~手元データの要約、視覚化を超簡単に実現して、探索的データ解析(EDA)しよう(Pandas-Profiling編)~

2020/09/14:Google Colabで開くブックマークレット追加
はじめに
「おい、悪いが”すぐに”このデータまとめてくれ」
緊急!となれば、そりゃ”すぐに”取りかかるが、”すぐに”まとめることができるかは別の話・・・これはデータ項目が多いときほど悩ましいものです。
じつは、Pythonには、このようなデータセットでも”すぐに”まとめることができる pandas-profiling ってのがある。
「Pythonで相関係数行列グラフとか描けるのは知ってるけど、チマチマやってる時間ないんです」
といった方にとっても、まとめを頼んだ上司にとっても、まちがいなく喜んでくれるはず。
この記事は、私の備忘含め、pandas-profiling が誰でも簡単に実行できるように記録するものです。
実行条件など
・Google colabで実行
・ボストン住宅価格のデータセットで実行
※手元データを読込んで実行する場合も記載していますので、簡単にできるはずです。
ボストン住宅価格のデータセットについて
以下サイト(Kaggle)の「Boston.csv」を使わせていただいた。
データ数:506, 項目数:14のデータセットで、住宅価格を示す「MEDV」という項目と、住宅価格に関連するであろう項目が「CRIM:犯罪率」「RM:部屋数」「B:町の黒人割合」「RAD:高速のアクセス性」・・・等、13項目で構成されたデータとなっています。
これだけ項目があると、データ傾向を掴むだけでも、なかなか骨が折れるだろうと想像できますね。
ボストン住宅価格データの項目と内容
|項目|内容|
|:-----------|:------------------|
|CRIM|町ごとの一人当たり犯罪率|
|ZN|25,000平方フィート以上の住宅地の割合|
|INDUS|町ごとの非小売業の面積の割合|
|CHAS|チャールズ川のダミー変数(川に接している場合は1、そうでない場合は0)|
|NOX|窒素酸化物濃度(1,000万分の1)|
|RM|1住戸あたりの平均部屋数|
|AGE|1940年以前に建てられた持ち家の割合|
|DIS|ボストンの5つの雇用中心地までの距離の加重平均|
|RAD|高速道路(放射状)へのアクセス性を示す指標|
|TAX|10,000ドルあたりの固定資産税の税率|
|PTRATIO|町ごとの生徒数と教師数の比率|
|B|町ごとの黒人の割合|
|LSTAT|人口の下層階級の比率|
|MEDV|住宅価格の中央値(1000㌦単位)|
プロファイリング(pandas-profiling)してみよう!
ライブラリのインストールおよびインポート
!pip install git+https://github.com/pandas-profiling/pandas-profiling.git
!pip show pandas_profiling
import pandas as pd
import warnings
from pandas_profiling import ProfileReport
from pandas_profiling.utils.cache import cache_file
warnings.filterwarnings('ignore')
データの読み込み
※手元データを読込む場合は、読み込むファイル名を変更してください。
※Excelファイルを読込む場合は、pd.read_excel('ファイル名.xlsx')となります。
df = pd.read_csv("Boston.csv",index_col=0)
profile = ProfileReport(df)
プロファイルを出力
profile
profile.to_file("Profile‗result.html")
出力イメージ
プロファイルから読み取った概要に、HTML出力結果にをアタッチして報告すれば、きっと喜んでいただけるでしょう。
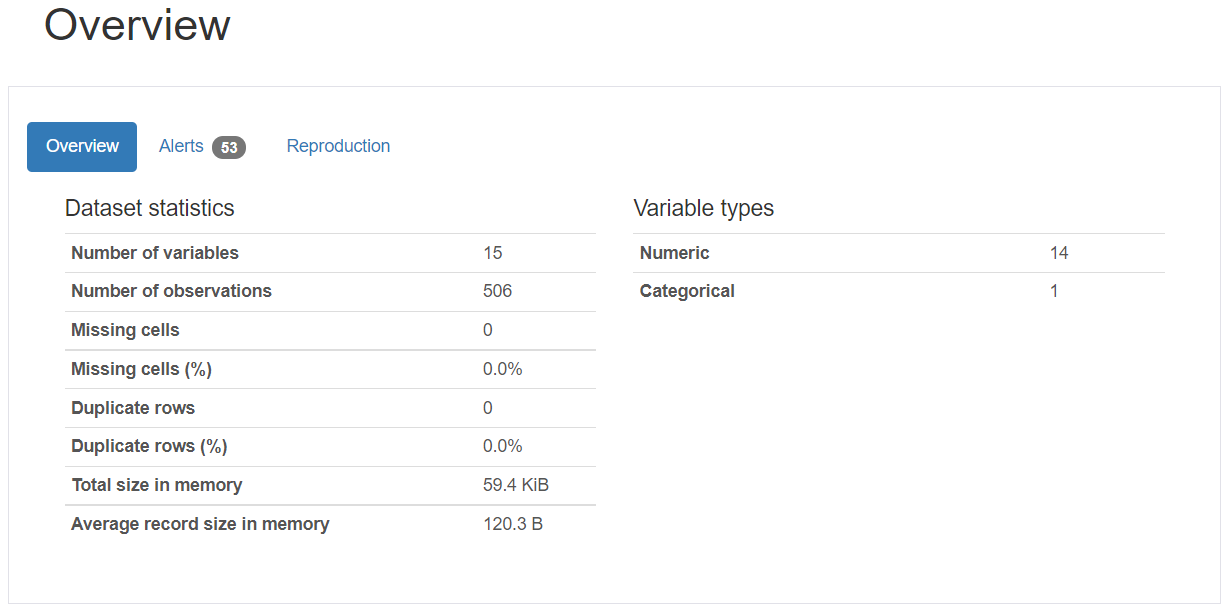

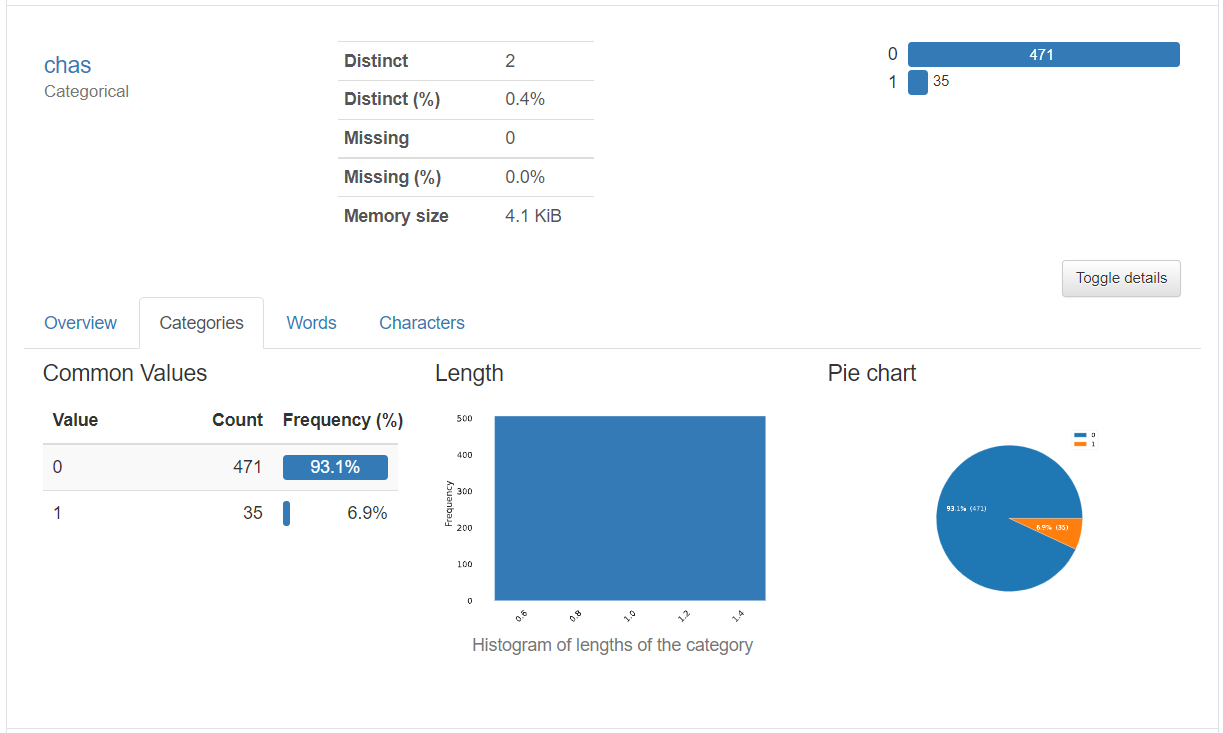
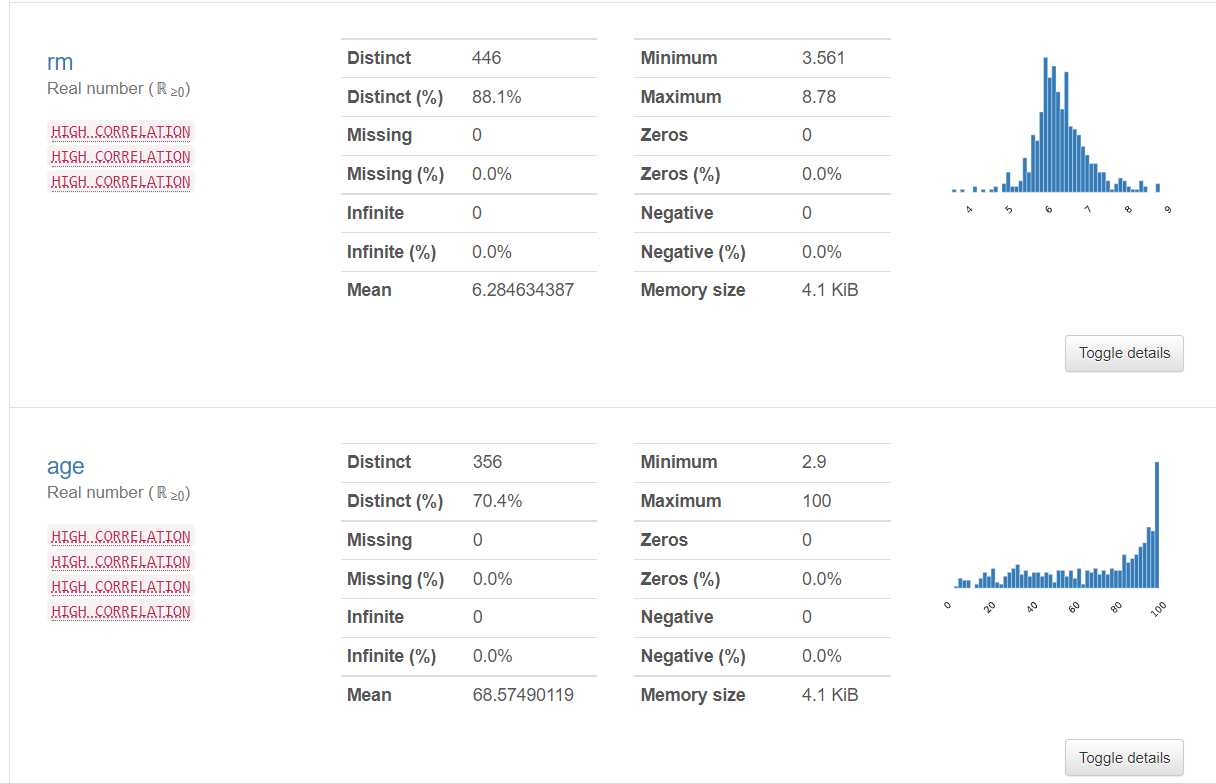
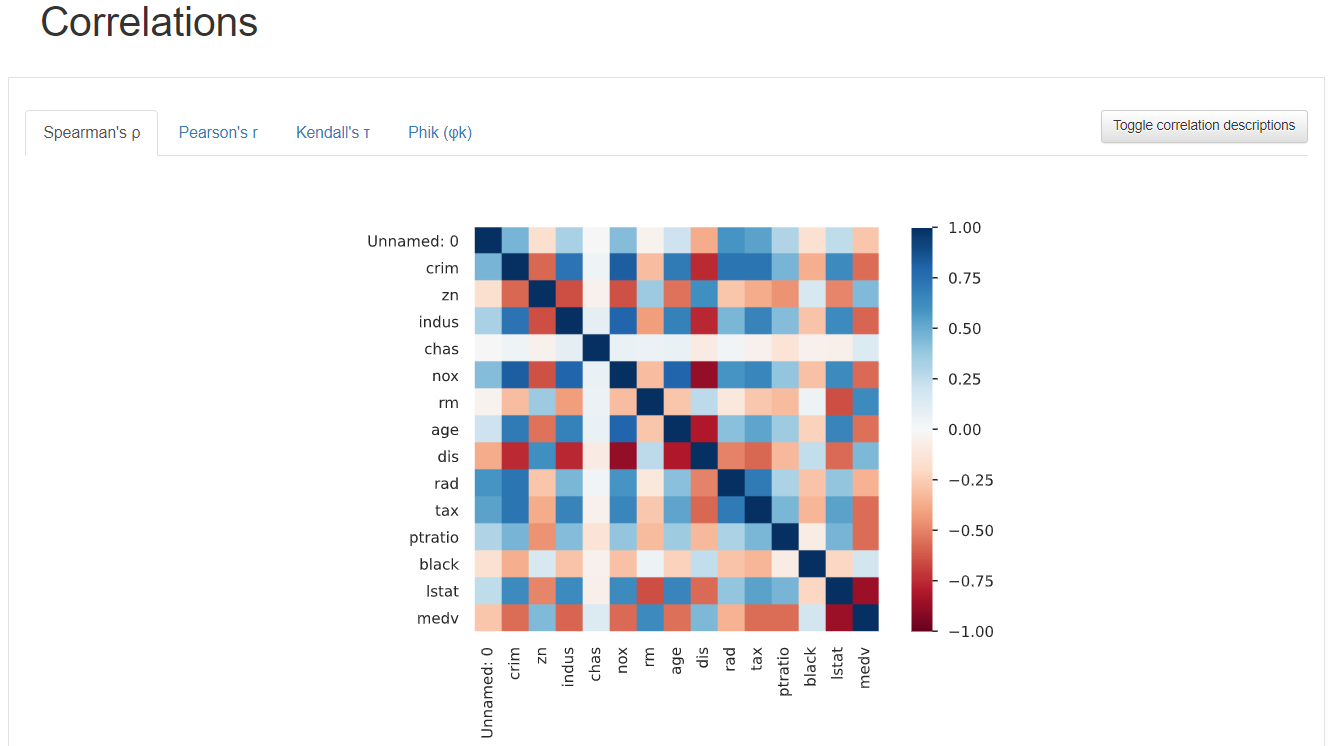
最後に
Pythonには「こんなことまでできるのか」と驚かされることがいろいろある。
このpandas-profiling もそのひとつ。使わない手はない。
↓これすごいです。WebブラウザでPandas-profileingが実行できます。
参考サイト
※GitHubにローカルファイル読み出しができるよう改良したコードをアップしています。