
はじめに
TPOTは、遺伝的プログラミングにより機械学習パイプラインを最適化するPython自動機械学習ツールらしい。
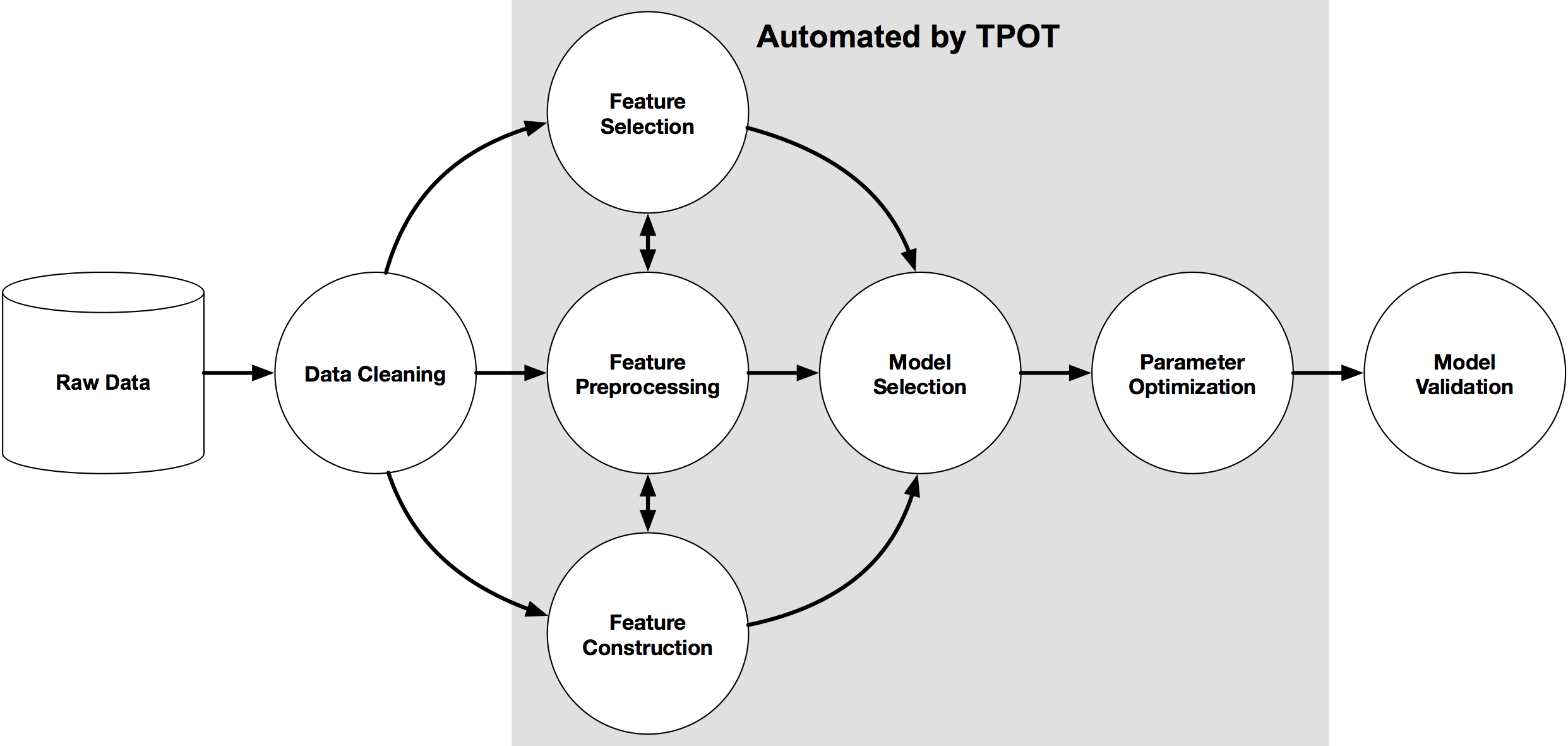
公式にアップされた上記を見ると、データクリーニングは必要だけど、それ以降の機械学習プロセスはほぼこなしてくれる感じです。数多くのパイプラインの中から最適なパイプラインを見つけることができる ようです。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行
1.読み込むデータセットとデータセットのタイプを設定します。

2.データを読み込みます。
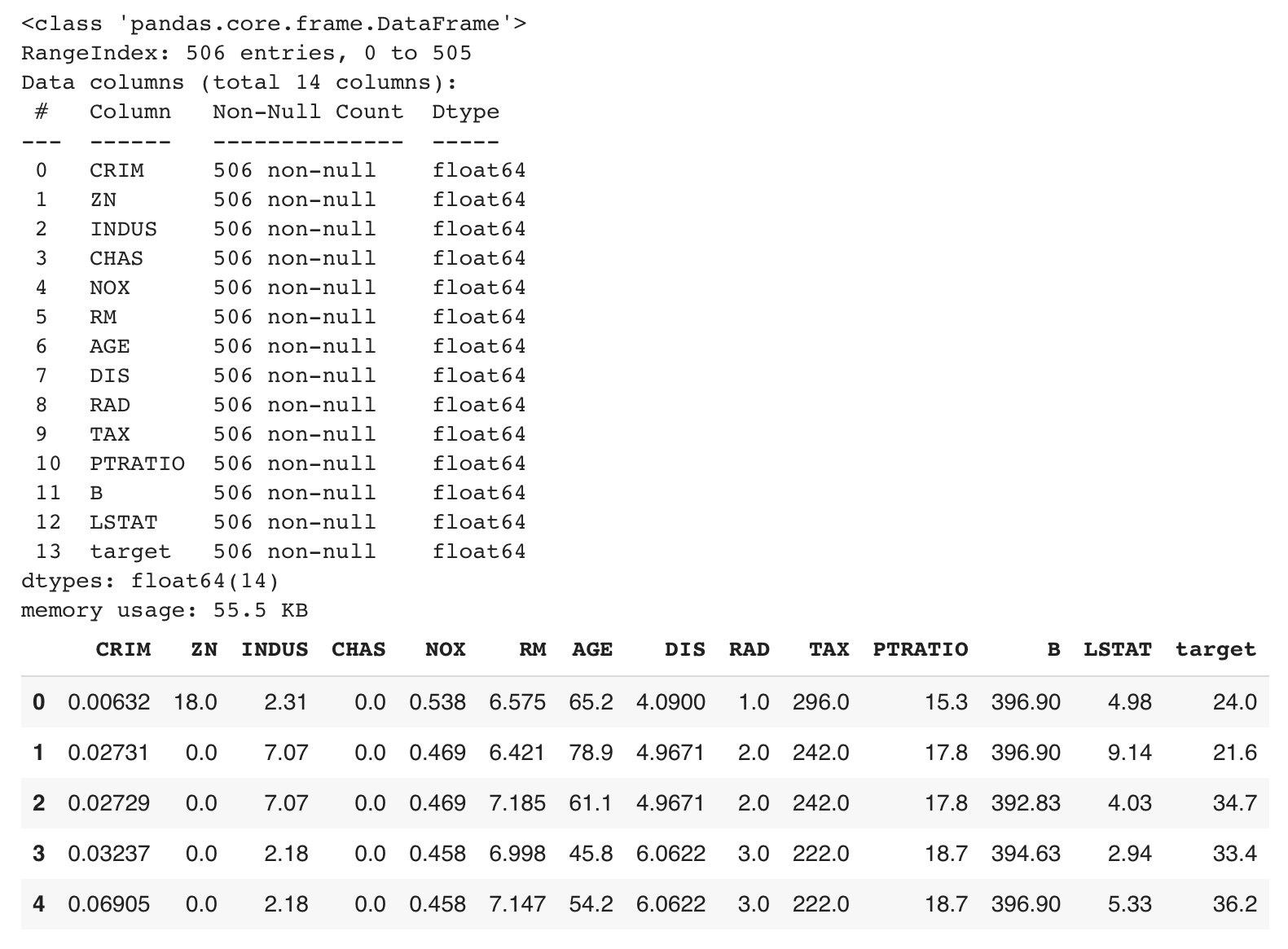
以下は、BostonHousingデータセット(回帰)を読み込んだ際の表示です。
3.データクリーニングを実行します。
※ 1.不要なデータ項目の削除、2.欠損データを含む行を削除、3.カテゴリーデータ項目を Labelエンコード、4.すべての Obeject_col を Label encord(☑ =実行)、5.データ項目名を英訳 を実装しています。
BostonHousingデータセットは、データ型がすべて数値(float64)で欠損値のない完全データなので、データクリーニングは不要です。
4.TPOT
generations と population_size はスライドバーで任意に変更できるようにしています。

実行すると、学習プログレスが示されます。

実行完了すると、以下のように結果表示されます。
Best pipeline: XGBRegressor(AdaBoostRegressor(input_matrix, learning_rate=0.01, loss=square, n_estimators=100), learning_rate=0.1, max_depth=8, min_child_weight=7, n_estimators=100, n_jobs=1, objective=reg:squarederror, subsample=0.6500000000000001, verbosity=0)
Pipeline(steps=[('stackingestimator',
StackingEstimator(estimator=AdaBoostRegressor(learning_rate=0.01,
loss='square',
n_estimators=100))),
('xgbregressor',
XGBRegressor(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1,
colsample_bytree=1, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None,
feature_types=None, gamma=0, gpu_id=-1,
grow_policy='depthwise', importance_type=None,
interaction_constraints='', learning_rate=0.1,
max_bin=256, max_cat_threshold=64,
max_cat_to_onehot=4, max_delta_step=0,
max_depth=8, max_leaves=0, min_child_weight=7,
missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=1, num_parallel_tree=1,
predictor='auto', random_state=0, ...))])
5.モデル評価
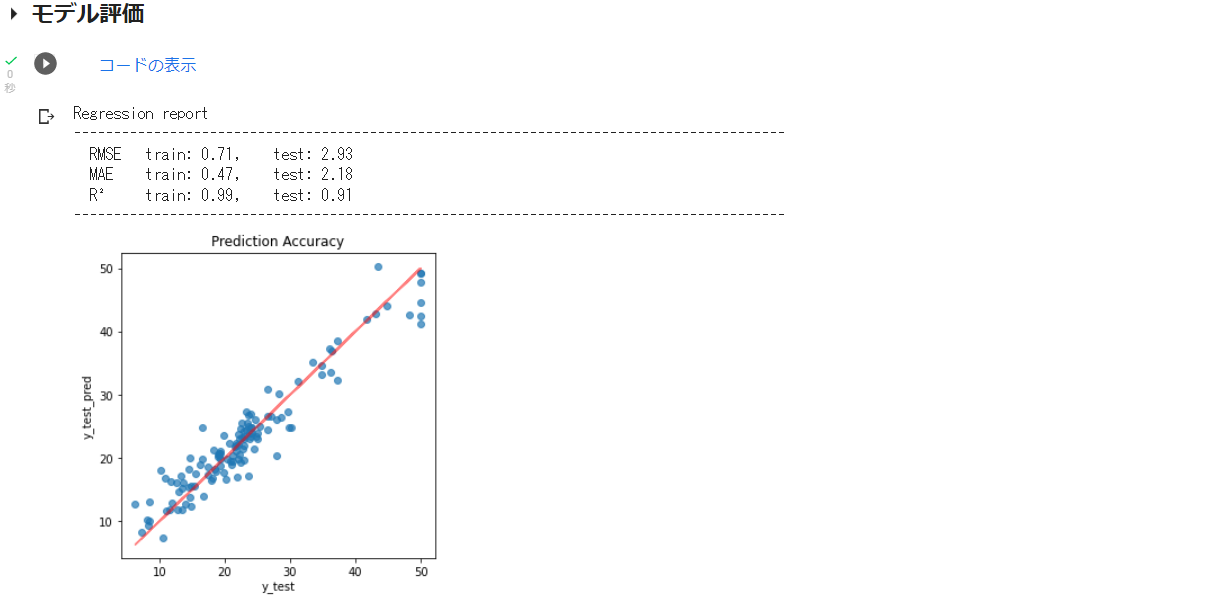
BostonHousingデータセットでの実行結果は以下の通り。
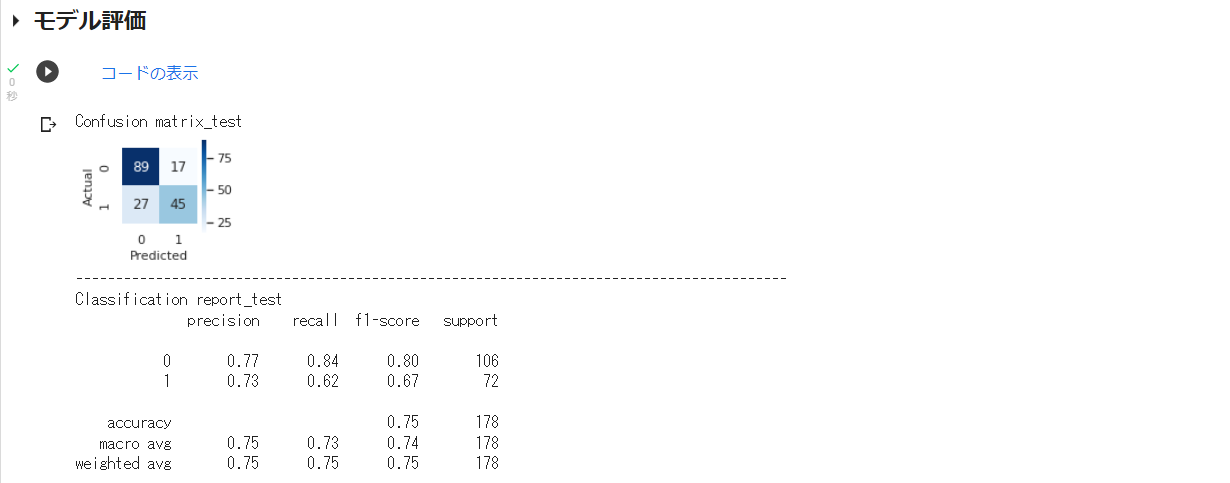
分類データで実行した場合は、以下のように混同行列とClassificationReportを表示します。
最後に
う~ん、めっちゃ楽 ^^ 。
データを与えるだけで、学習し、チューニングし、最適化してくれます。
TPOTが探索するパイプラインの総数は、
- pupulation_size + generations × offspring_size
となるらしい。pupulation_size=10, generations=10 ならば、10 + 10 × 10 =110通りとなります。
※offspring_size=None(デフォルト)←population_sizeと同じ値となるようです。
パイプラインは多いほど精度アップが期待できます。学習時間とのバランスで任意調整して、よりよい最適化を目指しましょう。
実行コード
ライブラリのインストール
#@title **Install Library**
!pip install tpot
!pip install googletrans==4.0.0-rc1 --quiet
データセット読込み
データセットとデータセットタイプ(分類か回帰)選択のフォームセット
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset_type = 'Regression' #@param ["Classification", "Regression"]
dataset = 'Boston_housing :regression' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Titanic(seaborn) :binary', 'Iris :classification', 'Loan_prediction :binary','wine :classification', 'Occupancy_detection :binary', 'Upload']
データセット読み込み→データセットのインフォと先頭5行表示
#@title Load dataset
#ライブラリインポート
import numpy as np
import pandas as pd #データを効率的に扱うライブラリ
import seaborn as sns #視覚化ライブラリ
import warnings #警告を表示させないライブラリ
warnings.simplefilter('ignore')
'''
dataset(ドロップダウンメニュー)で選択したデータセットを読込み、データフレーム(df)に格納。
目的変数は、データフレームの最終列とし、FEATURES、TARGET、X、yを指定した後、データフレーム
に関する情報と先頭5列を表示。
任意のcsvデータを読込む場合は、datasetで'Upload'を選択。
'''
#任意のcsvデータ読込み及びデータフレーム格納、
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
#Diabetes データセットの読込み及びデータフレーム格納、
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns = diabetes.feature_names)
df['target'] = diabetes.target
#Breast_cancer データセットの読込み及びデータフレーム格納、
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names)
#df['target'] = breast_cancer.target #目的変数をカテゴリー数値とする時
df['target'] = breast_cancer.target_names[breast_cancer.target]
#Titanic データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
#目的変数 Survived をデータフレーム最終列に移動
X = df.drop(['Survived'], axis=1)
y = df['Survived']
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#Titanic(seaborn) データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
#重複データをカットし、目的変数 alive をデータフレーム最終列に移動
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1)
y = df['alive'] #目的変数データ
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#iris データセットの読込み及びデータフレーム格納、
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
#df['target'] = iris.target #目的変数をカテゴリー数値とする時
df['target'] = iris.target_names[iris.target]
#wine データセットの読込み及びデータフレーム格納、
elif dataset == "wine :classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
#df['target'] = wine.target #目的変数をカテゴリー数値とする時
df['target'] = wine.target_names[wine.target]
#Loan_prediction データセットの読込み及びデータフレーム格納、
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
#Occupancy_detection データセットの読込み及びデータフレーム格納、
elif dataset =='Occupancy_detection :binary':
data_url = 'https://raw.githubusercontent.com/hima2b4/Auto_Profiling/main/Occupancy-detection-datatest.csv'
df = pd.read_csv(data_url)
df['date'] = pd.to_datetime(df['date']) #[date]のデータ型をdatetime型に変更
#Boston データセットの読込み及びデータフレーム格納
else:
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
df['target'] = boston.target
#データフレーム表示
df.info(verbose=True) #データフレーム情報表示(verbose=Trueで表示数制限カット)
df.head() #データフレーム先頭5行表示
データクリーニング
不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@title 不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@markdown **<font color= "Crimson">注意</font>:Drop_label_is(カラムを指定して削除)の記載は <u> ' ID ' , ' Age ' </u> などとしてください。**</font>
Drop_label_is = 'sibsp', 'parch'#@param {type:"raw"}
try:
if Drop_label_is is not "":
Drop_label_is = pd.Series(Drop_label_is)
print('-----------------------------------------------------------------------------------------')
print("Drop of specified column:", Drop_label_is.values)
df.drop(columns=list(Drop_label_is),axis=1,inplace=True)
else:
print('※削除カラムの指定なし→処理スキップ')
except:
print("※正常に処理されませんでした。入力に誤りがないか確認してください。")
#データの7割以上が欠損値のカラムを削除(☑ =実行)
Over_70percent_missing_value_is_drop = True #@param {type:"boolean"}
#各列ごとに、7割欠損がある列を削除
if Over_70percent_missing_value_is_drop == True:
for col in df.columns:
nans = df[col].isnull().sum() # nanになっている行数をカウント
# nan行数を全行数で割り、7割欠損している列をDrop
if nans / len(df) > 0.7:
# 7割欠損列を削除
print('-----------------------------------------------------------------------------------------')
print("Drop of missing 70% column:", col)
df.drop(col, axis=1, inplace=True)
print('-----------------------------------------------------------------------------------------')
df.head()
欠損データを含む行を削除(☑ =実行)
#@title 欠損データを含む行を削除(☑ =実行)
Null_Drop = True #@param {type:"boolean"}
if Null_Drop == True:
df = df.dropna(how='any')
df.head()
カテゴリーデータ項目を Labelエンコード(対象:Dtype が int64, float64 以外のデータ項目)
#@title カテゴリーデータ項目を Labelエンコード(**対象:Dtype が int64, float64 以外のデータ項目**)
#@markdown **<font color= "Crimson">注意</font>:指定は <u> ' ID ' , ' Age ' , </u> などとしてください。**
Object_label_to_encode_is = '', '', '' #@param {type:"raw"}
Object_label_to_encode_is = pd.Series(Object_label_to_encode_is)
from sklearn.preprocessing import LabelEncoder
encoders = dict()
try:
for i in Object_label_to_encode_is:
if Object_label_to_encode_is is not "":
series = df[i]
le = LabelEncoder()
df[i] = pd.Series(
le.fit_transform(series[series.notnull()]),
index=series[series.notnull()].index
)
encoders[i] = le
print('-----------------------------------------------------------------------------------------')
print('[エンコードカラム]:',i)
le_name_mapping = dict(zip(le.classes_, le.transform(le.classes_)))
print(le_name_mapping)
else:
print('skip')
except:
print("※正常に処理されなかった場合は入力に誤りがないか確認してください。")
print('-----------------------------------------------------------------------------------------')
df.head()
すべての Obeject_col を Label encord(☑ =実行)
#@title すべての Obeject_col を Label encord(☑ =実行)
Encord_all_object_label = True #@param {type:"boolean"}
from sklearn.preprocessing import LabelEncoder
if Encord_all_object_label == True:
le = LabelEncoder()
for col in df.columns:
if df[col].dtype == 'object':
df[col] = le.fit_transform(df[col].astype(str))
print('-----------------------------------------------------------------------------------------')
print(col)
print(le.classes_, "= [0, 1, 2...]" )
# else:
# print(col,':エンコードしない→処理スキップ')
print('-----------------------------------------------------------------------------------------')
df.head()
データ項目名を英訳(☑ =実行)
#@title データ項目名を英訳(☑ =実行)
Column_English_translation = False #@param {type:"boolean"}
from googletrans import Translator
if Column_English_translation == True:
eng_columns = {}
columns = df.columns
translator = Translator()
for column in columns:
eng_column = translator.translate(column).text
eng_column = eng_column.replace(' ', '_')
eng_columns[column] = eng_column
df.rename(columns=eng_columns, inplace=True)
print('-----------------------------------------------------------------------------------------')
print('[カラム名_翻訳結果(翻訳しない場合も表示)]')
print('-----------------------------------------------------------------------------------------')
df.head(0)
TPOT
TPOT実行
#@title **TPOT実行**
generations = 10 #@param {type:"slider", min:5, max:100, step:1}
population_size = 10 #@param {type:"slider", min:5, max:100, step:1}
#FEATURES、TARGET、X、yを指定
FEATURES = df.columns[:-1] #説明変数のデータ項目を指定
TARGET = df.columns[-1] #目的変数のデータ項目を指定
X = df.loc[:, FEATURES] #FEATURESのすべてのデータをXに格納
y = df.loc[:, TARGET] #TARGETのすべてのデータをyに格納
#testとtrainを分割
from sklearn.model_selection import train_test_split
if dataset_type == 'Classification':
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, stratify = y)
else:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, test_size=0.25)
#ライブラリインポート
from tpot import TPOTClassifier
from tpot import TPOTRegressor
#TPOT実行
if dataset_type == 'Classification':
tpot = TPOTClassifier(scoring='f1',
generations=generations,
population_size=population_size,
verbosity=2,
random_state=0,
n_jobs=-1)
else:
tpot = TPOTRegressor(scoring='r2',
generations=generations,
population_size=population_size,
random_state=0,
verbosity=2,
n_jobs=-1)
tpot.fit(X_train, y_train)
tpot.fitted_pipeline_
モデル評価
#@title **モデル評価**
#指標関連ライブラリインストール
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import f1_score #F1スコア
from sklearn.metrics import confusion_matrix #混同行列
from sklearn.metrics import classification_report #classification report
import matplotlib.pyplot as plt
# 予測値
y_train_pred = tpot.predict(X_train)
y_test_pred = tpot.predict(X_test)
if dataset_type == 'Classification':
print('Confusion matrix_test')
#混同行列
#cm = confusion_matrix(y_test,y_test_pred)
#cm = pd.DataFrame(data = cm)
#display(cm)
sns.set(rc = {'figure.figsize':(1.5,1.5)})
sns.heatmap(confusion_matrix(y_test,y_test_pred),
square=True, cbar=True, annot=True, cmap='Blues',fmt='g')
plt.xlabel('Predicted', fontsize=11)
plt.ylabel('Actual', fontsize=11)
plt.show()
print('-----------------------------------------------------------------------------------------')
print('Classification report_test')
print(classification_report(y_true=y_test, y_pred=y_test_pred))
else:
print('Regression report')
print('-----------------------------------------------------------------------------------------')
print(' RMSE\t train: %.2f,\t test: %.2f' % (
mean_squared_error(y_train, y_train_pred, squared=False),
mean_squared_error(y_test, y_test_pred, squared=False)))
print(' MAE\t train: %.2f,\t test: %.2f' % (
mean_absolute_error(y_train, y_train_pred),
mean_absolute_error(y_test, y_test_pred)))
print(' R²\t train: %.2f,\t test: %.2f' % (
r2_score(y_train, y_train_pred), # 学習
r2_score(y_test, y_test_pred) # テスト
))
print('-----------------------------------------------------------------------------------------')
#print('Prediction error')
#sns.set(rc = {'figure.figsize':(5,5)})
#sns.set_style('whitegrid') #style指定
#plt.xlabel('Predicted', fontsize=11)
#plt.ylabel('Actual', fontsize=11)
#sns.scatterplot(x=y_test_pred, y=y_test,alpha=0.7);
plt.figure(figsize = (5,5))
plt.title('Prediction Accuracy')
ax = plt.subplot(111)
ax.scatter(y_test, y_test_pred,alpha=0.7)
ax.set_xlabel('y_test')
ax.set_ylabel('y_test_pred')
ax.plot(y_test,y_test,color='red',alpha =0.5)
plt.show()