Pyramid Scene Parsing Network 要約
読んだ論文
Pyramid Scene Parsing Network
Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
https://arxiv.org/abs/1612.01105v2
上記の論文を読んだので簡単にまとめます.ADE20Kデータセットで現在SOTA取っている(らしい),SemanticSegmentationの研究.CVPR2017の論文で,現在1600引用程.
3行でまとめる
- ピラミッド構造のPoolingを挿入する手法を提案した.
- これにより局所的情報だけでなく大域的情報を獲得することに成功した.
- ADE20Kデータセットで評価した.それを使うときに気をつけることもまとめた.
ADE20Kで気をつけること
Mismatched Relationship
モノとモノの間の関係(Context-relationship)が重要なので,それを意識すればより高度な予測ができる.例えば,湖の上にボートがある状況で,FCN(従来手法)だと車と予測されているが,これは湖の上という位置関係が見えれば改善できるはずである.
Confusion Categories
(意味的にも)似ているけれども,違うラベルが与えられているモノが存在することが,精度を悪くしている.例えば,山と丘,壁と家と建物と超高層ビル等など.カテゴリ間の関係を利用することで改善できるはず.
Inconspicuous Classes
適切なグローバルシーンレベルの分布がわかると,シーンレベルのパフォーマンスが向上できるはず.すなわち,大きすぎるものと小さすぎるものが混在している場合,分類が難しくなるケースが有るので注意を払って見る必要がある.
- 上記3つの問題点より,ネットワークはより広域な特徴を意識してセグメンテーションを行う必要がある.
提案手法
- 既存手法は,各sub-regionから有益な情報を抽出してはいるものの,その後平坦化及び連結されているため,それぞれ独立た情報として取り扱われている.
- 一方,各sub-regionのみでなく,周囲のsub-regionから情報を抽出できれば,より高度な表現を獲得することができるであろう.
- 従って,Fig.3のピラミッドPooling構造の導入を提案する.
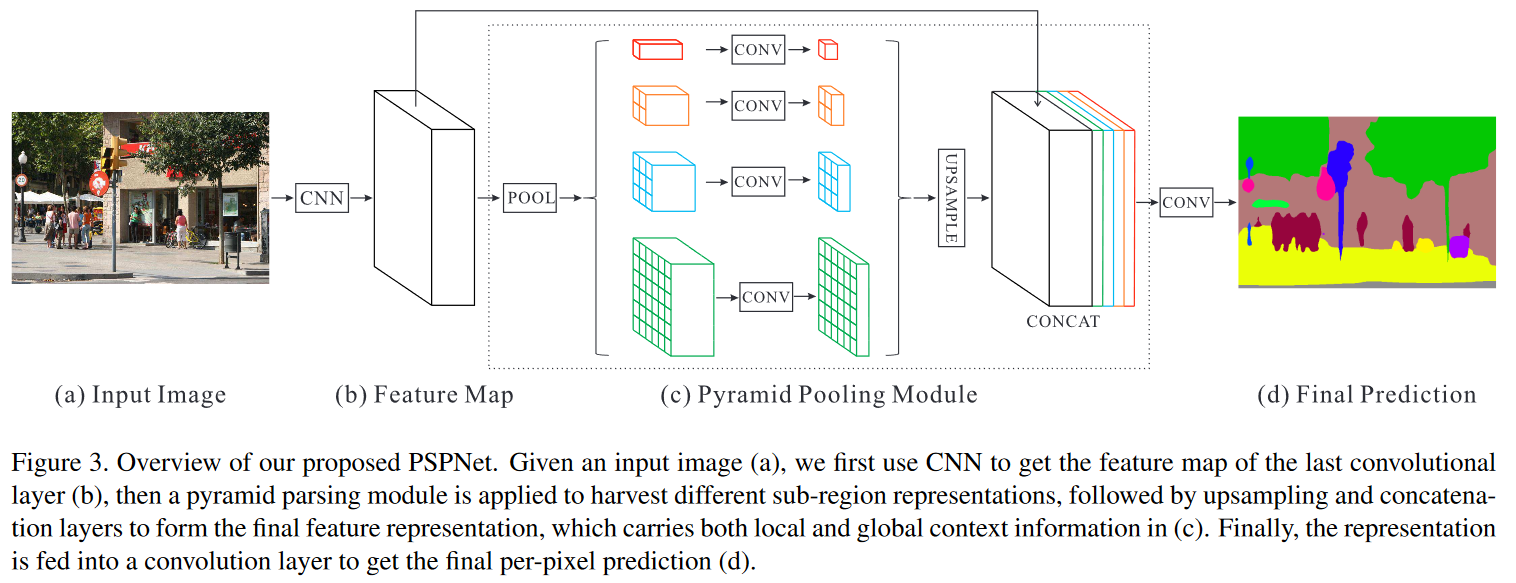
Pyramid Pooling Module
図のPyramid Pooling Moduleの手順は以下の通りである.
- 与えられた特徴マップを,11,22,33,66で4種類のPoolingを行う.
- それぞれに,1*1Convでチャネル数を1/Nに揃える.
- それぞれにBilinear補完でUPSAMPLEし,同じサイズに整えた上で,Concatenateする.
なお,上記のPoolingサイズは可変で,かつN(ピラミッドの段数:Poolingの種類数)も可変である.
全体のモデル構造
図のモデル構造全体を説明する.
- 入力をCNN(今回はResNet50)に通し,1/8のサイズの特徴マップが得られる.
- 特徴マップをPyramid Pooling Module(PPM)に通す.
- 元の特徴マップと,PPMを通した結果と結合する.
- 残りのConvolutionの説明は無いが,従来のEncoder-Decoderモデルと同じ?と思われる.
評価実験
いろんなデータセットで,いろんな手法と比較評価を行った結果,一番良かったよ.
所管
勉強会として数名で1時間半くらいで読了+記事作成.1時間半という制限内で読み解く練習?