~手元データで探索的データ解析(EDA)しよう(Lux編)~

はじめに
「おい、悪いが”すぐに”このデータまとめてくれ」
こんなとき、データを与えるだけで簡単にデータを可視化してくれるPythonのEDAツールはとても便利です。
その中のひとつに LUX があります。
これまではGoogle Colabでの起動方法がわからず、スルーしていたのですが、以下のサイトにGoogle Colab起動方法が紹介されてましたので実行してみました。
実行すると、すべての連続変数の散布図、ヒストグラム、カテゴリー変数の度数グラフをサクッと表示してくれ、目的変数を指定すると説明変数の関係を散布図などのグラフを層別して表示してくれます。
データ分析を行うときは、まずデータ全般を眺め、目的変数と説明変数の関係を把握し、気になる2変数があれば深掘りし。。。といった流れで進めるのではないでしょうか?
LUX は、この流れをアシストしてくれるつくりになっていますので、「おい、悪いが”すぐに”このデータまとめてくれ」 というときの助けになるでしょう。
実行条件など
-Google colabで実行
-任意のデータセットとsklearnのデータセットを読み出せるようにしています。
-htmlファイルは、該当セルの ☑︎ で出力できます。
実行
ライブラリのインストール
まず LUX をインストールします。
!pip install lux
Load dataset
読込むデータセットを選択する GoogleColabのフォームを利用したメニューの設定です。
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'Boston_housing :regression' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Iris :classification', 'Loan_prediction :binary', 'Upload']
上記のコードで、セルは以下の表示となりますので、ドロップダウンメニューでデータセットを選択してください。任意のデータセットを読み込む場合は Upload を選択してください。

次にメニューで選択したデータセットに応じたデータセットの読込みが行えるようにします。
読込んだデータはデータフレーム(df)に反映し、カラム・データ数・データ型を表示させます。
#@title Load dataset
#ライブラリインポート
import lux
import pandas as pd
import numpy as np
from google.colab import output
output.enable_custom_widget_manager()
import seaborn as sns
import warnings
warnings.simplefilter('ignore')
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
dataset = load_diabetes()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
dataset = load_breast_cancer()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
X = df.drop(['Survived'], axis=1) # 目的変数を除いたデータ
y = df['Survived'] # 目的変数
df = pd.concat([X, y], axis=1)
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
dataset = load_iris()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
else:
from sklearn.datasets import load_boston
dataset = load_boston()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
source = df.copy()
FEATURES = df.columns[:-1]
TARGET = df.columns[-1]
X = df.loc[:, FEATURES]
y = df.loc[:, TARGET]
df.info(verbose=True)
以下はボストンデータセットを読み込み後にセルに表示された画像のキャプチャです。

Datasetの数字・文字列区分
データセットのカラムの内、数字のカラムはこれ、文字列のカラムはこれと表示させます。
先に実行した df.info() でも分かるのですが、あとでカラム指定など行う場合にコピペできるので、私はよく表示させています。
#@title Datasetの数字・文字列区分
numerical_col = []
Object_col = []
for col_name, item in df.iteritems():
if item.dtype == object:
Object_col.append(col_name)
else:
numerical_col.append(col_name)
print('-----------------------------------------------------------------------------------------')
print('Numerical_columns:', numerical_col)
print('-----------------------------------------------------------------------------------------')
print('Object_columns:', Object_col)
print('-----------------------------------------------------------------------------------------')
以下は、ボストンデータセットでの結果です。
Numerical_columns: ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'target']
Object_columns: []
Dataset describe
データセットの基本統計量も出力しておきたいと思います。
#@title Dataset describe
display(df.describe())
以下はボストンデータセットを読み込み後にセルに表示された画像のキャプチャです。

Lux
Luxの可視化は、df⏎だけ! すごい簡単です。
#@title Visualization
#@markdown **※ [ Toggle Pandas/Lux ] ボタンをクリックしてください。**
df
実行すると以下の表示となります。左上の[ Toggle Pandas/Lux ] ボタンをクリックするとグラフ表示に変わります。
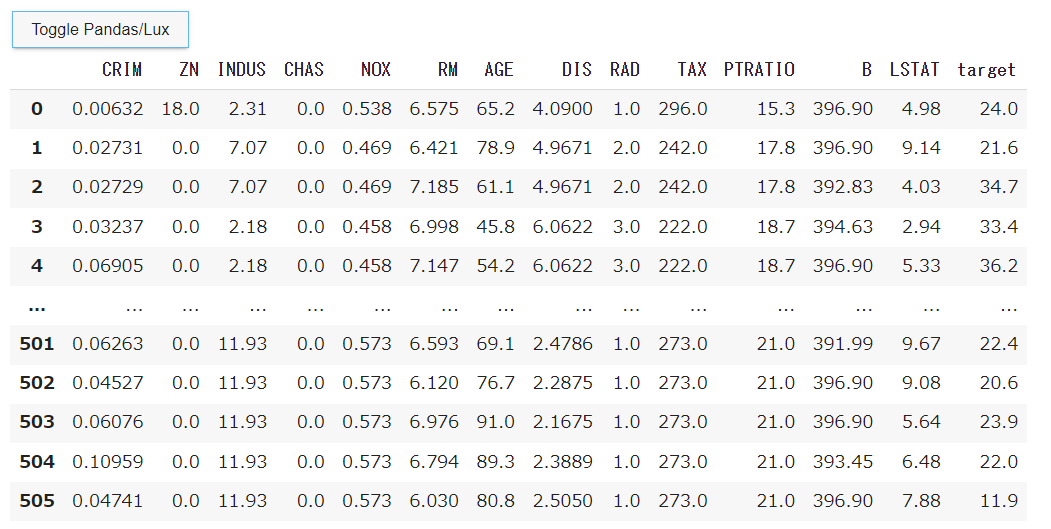
グラフ表示には3つのタブがあり、タブ毎の表示は以下となります。



htmlデータ保存
以下で、先のグラフをhtmlデータとして保存することができます。
以下のコードでは、ローカルファイルにも保存できるようにしています。
#@markdown **※html_Reportを保存する時は ☑**
html_output = False #@param {type:"boolean"}
if html_output == True:
df.save_as_html('Lux_Report.html')
from google.colab import files
files.download( "/content/Lux_Report.html" )
Lux(目的変数指定)
Luxは変数を指定することができます。
以下は、目的変数を指定したコードです。
#@title Lux(目的変数指定)
#@markdown **※ [ Toggle Pandas/Lux ] ボタンをクリックしてください。**
#変数=targetを指定する場合
df.intent = ['target']
df
Lux(2変数指定)
以下は、2変数を指定し、実行するコードです。
#2変数を指定する場合
cloumn1_name = 'target' #@param {type:"raw"}
cloumn2_name = 'RM' #@param {type:"raw"}
df.intent = [cloumn1_name, cloumn2_name]
df
以下は、ボストンデータセットを上記のコードで実行した結果です。

最後に
動作も軽く、インタラクティブでとてもいいです。
全体を眺め、変数を指定し、さらに変数を指定し・・・といった具合にデータ探索をアシストしてくれます。
ただ、LUX で探索する前にすこしデータ全体を眺めたいなということはあるんじゃないかなと思います。
LUX を実行するとデータスタイルが Lux style?!といったスタイルに変わるようなので、他のライブラリと併用するとうまくいかないケースがありますが、sweetviz は併用できました。
「おい、悪いが”すぐに”このデータまとめてくれ」 ってときの一助になることを祈ります。
関連記事
参考サイト