Unsupervised Domain Adaptation for Distance Metric Learning 要約
読んだ論文
Unsupervised Domain Adaptation for Distance Metric Learning
Kihyuk Sohn, Wenling Shang, Xiang Yu, Manmohan Chandraker
https://openreview.net/forum?id=BklhAj09K7
上記の論文を読んだので簡単にまとめます.ICLR2019の採択論文です.民族間の顔認識課題においてSOTAらしいです.OpenReviewの著作権ポリシーが明確にわからなかったので,一応上記URLの論文から一部の図や本文を引用させていただいておりますことをここに宣言し,謝意を示します(いつも引用論文には感謝しています).
3行でまとめる
- 教師なしドメイン適応でよく使われる2つの手法(domain discrepancy reduction learningと半教師あり学習)はソースターゲット間でラベル空間を共有しない場合に適応できない.
- 変換されたソース空間と位置合わせしながらターゲットの特徴空間を元のソース空間から分離する機能転送ネットワーク(FTN)を提案する.
- また,FTNを更に精度向上させるための損失関数も提案する.
再定式化
従来のドメイン適応問題のリスクの定義では,本研究が対象とする問題(ソースターゲット間でラベル空間を共有しないケース)において適応できない.なので問題を次のように考え直す(本稿は画像を対象としているので画像ベースで話す).
入力を2つの画像し,出力を1(両画像は同じ身元を共有する),0(しない)とする.
なお,入力となる2つの画像は同じドメイン内から選択されるものとする.(と書いてあったのだが,提案手法の章では次のように書かれていた.)この場合,ペア$(x, x')$は次のような3つのシナリオが考えられる.$x,x'\in X_S$,$x,x'\in X_T$,$(x\in X_S, x' \in X_T)$.ここで前2つをwithin-domain verification,最後をcross-domain verificationと呼ぶことにする.
提案手法
提案モデル
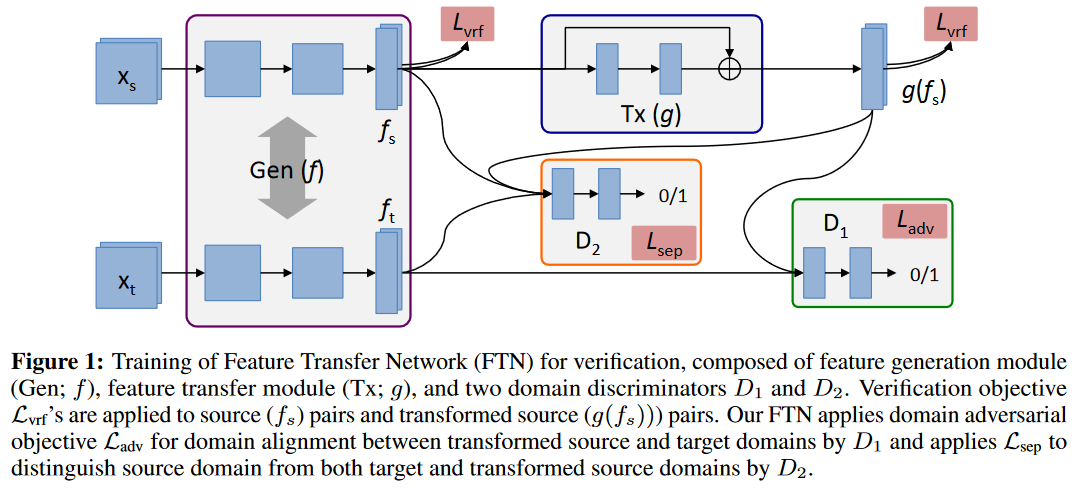
上記モデルによって最終的に提案手法は以下のような能力を訓練したい.
- $(x,x')$が異なるドメインから来ている場合,feature generation module($f(・)+D_2$のこと?)の機能により,$f(x), f(x')$の距離は遠くなってほしい.
- $x,x'\in X_S$の場合,$h_f$($f_S$用の$L_{vrf}$を学習する分類器のこと)により,同じクラスの場合は距離が近く,違う場合は遠くなってほしい.
- $x,x'\in X_T$の場合,ドメイン敵対訓練と$h_g$($g(f_S(・))$用の$L_{vrf}$)により,同じクラスの場合は距離が近く,違う場合は遠くなってほしい.
損失関数
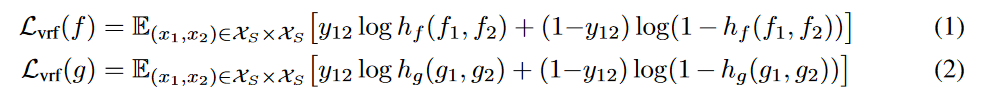
Figure1上部の$L_{vrf}$,長々書いてあるが,これは非常にシンプルに入力された2つの画像が同じクラス(1)か違うクラス(2)かを識別する際のLogLossである.fの場合がFigure1の左側の$L_{vrf}$で,gの場合が右側である.
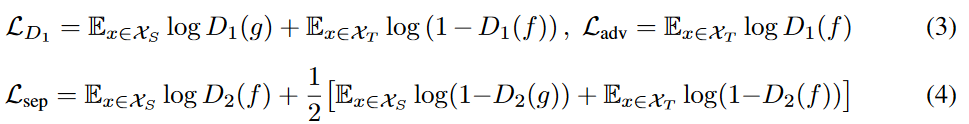
Figiure1右下のdiscriminator,式(3)の$L_{D_1}$,これも非常にシンプルで,ソースから来た$g(f(x_t))$とターゲットから来た$f(x_t)$を弁別する際のLogLoss.ちなみにこの$g(f(・))$を$f(・)$にするとシンプルなDANN.一方$L_{adv}$これは何が言いたいのかよくわからない.
続いてFigure1中段のdiscriminator,式(4)の$L_{sep}$を読むと,ソースから来た$f(x_s)$を1として,ソースから来たが$g(f(x_s))$の場合とターゲットから来た$f(x_t)$の場合を0として弁別する際のLogLoss.こいつが重要な気がしてならないのだが,なぜこの損失を組むのかがわからない...
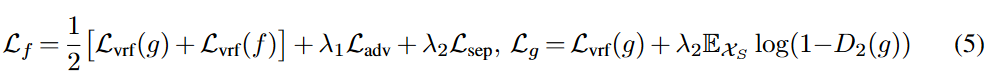
最終的に提案手法FTNを訓練する際の全体の損失として式(5)を定義する.訓練は$D_1$と$(f,g,D_2)$を交互に行うらしい.
以下4/4追記.
GANでよくあるmode-collapse問題を回避するために,式(6)の$L_{recon}$を使っている.ソースドメインの表現がすでに最適に近いと仮定すると,ソースドメインに対して事前トレーニングされた$f_{ref}$に類似するように特徴を正規化する(トレーニング中に$f_{ref}$固定される).また,それほど強調されていない($\lambda_4 < \lambda_3$)正則化項をターゲットドメインにも実施する.これにより,mode-collapseを回避しつつ,ターゲット側の特徴表現にはより多くの逸脱の余地を残す.
$L_{recon}=-[\lambda_3E_{x\in X_S}||f(x)-f_{ref}(x)||_2^2$
$ + \lambda_4E_{x\in X_T}||f(x)-f_{ref}(x)||_2^2]$ ... (6)
また,上述した2組の画像ペアを入力にする手法では深層距離学習を行うには少し弱いことが実験的にわかったため,以下の式(7)で定義されるN-pair Lossで再定義し,最終的な全体の損失関数を式(8)に置き換える.
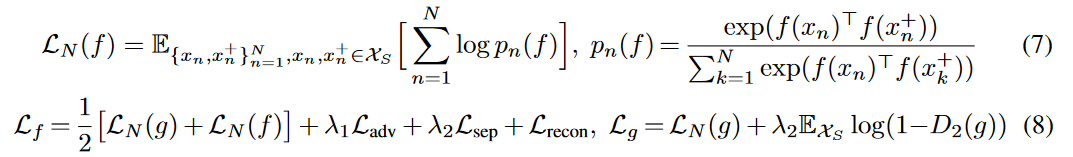
ここで,$x_n,x_n^+$は同じクラスで,$x_n,x_k^+(n \neq k)$は別のクラスの入力であることを示す.
エントロピー最小化
エントロピー最小化は教師なしドメイン適応で人気の手法である.ラベルなしデータはクラス予測の分布のエントロピーを最小化するような損失関数で学習される.ここで,エントロピー最小化を本課題の事例に沿った形にすると以下のようになる.
$L_{vrf}^{ent}(f)=E_{x_i,x_j\in X_T}[p_{ij}\log p_{ij}+(1-p_{ij})\log (1-p_{ij})]$
ここで$p_{ij}$は$p_{ij}(f)=\sigma(f(x_i)^{\mathrm{T}}f(x_j))$
また,N-pair Lossに対応したマルチクラスエントロピー最小化をターゲットドメインに実施するために次式も使用する.
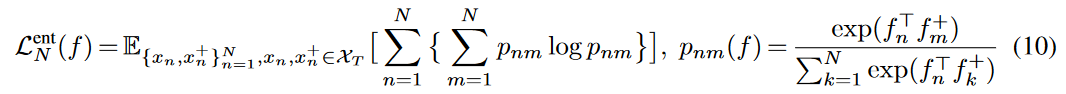
評価実験
MNIST-MからMNISTへの教師なしドメイン適応を行い,表現抽出部分を可視化した結果,DANNよりもきれいにクラスを分割できていることを確認した.また,民族間の顔認識ドメイン適応問題にて評価した結果,DANN<FTN<DANN&MCEM<FTN&MCEMとなった.MCEM(Multi Class Entropy Minimization)は式(10)のこと.
所管
とりあえず前半までで2時間くらい.途中から失速したので,残りは明日再度まとめようと思います.
4/4に後半戦を追記しました.読了に追加1時間くらい.ここまで複雑なモデルになってくると一つのモデルで損失関数の定義が多すぎて,わけがわかりませんね...最近思うのは,DLが出る前は特徴抽出職人と呼ばれた機械学習研究者たちが,今はモデル&損失関数職人に移行したという感じがします.データから特徴取る部分を人間の感性に頼っていた時代から,データから特徴を取る方針を人間の感性で設計する時代になったって感じでしょうか.