~ ↑↑ 前回記事 ↑↑ :「”すぐ” このデータまとめて欲しい」に ”すぐ”に超簡単に応えられる Python の・・・(その7) の続きです。
はじめに
前回記事は、Borutaで特徴量を選択した後、SHAP とdtreevizで特徴量と目的変数の関係を可視化し、解釈を容易にしようという内容でした。
先日、以下の書籍に巡り合いました。
機械学習はブラックボックス → 解釈可能に変わってきていると。PFI(Permutation Feature Importance), PD(Partial Dependence), ICE(Individual Conditional Expectation), そしてSHAP(SHapley Additive exPlanations) がこの代表格として取り上げられていました。
機械学習やPython関連書籍は「ネット情報で十分だったな」と感じることも多いのですが、この書籍は「これでないとわからなかった・知らなかった」ことが(私は)数多くあり、直近でSHAPのよさを感じていたことも相まって、思わず拝みました。
書籍では、SHAP, ICE を以下のように紹介されていました。
- 機械学習モデルが 「なぜその予測値を出したのか」 を各特徴量の貢献度に分解して解釈できるのがSHAP。
- 各特徴量がモデルの予測値にどのように影響を与えているのかを確認できるのが ICE。
SHAPは「なぜモデルがこの予測値を出したのか」、ICEは「特徴量が変化した際に予測値がどう反応するのか」・・・との内容から、ICEもやってみたい! と感化され、前回記事の内容から一歩前進させることにしました。
- 前回記事からBorutaは抜きました。特徴量を絞る前に特徴量と目的変数の関係を見たいことがありますので、今回はSHAP, ICEに絞ったということです。
- 先の通り、ICEを追加しました。
- SHAP, ICEともに機械学習モデルありきなので、いずれもモデル精度を意識した上でお付き合いしないといけないなと(遅ればせながら)認識し、モデル精度の確認を追加しました。
- 前回はマルチクラスデータを切り捨てましたが、今回は「回帰•二値分類データ用」と「マルチ分類データ用」それぞれで作成しました。ただ、ICEはマルチクラスに対応していないっぽいので「回帰•二値分類データ用」のみに実装しています。
実行条件など
- Google colabで実行(※前回同様、いくつかのデータセットをLoadできるようにしています。)
- [回帰•二値分類データ]
Open with Colab - [マルチクラス分類データ]
Open with Colab
ipynbファイル(ヘッド部分)のイメージ

bostonデータセットで描いたICE plot
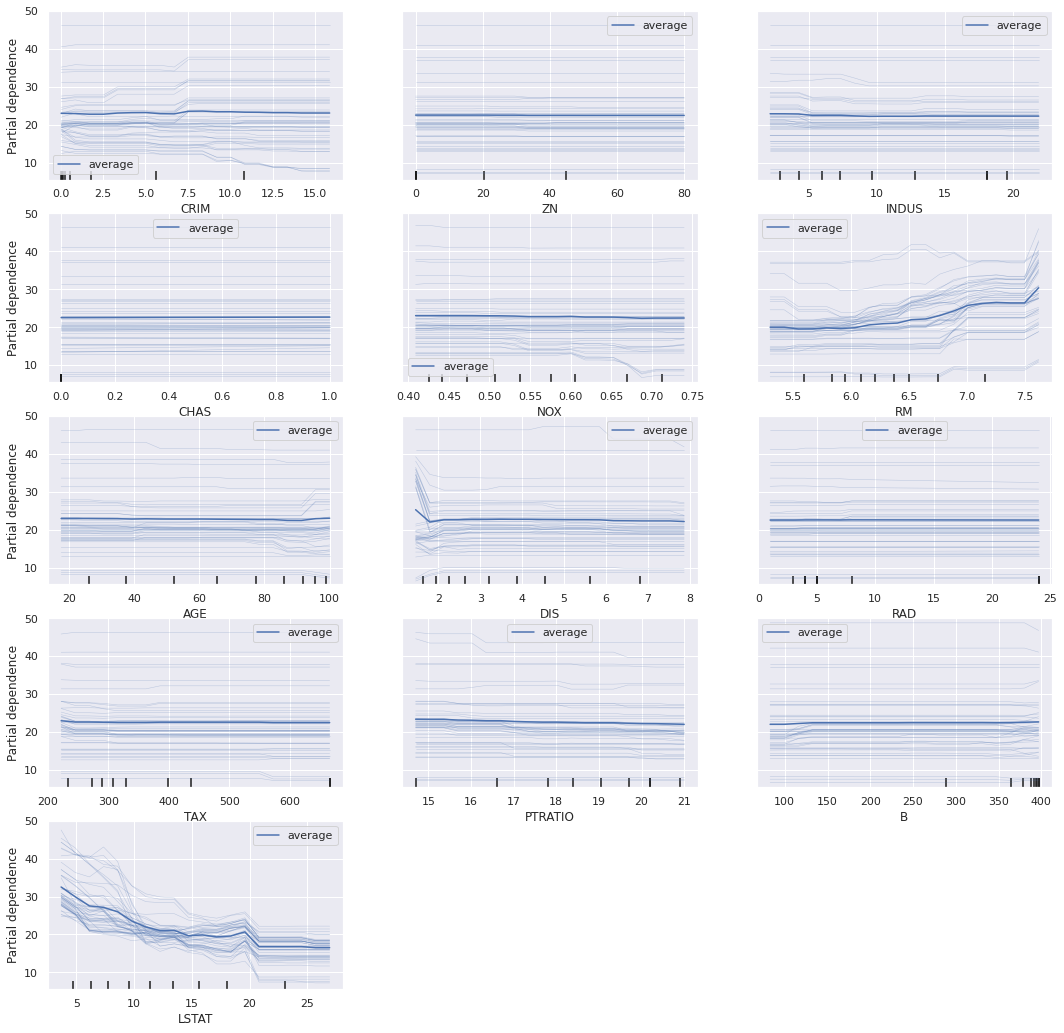
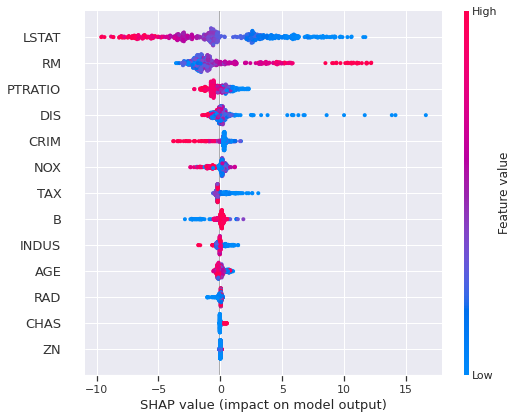
以下、SHAPの summary plot をみると、LSTATとRMの重要度が大きいことがわかります。ICEでみると「あぁ、このような傾向なのか」が掴めます。LSTATは右肩下がり、RMは右肩上がり。これはsummary plotの色でもわかりますが、ICEをみるとより傾向が掴めます。
最後に
SHAPは「なぜモデルがこの予測値を出したのか」、ICEは「特徴量が変化した際に予測値がどう反応するのか」が可視化できますので、解釈する上でとてもいいです。
線形回帰モデルの場合、「特徴量と予測値の関係は解釈できるが、高い予測精度は期待できないことが多い」に対し、決定木のアンサンブルモデルは「高い予測精度が期待できるが、ブラックボックスモデルなので解釈はむつかしい」という関係にある、ということが通例でしたが、SHAP・ICEはこの通例を覆してくれています。
また、データを読込ませた後、数分で可視化されたこれだけの結果(SHAP・ICE・dtreeviz)を見ることができるというのは、一昔前は考えてもいませんでしたので、各ライブラリ も Python も 書籍「機械学習を解釈する技術」も すべてがすばらしいです。
これらを利用させていただくことができることは本当にありがたいことです。
参考