の左側のほうきみたいなマークを押してそのあと、右側のCreate sweepを押してください

すると以下のようなものが出てくるので、initalize Sweepというボタンを押します
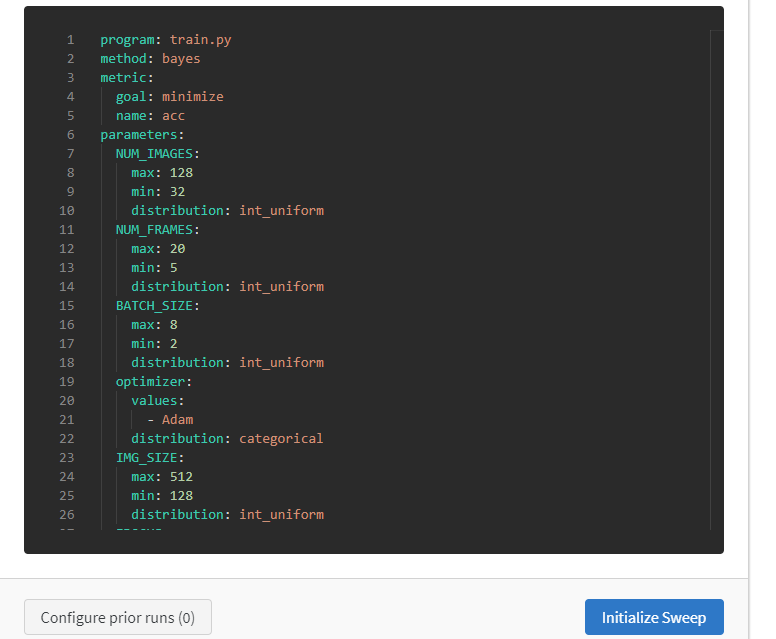
すると、こんなページが開かれるのでここからyamlファイルをダウンロードします
その後、その下に書いてあるコマンドを実行します
wandb sweep --update ユーザー名/プロジェクト名/id名 sweep.yaml
これであとは勝手にWandb側が実行してくれます。ちなみにpythonファイルとyamlファイルのフォルダの配置に気をつけてください。
グリッドサーチをしている最中ですが、こんな感じのプロットを勝手に書いてくれます
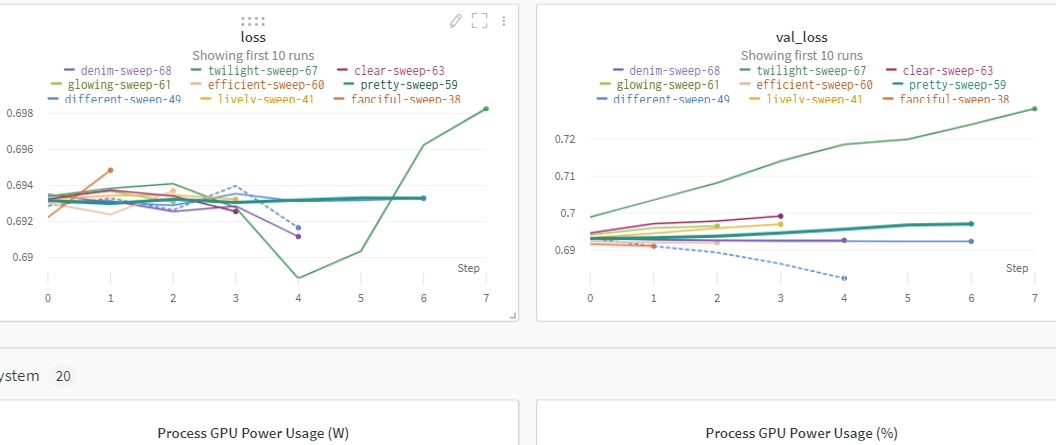
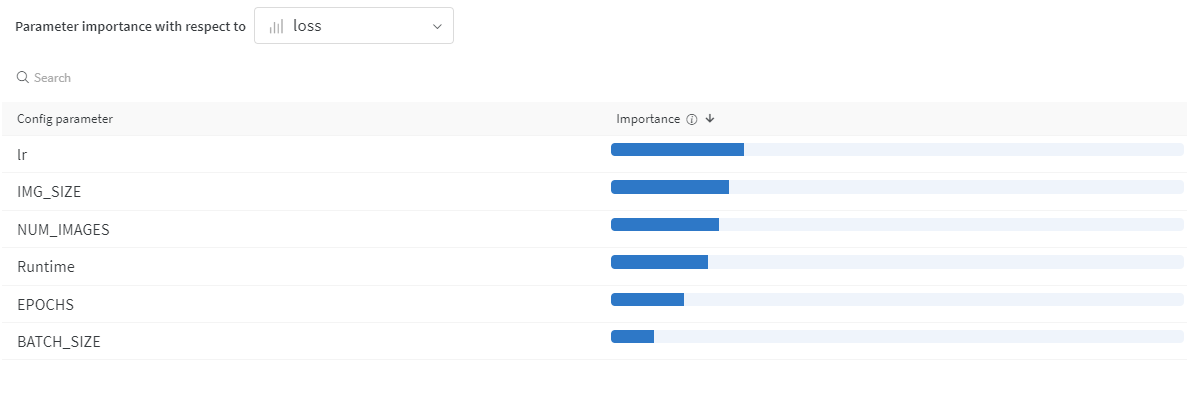
それと同時に、各パラメータがどれだけ影響しているのかといった情報まで、わかりやすくグラフ化してくれており、うまく扱えばパラメータモデルの精度向上に大きく役に立つかもしれません。
しかし問題点として、このグリッドサーチは永久に続くっぽいです。なので、
wand agent --count 回数 ユーザー名/プロジェクト名/sweep名
のように、countの引数で回数を指定してあげた方がいいかもしれないです。
あとは勝手にwandb側がやってくれるようですが、複数のパソコンを使って分担しながらグリッドサーチをすることが出来るっぽいです。これによって時間短縮がかなり出来るかも知れないので出来る環境がある方はやってみてください。