2022/10/20:plotnineのテーマも記事にしました。

はじめに
Rにggplot2という視覚化パッケージがあり、このPython版が plotnine です。
Python の視覚化といえば、matplotlib、seaborn が代表格。この他にBokeh やPlotly 等 さまざまありますが、ggplot2(=plotnine)でしか描けないグラフもあり、これがまたいいんです。
見た目が美しく、美しいからこそ可読性も高い、ありがたいライブラリです。
この記事では、sklearn のワインのデータセットで plotnine ならではの ヒストグラム、箱ひげ図、散布図を描きます。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行
ワインデータセットは、イタリアの同じ地域における3種類の異なるワインの化学分析の結果です。
- alcohol: アルコール度数
- malic_acid: リンゴ酸
- ash: 灰分
- alcalinity_of_ash: 灰分のアルカリ度
- magnesium: マグネシウム
- total_phenols: 全フェノール含量
- flavanoids: フラボノイド
- nonflavanoid_phenols: 非フラボノイドフェノール
- proanthocyanins: プロアントシアニン
- color_intensity: 色の濃さ
- hue: 色相
- od280/od315_of_diluted_wines: 希釈ワインの280nmと315nmの吸光度の比
- proline: プロリン
- target:class_0、class_1、class_2(ワインの種類)
※説明変数はalchol〜prolineまで全13個あり、目的変数はtargetでワインの種類(3種類)となっています。
まず気になるのは、ワインの種類の違いが表現できそうな説明変数はあるだろうか?ということです。
このような時、pairplotがとても役に立ちます。
datasetを読み込んだ後、seaborn-analyzer でpairplotを描いてみました。

seaborn-analyzer のpairplotは可読性が高くて、とてもいいです。
ワインの種類の違いを1つの変数だけでとらえるのは難しそうですが、まずalcoholのヒストグラムをplotnineで見てみてみます。
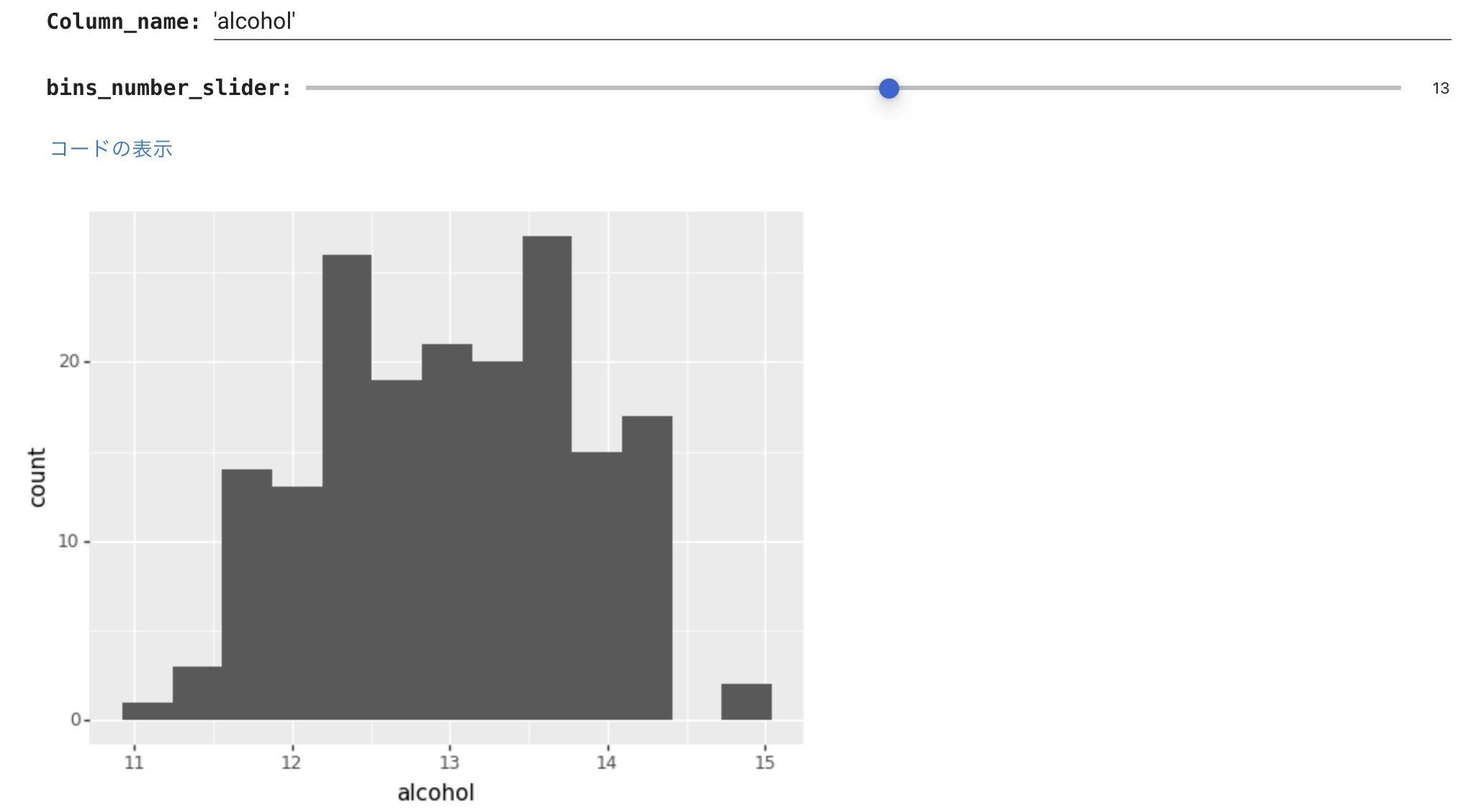
このヒストグラムでは何の特徴も掴めませんので、ワインの種類毎に層別したヒストグラムをplotnineで描きました。
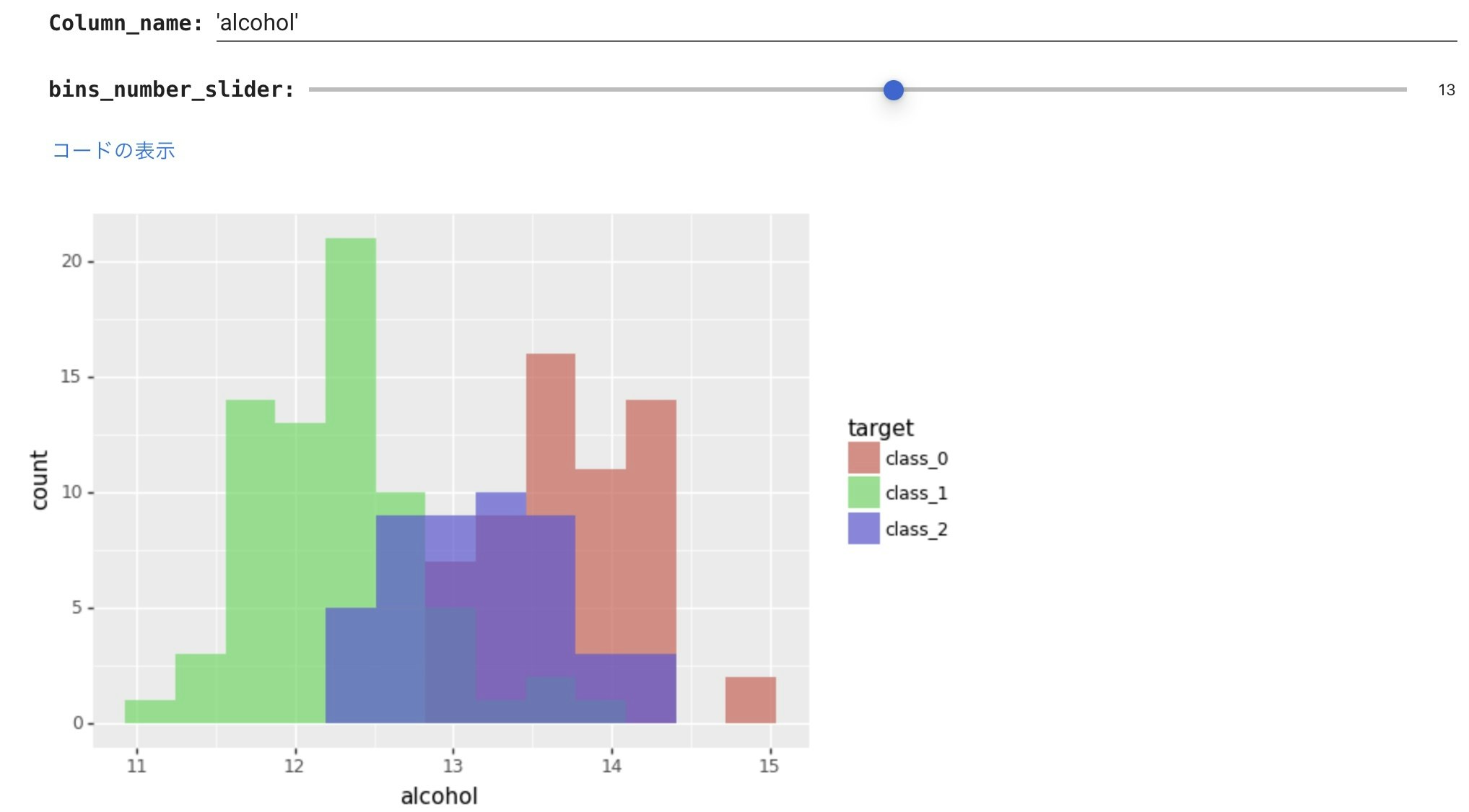
重なりあっているところも多いですが、ワインの種類ごとにアルコール度数が違ってそうだなということがよくわかります。
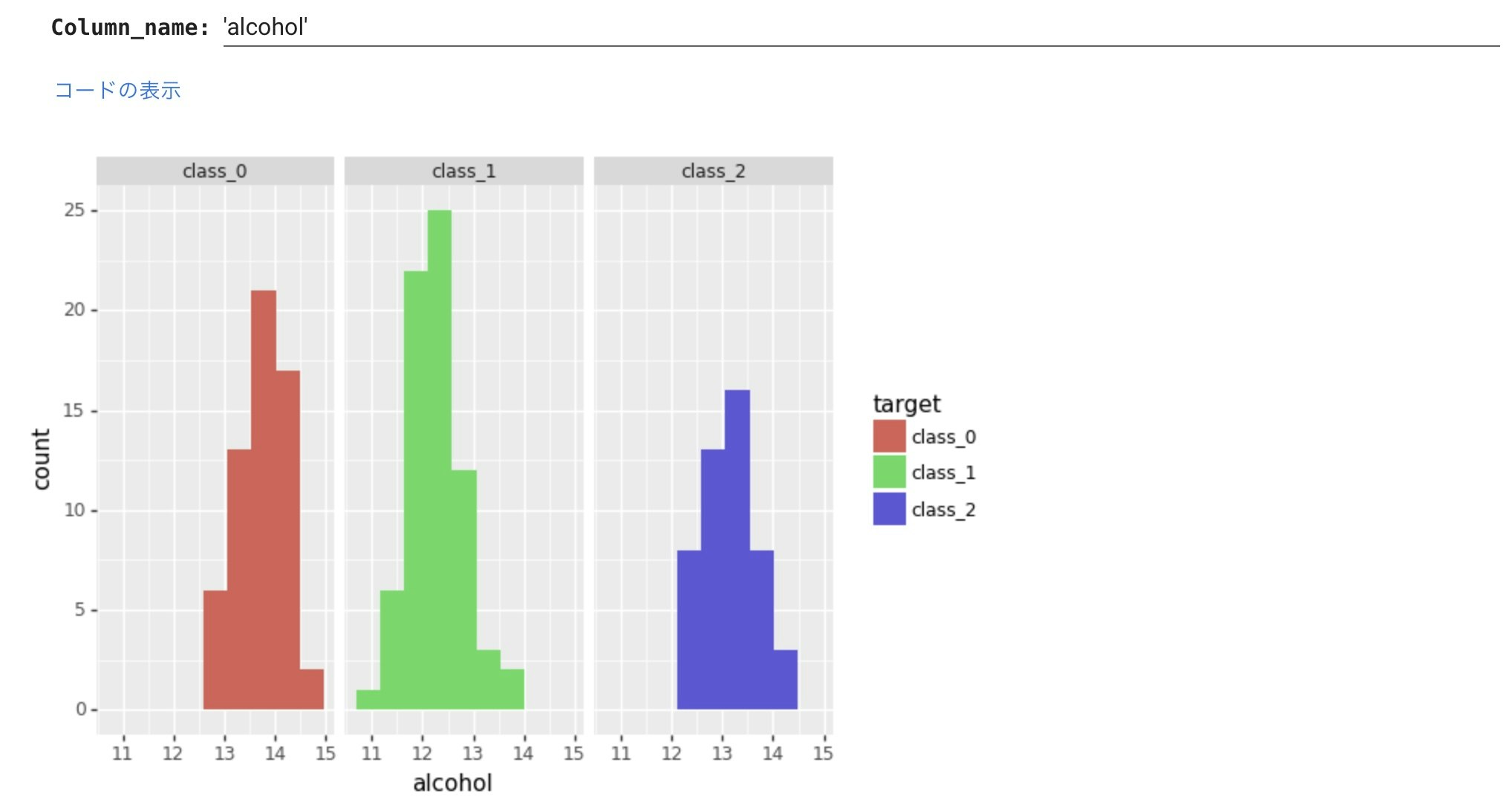
次にワインの種類ごとのヒストグラムを横に並べて描いてみます。
plotnineはこのような表現が簡単にできるのがひとつの特徴です。
箱ひげ図でも同じように描いてみます。
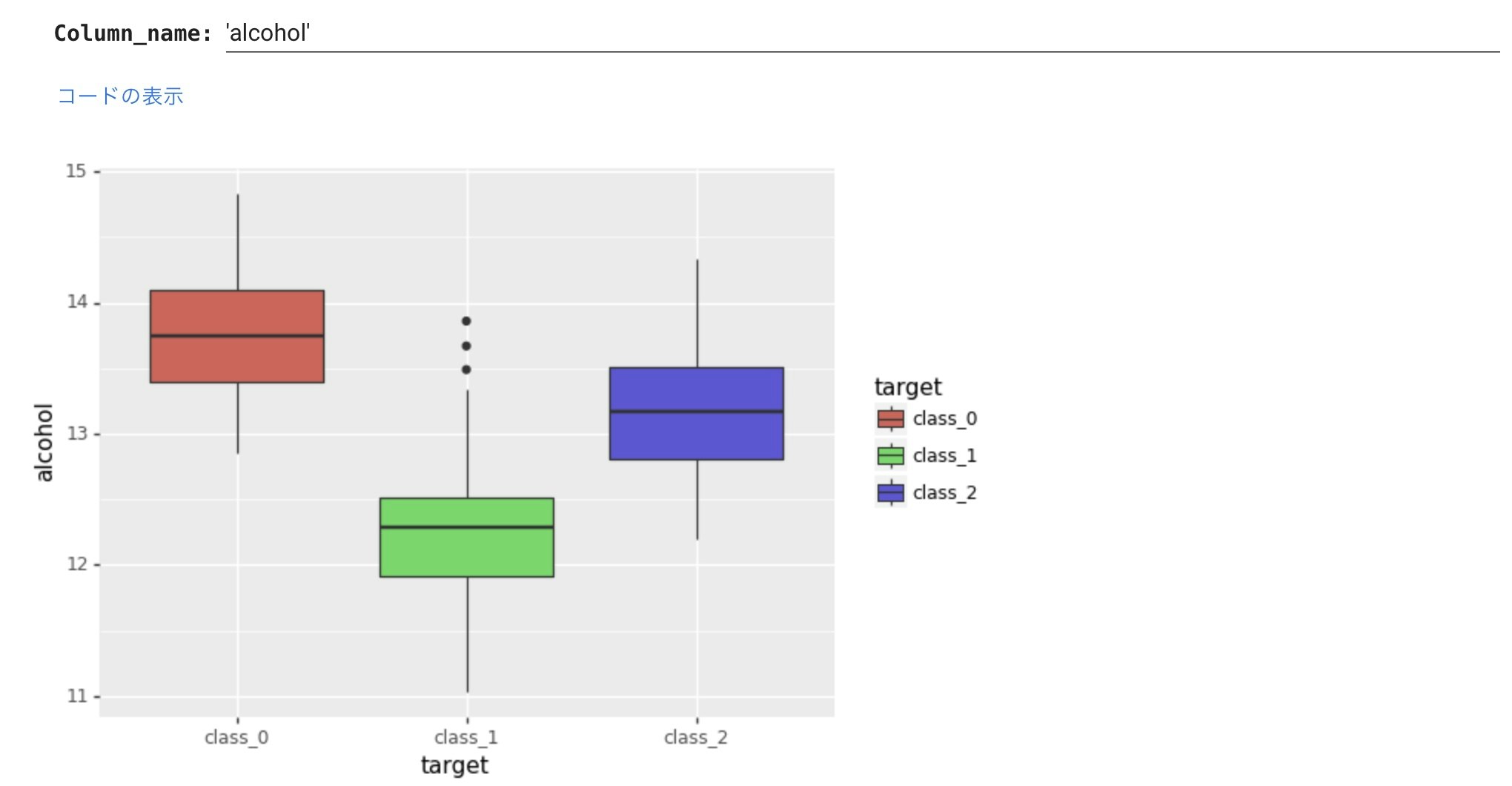
ワインの種類によってアルコール度数の中央値に違いがあることがより視覚的にわかります。
次に、先のヒストグラムと同じ要領で、ワインの種類ごとの箱ひげ図を横に並べて描いてみます。
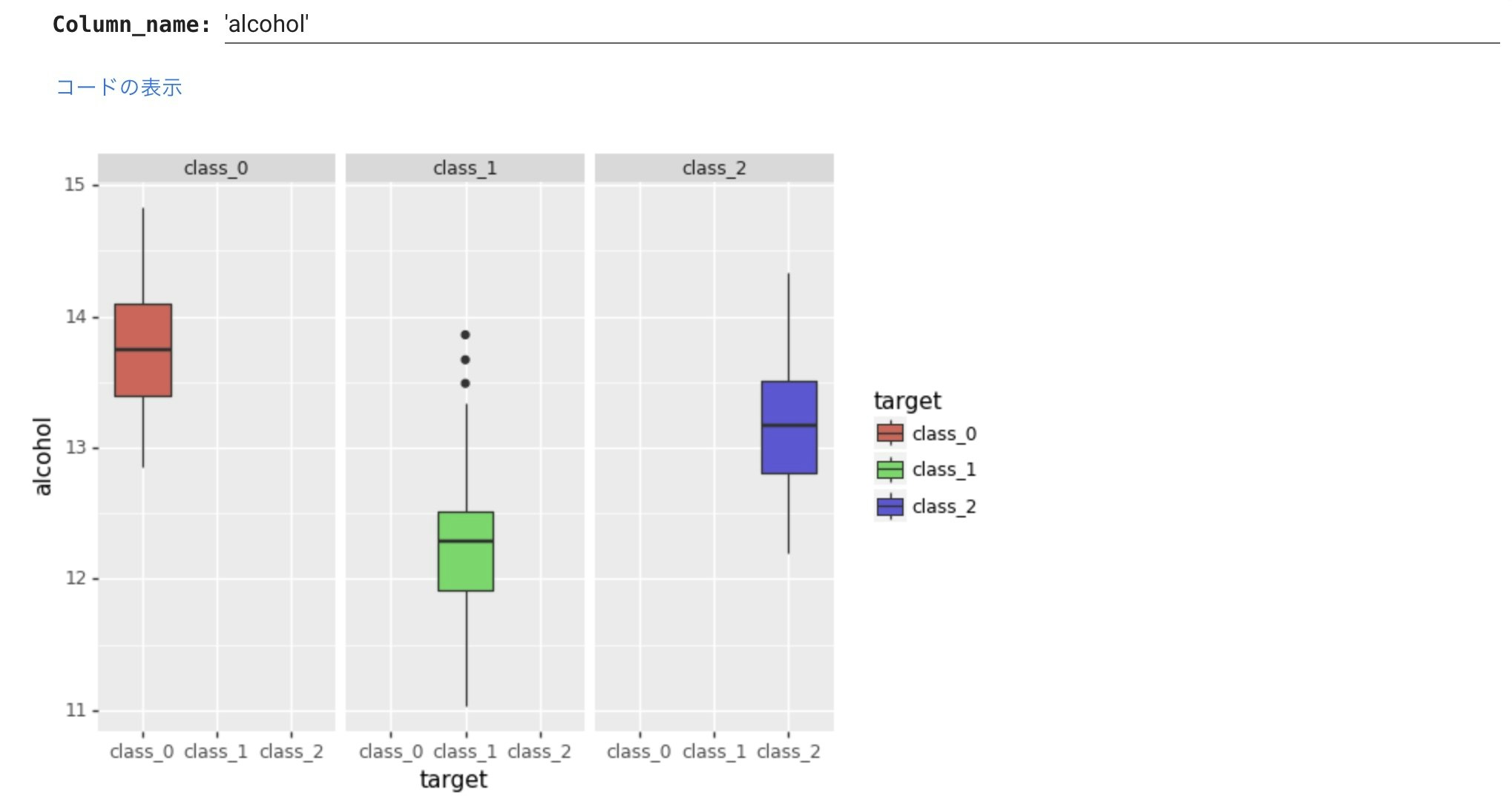
これは、わざわざ独立して描く必要はなかったですが、このような描き方がplotnineで簡単にできます。
次に散布図です。
最初に描いたpairplotで、 alcoholとod280/od315_of_dliluted_winesの関係がもっともワインの種類の違いを区分しているように見えましたので、これで描きました。
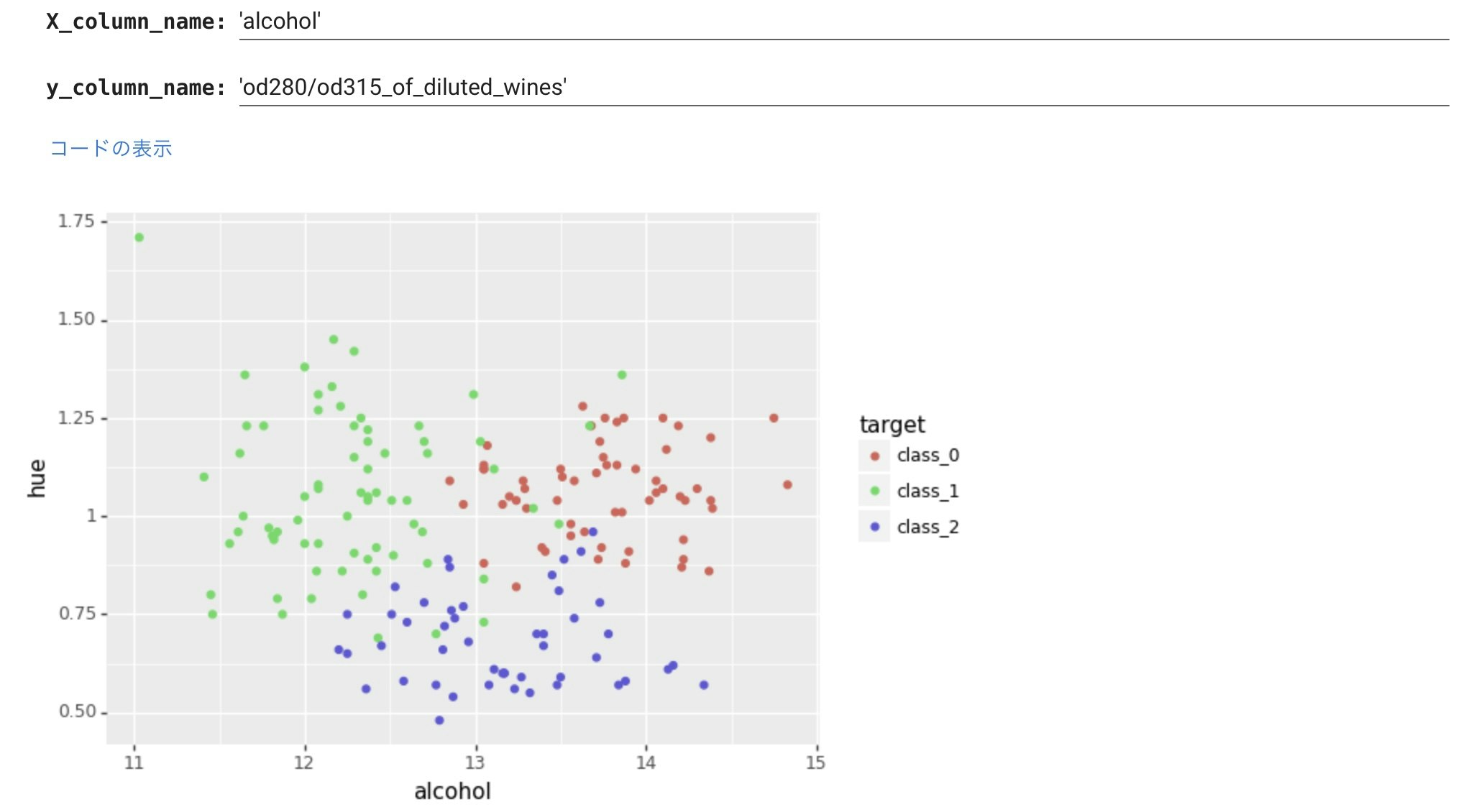
層別表示できているのでわかりやすいですね。
次は、ワインの種類ごとの散布図を横に並べて描いてみます。
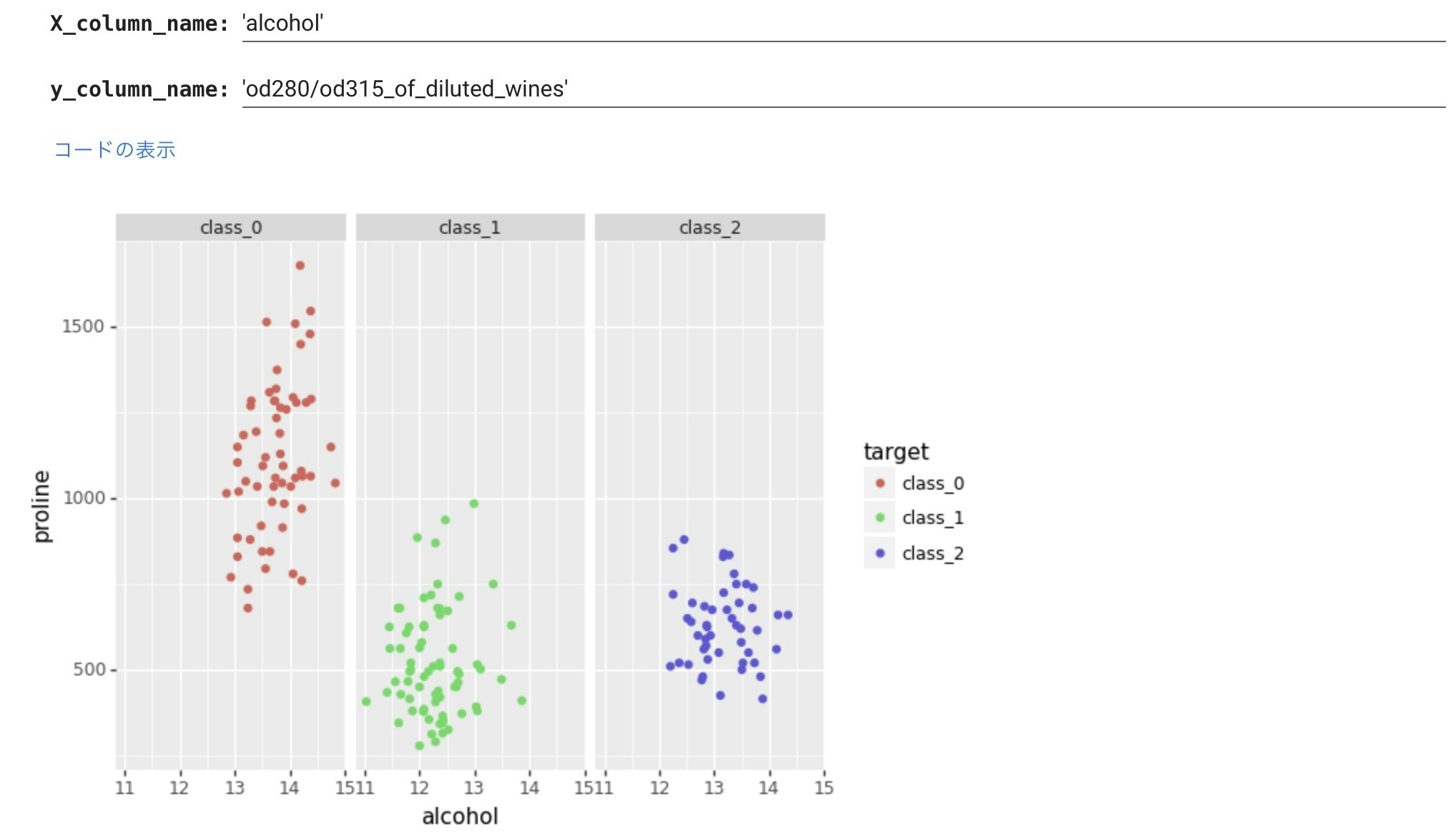
わかりやすいですね。
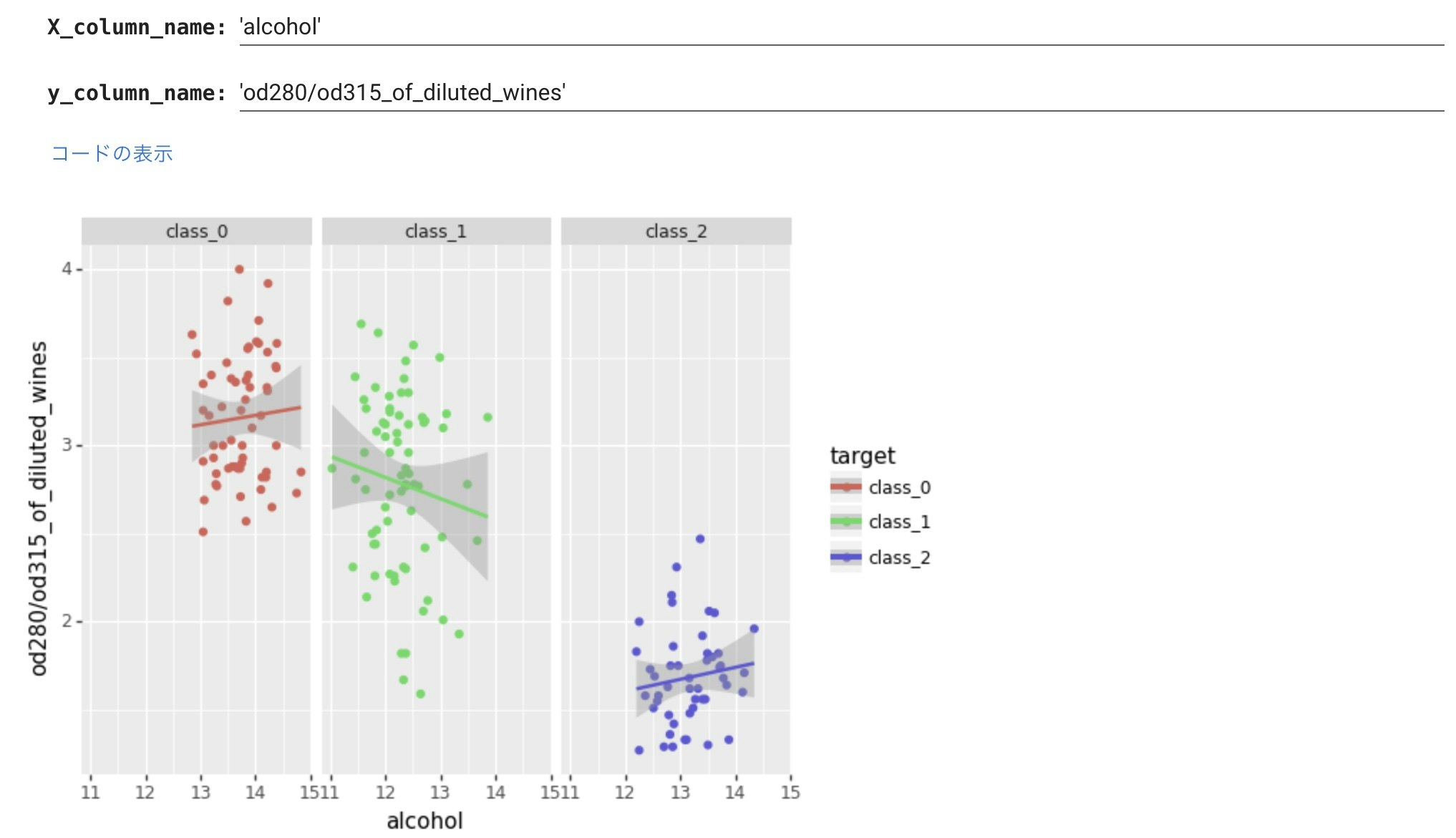
あと、plotnineでは、線形回帰を表示することもできます。
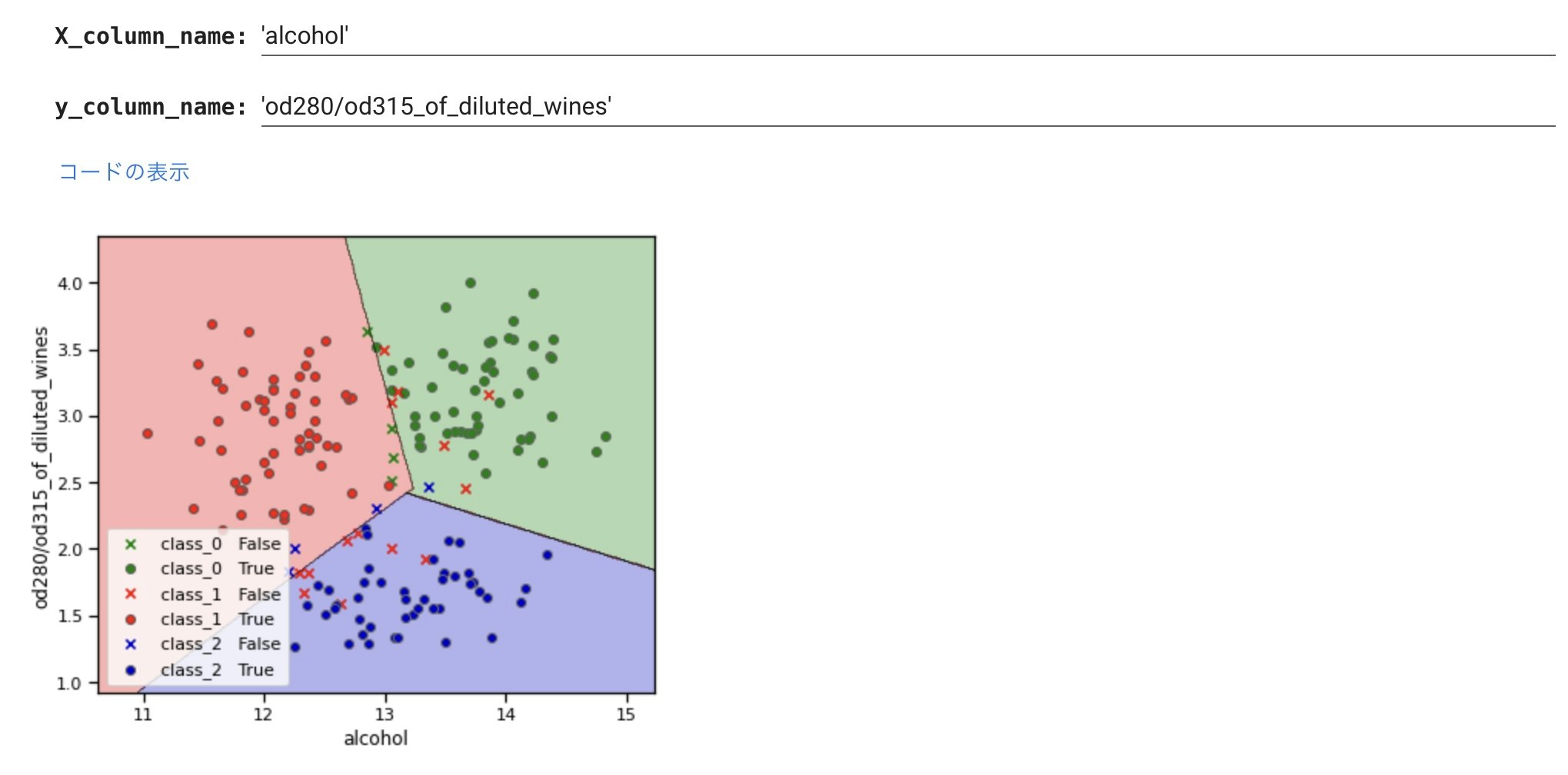
以下は、参考ですがseaborn-analyzer のclass_separator_plot で描いたものです。
SVCによるクラス分けを可視化してくれます。
最後に、plotnine のfacet設定を紹介します。
以下は、Titanicデータセットをfacet設定を利用し、可視化したものです。
X軸:age(乗客年齢)、Y軸:fare(運賃)の散布図+alive(生死)色分け(層別)+sex(性別)とclass(客室クラス)毎のマトリクスとなっています。
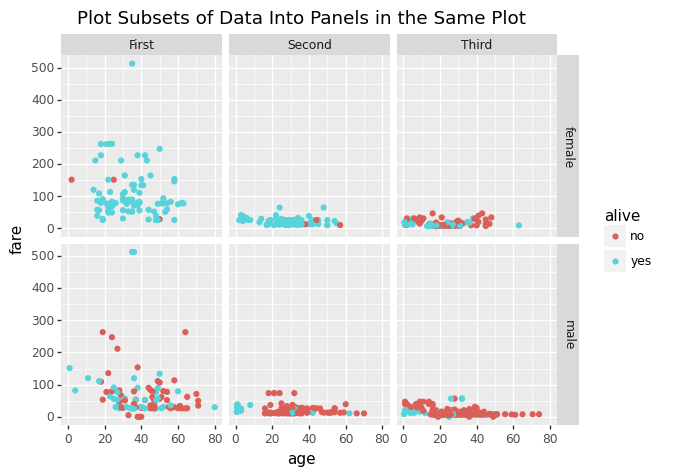
男性・女性で見ると、女性の生存が男性を圧倒しています。
男性は、セカンドクラス・サードクラスはほぼ全滅ですが、ファーストクラスのみ生存率が高くなっています。
また、すべてのクラスで幼児は救われたように見えます。
女性は、生存率は高かったようですが、サードクラスのみ亡くなったの多さが顕著です。
「女性・子供は守られた」、「金持ちは優先された」のでしょう。
このようにfacet設定を利用すると、可読性の高いグラフ配置が可能です。
実行コード
以下は、seaborn-analyzer のインストールです。
!pip install seaborn-analyzer
以下で、データセットがドロップダウンで選択できるよう、GoogleColabのフォーム機能でセット。
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'wine : classification' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Iris :classification', 'Loan_prediction :binary',"wine : classification", 'Upload']
以下は、先のドロップダウンで設定したデータセットを読込むコードです。読込み後はデータフレームに格納します。
#@title Load dataset
#ライブラリインポート
import numpy as np
import pandas as pd
import seaborn as sns
import warnings
warnings.simplefilter('ignore')
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
dataset = load_diabetes()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
X = df.drop(['Survived'], axis=1) # 目的変数を除いたデータ
y = df['Survived'] # 目的変数
df = pd.concat([X, y], axis=1)
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1) # 重複しているカラムを除いたデータ
y = df['alive'] # 目的変数
df = pd.concat([X, y], axis=1)
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['target'] = iris.target_names[iris.target]
elif dataset == "wine : classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
df['target'] = wine.target_names[wine.target]
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
else:
from sklearn.datasets import load_boston
dataset = load_boston()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
#X = pd.DataFrame(dataset.data, columns=dataset.feature_names)
#y = pd.Series(dataset.target, name='target')
source = df.copy()
FEATURES = df.columns[:-1]
TARGET = df.columns[-1]
X = df.loc[:, FEATURES]
y = df.loc[:, TARGET]
df.info(verbose=True)
df.head()
以下で、カラムをデータ型区分して表示させています。
※注意:categoryやboolもNumerical_columns:に区分されます。
#@title Datasetの数字・文字列区分
numerical_col = []
Object_col = []
for col_name, item in df.iteritems():
if item.dtype == object:
Object_col.append(col_name)
else:
numerical_col.append(col_name)
print('-----------------------------------------------------------------------------------------')
print('Numerical_columns:', numerical_col)
print('-----------------------------------------------------------------------------------------')
print('Object_columns:', Object_col)
print('-----------------------------------------------------------------------------------------')
以下は、seaborn-analyzer によるpairplotの実行です。
#@title Pairplot
from seaborn_analyzer import CustomPairPlot
cp = CustomPairPlot()
cp.pairanalyzer(df, hue=TARGET)
ヒストグラム
#@title Histgram
from plotnine import *
Column_name = 'alcohol'#@param {type:"raw"}
bins_number_slider = 13 #@param {type:"slider", min:5, max:20, step:1}
(ggplot(df, aes(Column_name))+ geom_histogram(bins = bins_number_slider))
#@title Stratified histogram by target
Column_name = 'alcohol'#@param {type:"raw"}
bins_number_slider = 13 #@param {type:"slider", min:5, max:20, step:1}
from plotnine import *
(ggplot(df, aes(Column_name, fill = TARGET))
+ geom_histogram(bins = bins_number_slider, position = "identity", alpha = 0.7)
)
#@title Histogram for each target variable
Column_name = 'alcohol'#@param {type:"raw"}
from plotnine import *
(ggplot(df, aes(x = Column_name, fill = TARGET))
+ geom_histogram()
+ facet_wrap(TARGET))
箱ひげ図
#@title Stratified box-plot by target
Column_name = 'alcohol'#@param {type:"raw"}
from plotnine import *
(ggplot(df, aes(TARGET, Column_name, fill = TARGET))
+ geom_boxplot())
#@title box-plot for each target variable
Column_name = 'alcohol'#@param {type:"raw"}
from plotnine import *
(ggplot(df, aes(TARGET, Column_name, fill = TARGET))
+ geom_boxplot()
+ facet_wrap(TARGET))
散布図
#@title Stratified scatter-plot by target
X_column_name = 'alcohol'#@param {type:"raw"}
y_column_name = 'od280/od315_of_diluted_wines'#@param {type:"raw"}
from plotnine import *
(ggplot(df, aes(x=X_column_name, y=y_column_name, color= TARGET))
+geom_point())
#@title Scatter-plot for each target variable
X_column_name = 'alcohol'#@param {type:"raw"}
y_column_name = 'od280/od315_of_diluted_wines'#@param {type:"raw"}
from plotnine import *
(ggplot(df,aes(x=X_column_name, y=y_column_name, color=TARGET))
+ geom_point()
+ facet_wrap(TARGET))
#@title Scatter-plot for each target variable with linear regression
X_column_name = 'alcohol'#@param {type:"raw"}
y_column_name = 'od280/od315_of_diluted_wines'#@param {type:"raw"}
from plotnine import *
(ggplot(df, aes(x=X_column_name, y=y_column_name, color = TARGET))
+ geom_point()
+ stat_smooth(method='lm')
+ facet_wrap(TARGET))
class_separator_plot
#@title class_separator_plot
X_column_name = 'alcohol'#@param {type:"raw"}
y_column_name = 'od280/od315_of_diluted_wines'#@param {type: "raw"}
import seaborn as sns
from sklearn.svm import SVC
from seaborn_analyzer import classplot
clf = SVC()
classplot.class_separator_plot(clf, [X_column_name, y_column_name], TARGET, df)
facet機能を用いた散布図
#@title scatter plot with facet
X_column_name = 'age'#@param {type:"raw"}
y_column_name = 'fare'#@param {type: "raw"}
facet = 'sex~class'#@param {type: "raw"}
from plotnine import *
(
ggplot(df)
+ facet_grid(facets = facet) #facetは 'sex~class'のように記述
+ aes(x= X_column_name, y= y_column_name, color=TARGET)
+ labs(
x= X_column_name,
y= y_column_name,
title="Plot Subsets of Data Into Panels in the Same Plot",
)
+ geom_point()
)
最後に
plotnine は美しく可読性が高い可視化が簡単コードで実現できます。
私は、seaborn-analyzer とのセット利用がお気に入りです。