更新
- ×:exp_name = setup(data = Boston, target = 'medv') ←誤りがありました。
○:exp_name = setup(data = data, target = 'medv') - AutoViz は、動作が不安定(起動初回は描画、2回目は描画しない時がある等)な場合は、セッション再起動するといけます。
はじめに
PythonのAutoML(自動機械学習)といえば PyCaret。
PyCaretは、機械学習の一連の処理、可視化がほぼ自動で実行できるPythonのライブラリ。
このPyCaretが、
- AutoEDAの「AutoViz」
- 機械学習モデルの各種可視化が可能な「ExplainerDashboard」
を統合したようです。
統合で実現された内容は、PyCaret のyoutubeチャンネルにアップされた動画をみるとよくわかります。
ということで、早速やってみることにしました。
実行条件など
- Google colabで実行
- ボストン住宅価格のデータセットで実行
※ 以前にAutoVizを適用した以下の記事でも「ボストン住宅価格のデータセット」を使っていますので比較できると思います。
強化されたPyCaretの可視化を試してみよう
まずはAutoEDAの「AutoViz」から実行します。
AutoViz
「AutoViz」は、わずかなコード記述でAutoEDA(自動データ探索)できるライブラリです。
動画を見るまでは、「ふーん、統合したんだ」というだけでスルーしようと思っていたのですが、公式動画を見るとAutoVizが私が以前使った時よりも単独でインタラクティブなものになっています。(※AutoVizのVer.up)
ライブラリインストール&インポート
!pip install pycaret
pip install autoviz
私の環境では、PyCaretインストール後にランタイムの再起動が求められました。
#実行
from pycaret.datasets import get_data
data = get_data('boston')
from pycaret.regression import *
exp_name = setup(data = data, target = 'medv')
eda(display_format = 'bokeh')
このコードは、ほぼPyCaret ページのExample の通りです。
実行すると、読み込んだデータのデータ型を表示してくれます。
データ型を変更する必要がなければ⏎をクリックします。
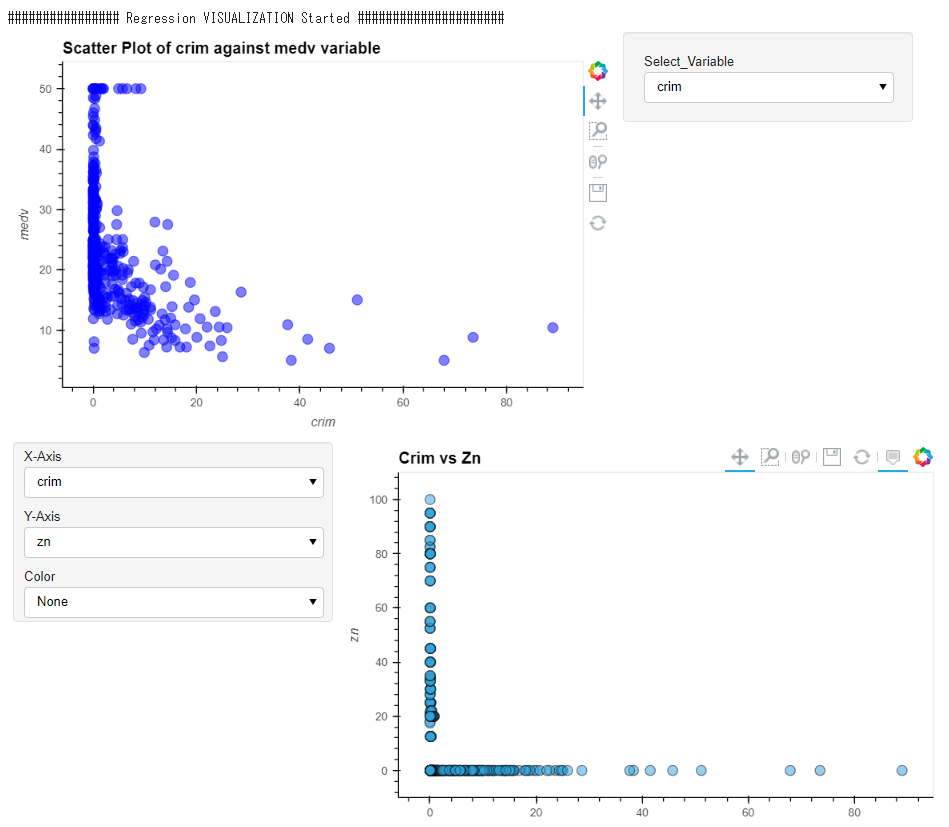
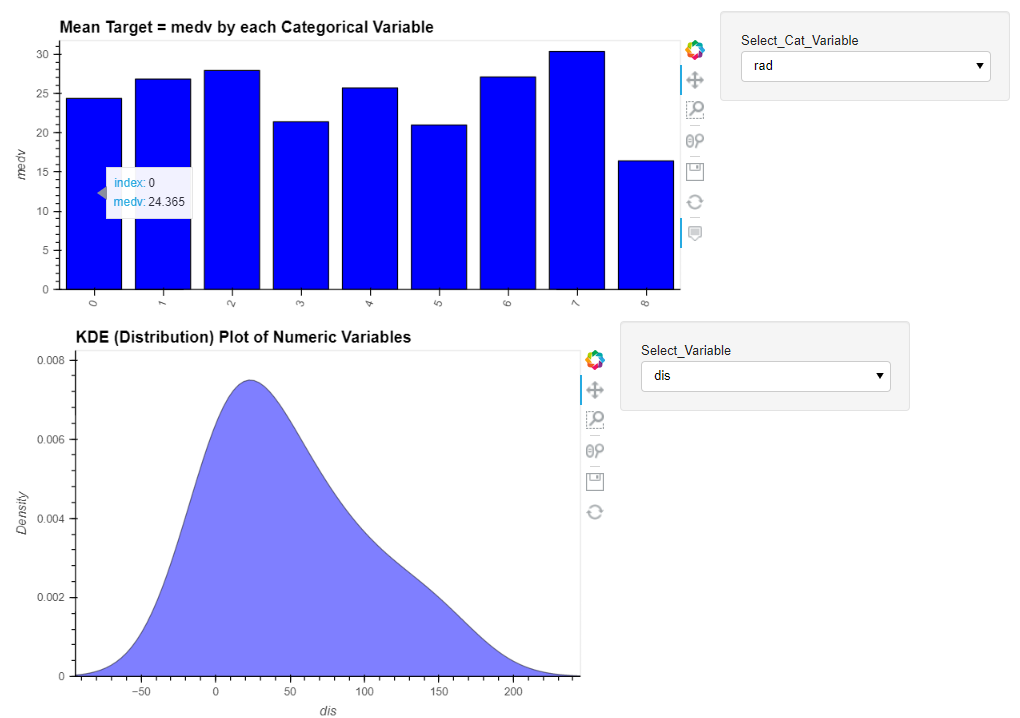
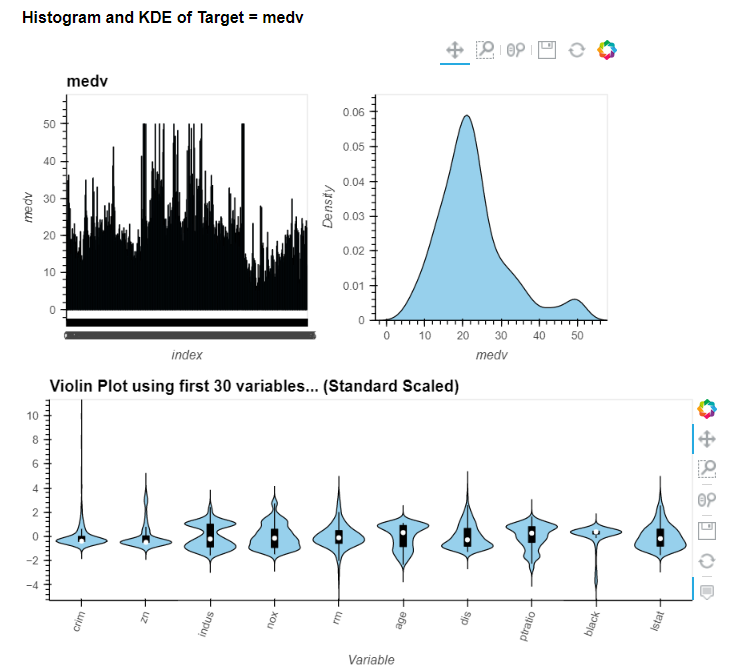
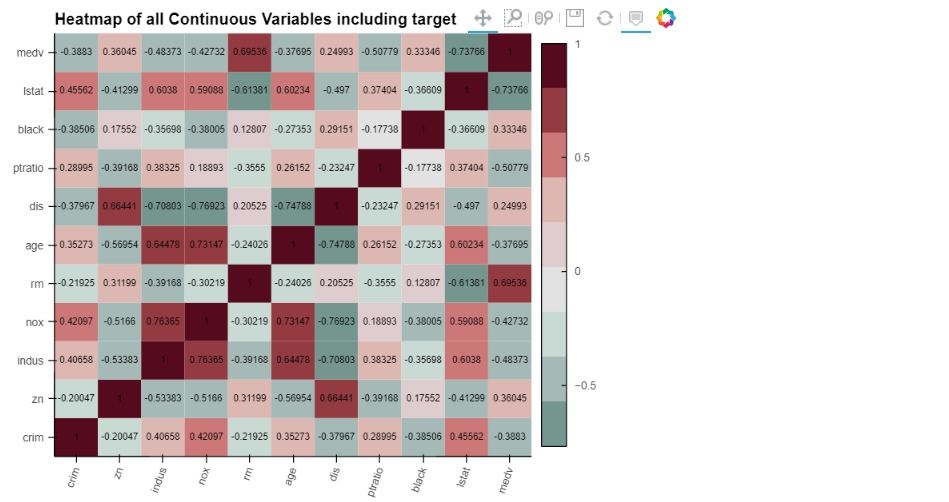
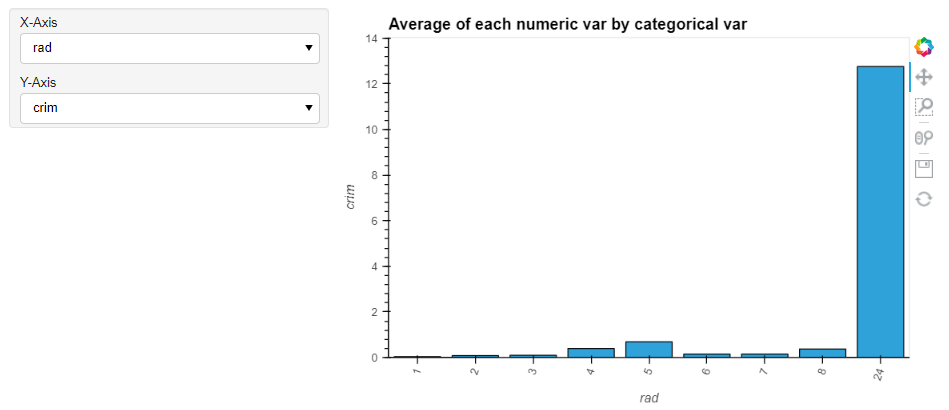
とてもインタラクティブです。これはなかなかいいですね。
また、以下のように display_format = 'html' とすると、各グラフがhtml形式で出力されます。
eda(display_format = 'html')
↓ このように出力されます。
次に「ExplainerDashboard」を実行してみます。
ExplainerDashboard
ExplainerDashboard は、xgboost, catboost, lightgbm などの機械学習モデルを分析するための対話型ダッシュボードを高速に構築するライブラリです。
ライブラリインストール&インポート
!pip install explainerdashboard
このダッシュボードは、機械学習モデルを分析するための対話型ダッシュボードなので、まずPyCaretでモデルを比較し、比較結果がもっともよかったモデルを構築したいと思います。
#モデル比較
best = compare_models()
#モデル構築
model = create_model(best)
#Dashboard生成
dashboard(model, display_format='inline')
たったこれだけのコードで、ExplainerDashboardが起動しました。
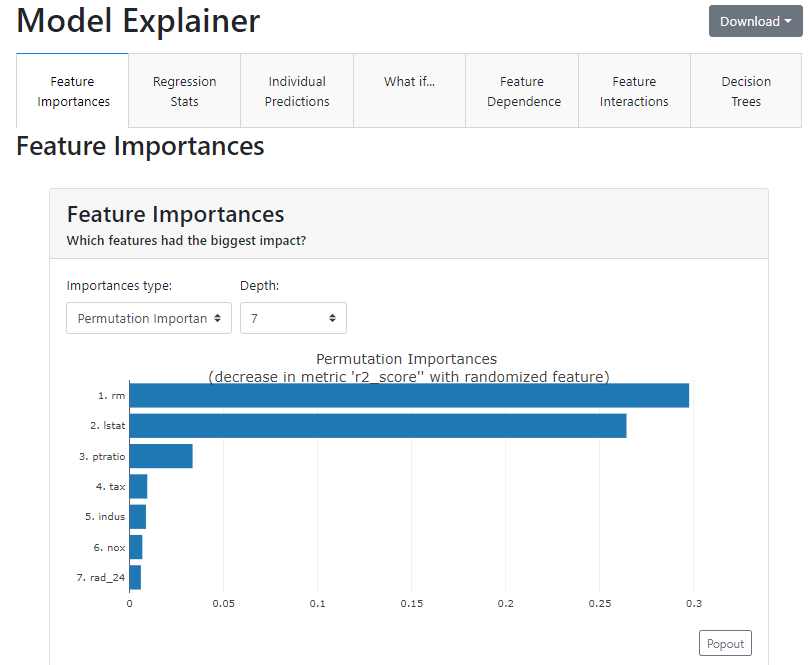
以下は、Feature Importancesの表示のキャプチャです。
[Importances Type:][Depth:]のドロップダウンを切替えると表示が変わります。
Importances Typeは、Permutation Importances が選択できます。これはいい!
また、右上の[Download]ボタンを押すと、タブ単位でhtml形式で保存することができます。
さらに、Decision Treeは dtreeviz で描かれます!
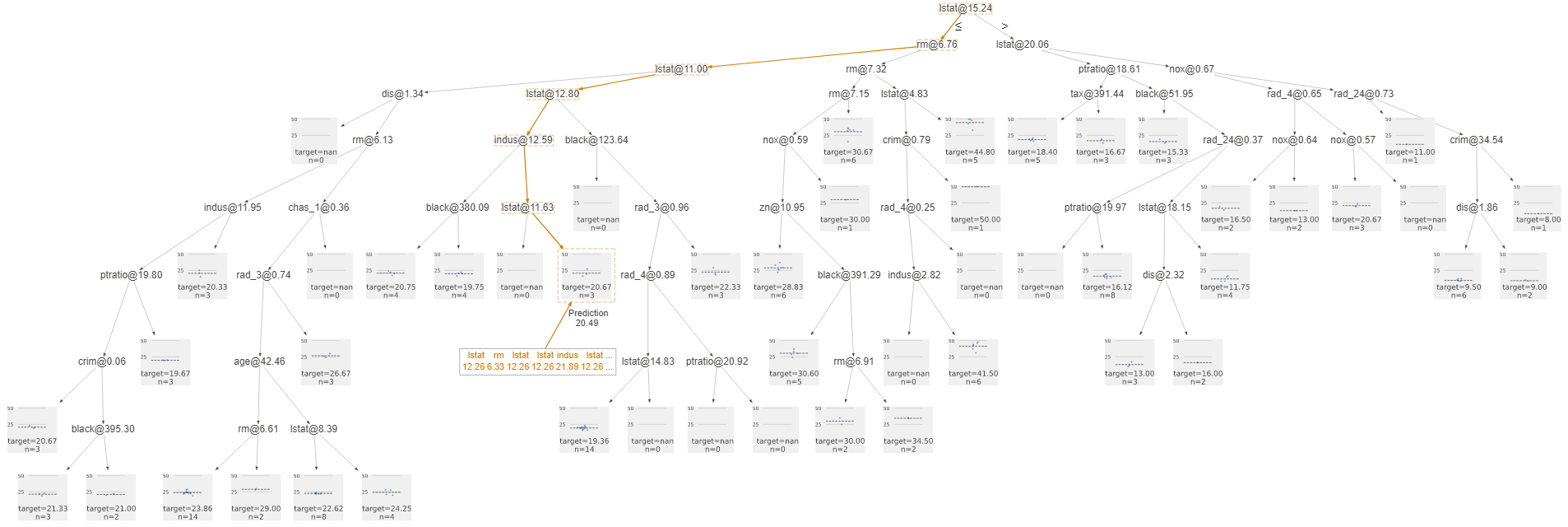
以下のように display_format ='external' とすると 実行後にセルに示されるURLをクリックするとDashboardはURL表示されます。
dashboard(tuned_model, display_format='external')
最後に
PyCaretは、まだまだ進歩し続けているんだなということを実感しました。私はPyCaretがブレンド、スタッキング、時系列データに対応していることも数日前まで知りませんでした。今回 記事に取り上げた可視化の強化を知ったのも偶然・・・たまにはアップデートをチェックしたいと思います。
参考サイト