※2021/9/07:ヒストグラム引数の補足追加。
※2021/8/31:Pythonを操作したことがない方でも手持ちデータでグラフが描けることができるよう、すこし内容を修正・補足しました。

はじめに
最近、PythonやRで、データ分析したり、グラフを描いたりしている方が増えてきたように思いますが、とはいえ「基本Excelで!」という方々には遠く及びません。
これは、Excelをデータ入力枠そのものとして活用していることと、Excelである程度の分析もできちゃうということがあると思います。私も普段はExcelだけでこと足りています。
そんな私ですが、これまでに何度かPythonで作成されたグラフで「こんなグラフが描けるのかぁ」、「なんと美しい」と心奪われる機会がありました。
動機は不純ですが、単純に**「Pythonでグラフ描きたい!」**、ただそれだけで始めました。
これは「さくら准教授」さんのツイートです。
うん、たしかに。まず知ることだな。これが大事だ。
Pythonとどう向き合う?
先の取り、現在、私はもっぱらの「エクセラー」なので、Pythonでプログラムを駆使し、多種多様なグラフが描けるようになるというのは、自信でも想像がむつかしい。
Excelでできることは、従来通りこれで困らないので、Pythonならではの・・・等、まずどう向き合うかを設定しました。
・Google colabだけを使います
・データ加工や欠損値処理など、データクレンジングは基本Excelでいいやと割り切ります
・データはExcel(かCSV)を読込み、グラフ作成という流れを基本にします
・巷に公開されているソースを活用し、プログラムをゴリゴリに理解していなくても**「みようみまね」でできるように**を目指します
Google colaboratoryの準備
Google colaboratoryから準備しないといけない場合は、以下を確認。
Googleのアカウントを持ってさえいれば誰でも使用することができ、開発環境を整える必要もなくPythonによる機械学習実装が可能です。
Google colaboratory起動
「Google Drive」を起動すると、画面左上の[+新規]ボタンをクリックすると以下のように複数のプログラム起動メニューが表示されます。このメニューのGoogle colaboratoryをクリックすればOKです。
ライブラリのインストールとインポート
どんなグラフを描く時も、まずは以下のコードをGoogle colaboratoryで実行します。
どのような場合にどのライブラリが必要かはわかっていた方がいいが、「毎回、これだけやっておけば事足りる」ということを機械的に実行するのが、確実です。(乱暴で申し訳ないが、私はいつもとにかく以下を実行しています。)
pip install japanize-matplotlib
# Import required libraries
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
from scipy.stats import norm
上記のコードをコピーし、Google colaboratoryの画面にある、左側に ▶︎ がある入力枠にコードをペーストし、▶︎ クリックか、SHIFT+ENTER するか のいずれかで実行されます。
[+ コード]をクリックすると、 ▶︎ がある入力枠をいくつも追加することができます。
うまく実行されると[OK]表示がでます。うまく実行されないと[Error]がでます。
ここで紹介することは、基本コピペ+極々限られた入力となりますので、ケアレスなミスがない限り[OK]となるはずです。
グラフ化したいデータの読込み
次に、データの読み込みです。
Google colaboratoryの画面左端にある📂アイコンをクリックすると、ファイル階層表示が画面左にあらわれます。
ファイルは、[↑]付きのファイルアイコンをクリックによりアップロードできます。
※ファイルがアップロードすると、画面左のファイル階層に表示されます。(少しタイムラグが生じるように思いますので、少し待ちましょう。)
Pythonでグラフを描くには、読み込んだファイルをデータフレームに格納しなければなりません。
先ほどと同じように、以下のコードをコピーし、▶︎ がある入力枠にペースト、▶︎ クリックか、SHIFT+ENTER するか のいずれかで実行されます。
※ExcelファイルとCSVファイルではすこしコードが異なります。(以下参照)
- Google colabにアップロードしたデータの読込み:(ファイル名がtextの場合)
df = pd.read_excel('test.xlsx')
df = pd.read_csv('test.csv')
補足
⁻ ここで紹介するデータを格納したデータフレームは、すべて[df]としています。
⁻ データは、横軸:項目、縦軸:サンプルとなったマトリクスをイメージしてください。例えば製品アンケートの場合、「かっこいい,使いやすい、持ちやすい・・・」が項目、(例えば5段階の)回答結果(Aさん,Bさん、Cさん・・・)がサンプルとなります。
⁻ 上のコードの df = pd.read_excel('test.xlsx') は、[pd]:Pandasというライブラリで、[read_excel]:Excelファイルを読込み、[df]というデータフレームに格納するということです。
基本統計量
まずは、平均、標準偏差などを見てみましょう。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
相関係数行列はとても便利です。
この効果は列数が多いデータであるほど実感するはずです。
- 以下で平均や標準偏差、最大値、最小値など、基本データが得られる
df.describe()
df.corr()
meanA = df["列の名前"].mean()
stdA = df["列の名前"].std()
print(meanA - stdA,"~", meanA + stdA)
補足
- ”列の名前”は、データにより任意です。例えば、”売上”という列データを確認したい場合は、”売上”と入力します。
- 列の名前を確認したい場合は、▶︎ 入力枠に「df.columns」と入力し、実行すると、表示されます。
⁻ データ全体を確認したい場合は、▶︎ 入力枠に「df」と入力し、実行すると、表示されます。
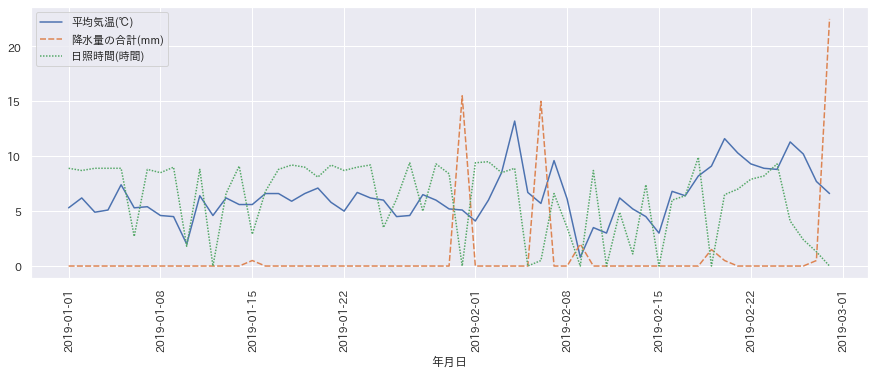
折れ線グラフ
ExcelでできることはExcelでとしておきながら、いきなりExcelでも描ける折れ線グラフの紹介となります。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
- figsize:グラフの大きさ、xticks:x軸の表示の回転(90なら縦表示)
plt.figure(figsize=(15,5))
plt.xticks(rotation=90)
sns.lineplot(data=df)
例
補足
- plt.figure(figsize=(15,5)) の (15,5) の値を任意に変更することで、グラフの大きさが変わります。なお、plt.figure(figsize=())というコードはなくてもグラフは描けます。
- plt.xticks(rotation=90) は値変更により、x軸の表示の角度が変わります。なお、このplt.xticks(rotation=**) というコードもなくてもグラフは描けます。
- ここでは紹介しませんが、線の色、線の形状、プロットの色や大きさ、凡例の表示など、ほかにも細かな設定ができます。
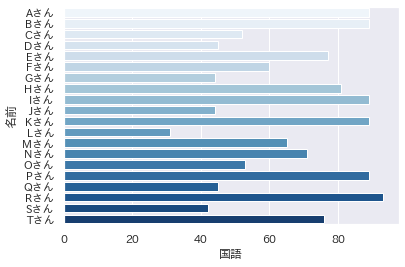
棒グラフ
またもExcelでできることで申し訳ないが、棒グラフの紹介となります。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
- paletteは未記入ならデフォルト、Blues以外も多々指定可能
sns.barplot(data=df,x='列の名前',y="列の名前",palette="Blues")
例
補足
- palette はカラーパレットのことです。"Blues"以外も設定できます。様々なカラー表現を楽しむことができるのもPythonグラフの特徴のひとつです。
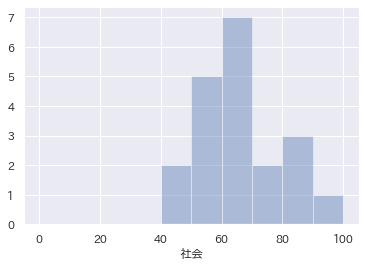
ヒストグラム
これもExcelでできなくはないですが、Pythonでは密度曲線や正規分布曲線の同時表示も可能です。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
- seabornでの記述
- hist_kws ={"range":(0,100)} は横軸を0-100に、binsはビン数指定(未記入ならデフォルト)、kde = Falseで密度曲線カットされる
sns.distplot(
df['列の名前'], bins=10, hist_kws ={"range":(0,100)},
kde = False
)
例
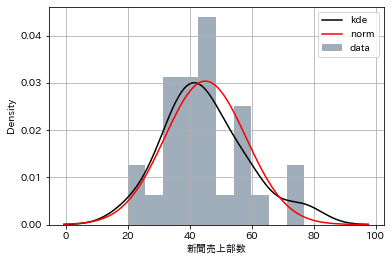
- 以下より細かな指定をしたケース。fit=normで正規分布曲線が表示できる
sns.distplot(
df['列の名前'],bins=10, color='#123456',label='data',
kde_kws={'label': 'kde','color':'k'},
fit=norm,fit_kws={'label': 'norm','color':'red'},
rug=False
)
plt.legend()
plt.grid()
plt.show()
例
補足
hist(df.loc[df['①'] == 0,'②'].dropna(),range(0,100),bins=25,alpa=0.5,label='③') の場合、dfの’①’が0の’②'を取得し、欠損値は削除(dropna)するという意味。bins=25はビン数、alphaは透明度(デフォルトは1)、label='③'でラベル表示内容を指定。
legend(loc=’upper right’,title=’⑤’)は凡例タイトル位置と表示の指示。
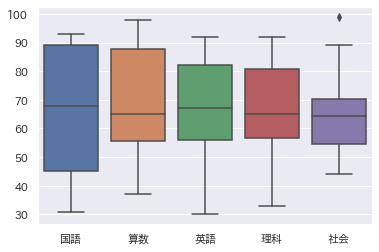
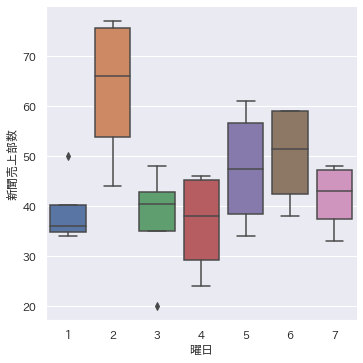
箱ひげ図
箱ひげ図もExcelで描くことができますが、Pythonで描けるバリエーションはすごくたくさんあります。(以下紹介するものはその一部)
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
- sns.boxplot(x =‘指定’, y=‘指定’, data=df) ←x,y軸を指定する場合
sns.boxplot(data=df)
sns.stripplot(data=df)
例
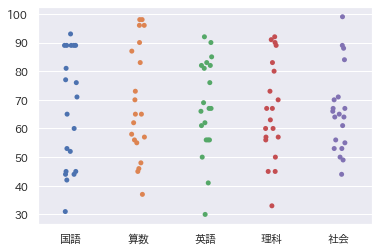
sns.swarmplot(data=df)
例
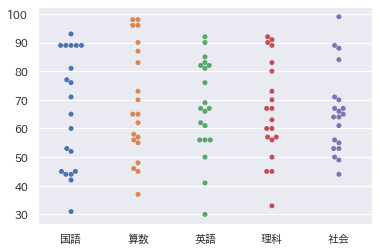
- facetplotと呼ばれるもの。kindで種類選択:bar, box, pointできる
sns.factorplot(data = df, x = '列の名前', y = '列の名前', kind='box')
例
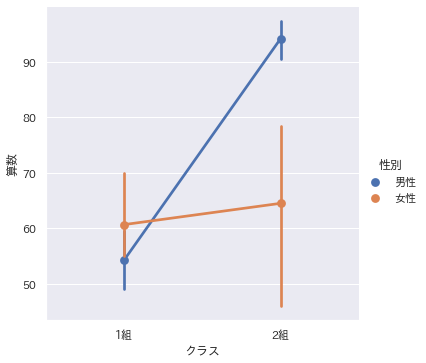
sns.factorplot(data = df, x = '列の名前', y = '列な名前', hue='層別列の名前',kind='point')
例
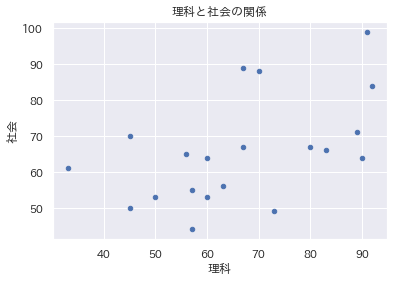
###散布図
散布図もExcelで描くことができますが、層別でとなると簡単ではなかったともいます。
Pythonは層別散布図が簡単に描けます。
例えば、満足度のアンケート結果で、「男・女」を層別した状態で散布図が描きたい!という場合、「男・女」=性別データが入力された列を指定するだけです。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
df.plot.scatter(x="列の名前", y="列の名前", c="b")
plt.title("○○")
例
⁻ 以下は、グラフサイズ(plt.figure)、x,y軸(plt.xlim,plt.ylim)の範囲を指定している
plt.figure(figsize=(8,8))
plt.xlim(0,100)
plt.ylim(0,100)
sns.scatterplot(data=df,x='列の名前',y='列の名前',hue="層別列の名前")
例
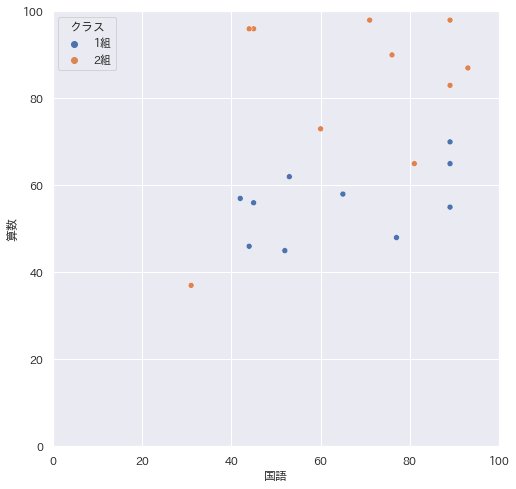
補足
- plt.figure(figsize=(8,8)) の (8,8) の値を任意に変更することで、グラフの大きさが変わります。なお、plt.figure(figsize=())というコードはなくてもグラフは描けます。
- plt.xlim(0,100),plt.ylim(0,100)は、X軸,Y軸の範囲指定です。これらのコードはなくてもグラフは描けます。(デフォルトで表示されます)
散布図+回帰直線
これぞ、Python!といえるグラフです。
散布図とヒストグラムの合わせ技に、回帰直線+信頼区間という贅沢なおまけまでついたグラフ。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
sns.jointplot(data=df, x="列の名前", y="列の名前", kind="reg",
line_kws={"color":"red"})
plt.show()
例
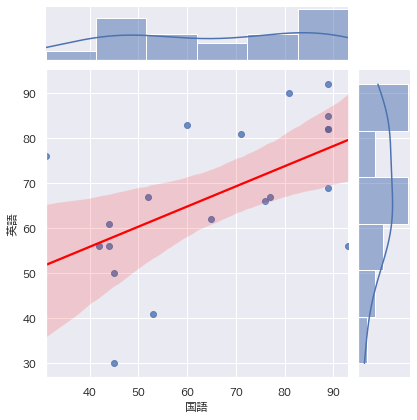
補足
- kind="reg"は、回帰直線を描く指示です。この他にもkind="kde",kind="hex"などもあります。変えてみて実行するとおもしろいでしょう。
- line_kws= で回帰直線の色を指定しています。線の太さ等より細かな設定も可能です。
ヒートマップ
以下の例は、5教科の点数の相関係数行列をヒートマップで描いたものです。
項目数が多いほど、全体把握がむつかしくなるので、このような見方ができるのはとても助かります。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
sns.heatmap(df.corr(), annot=True, vmax=1, vmin=-1, center=0)
plt.show()
例
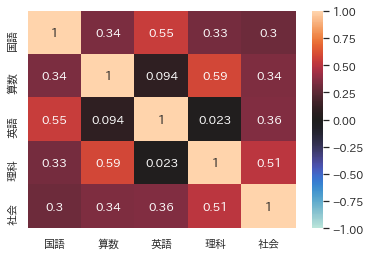
補足
- リストannot=Trueで数値を表示します。
- vmax, vmin, centerは最大値、最小値、中央値の指定です。(相関係数行列なので-1~+1、センターは0としています)
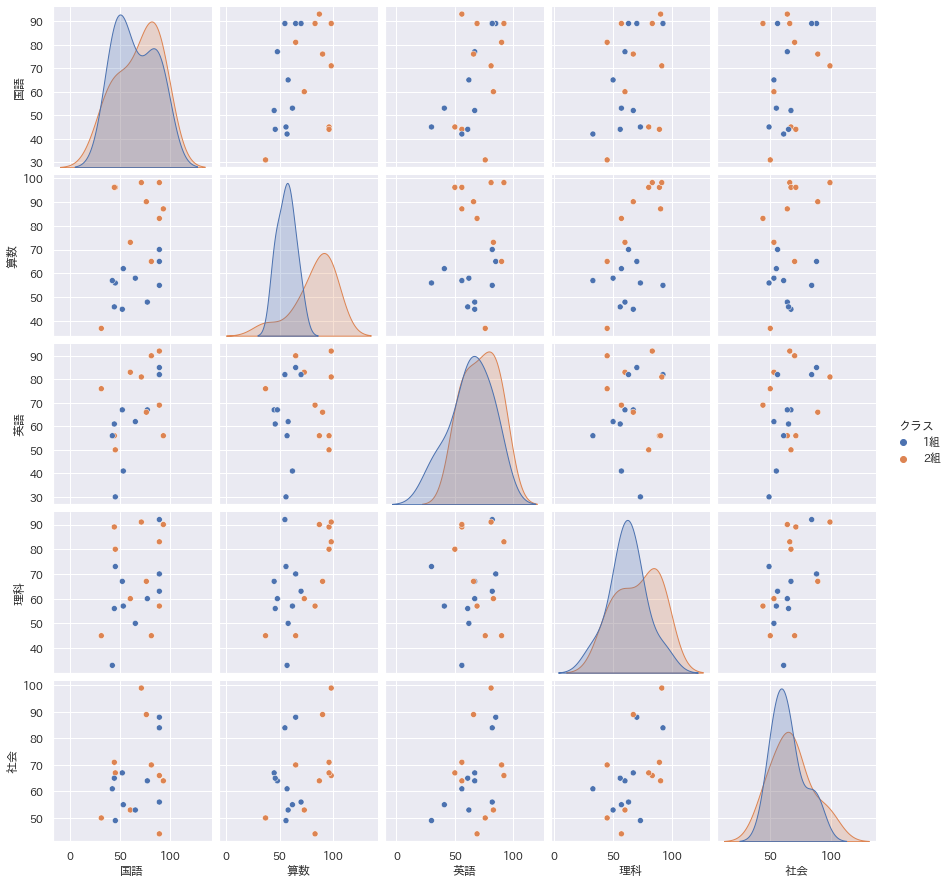
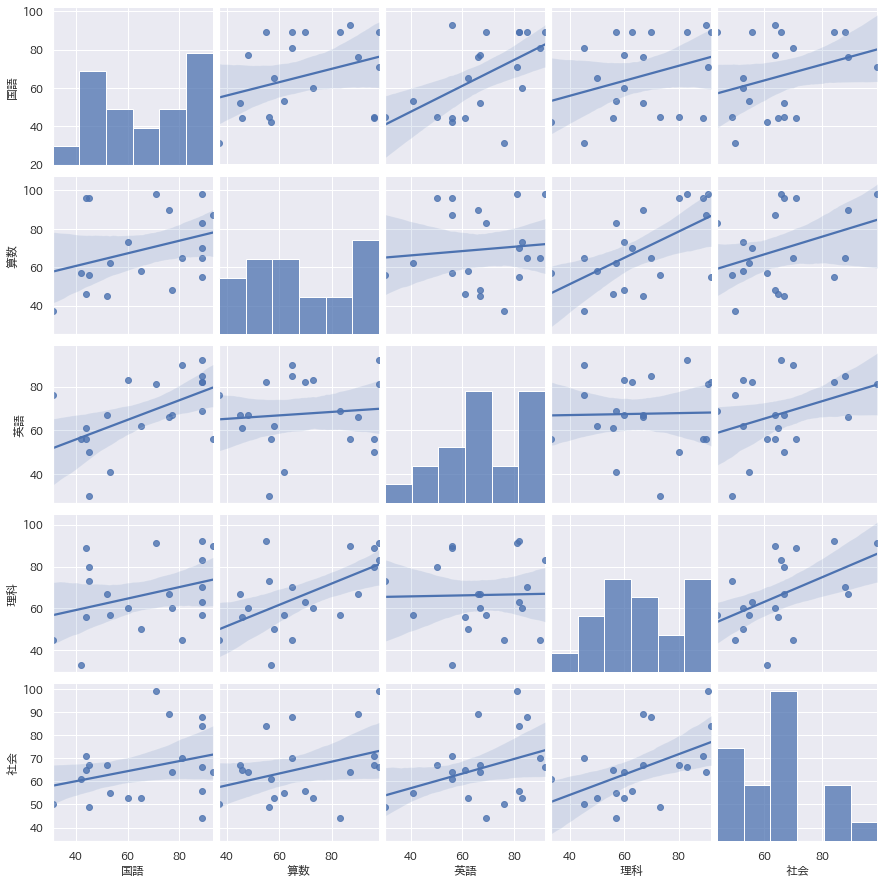
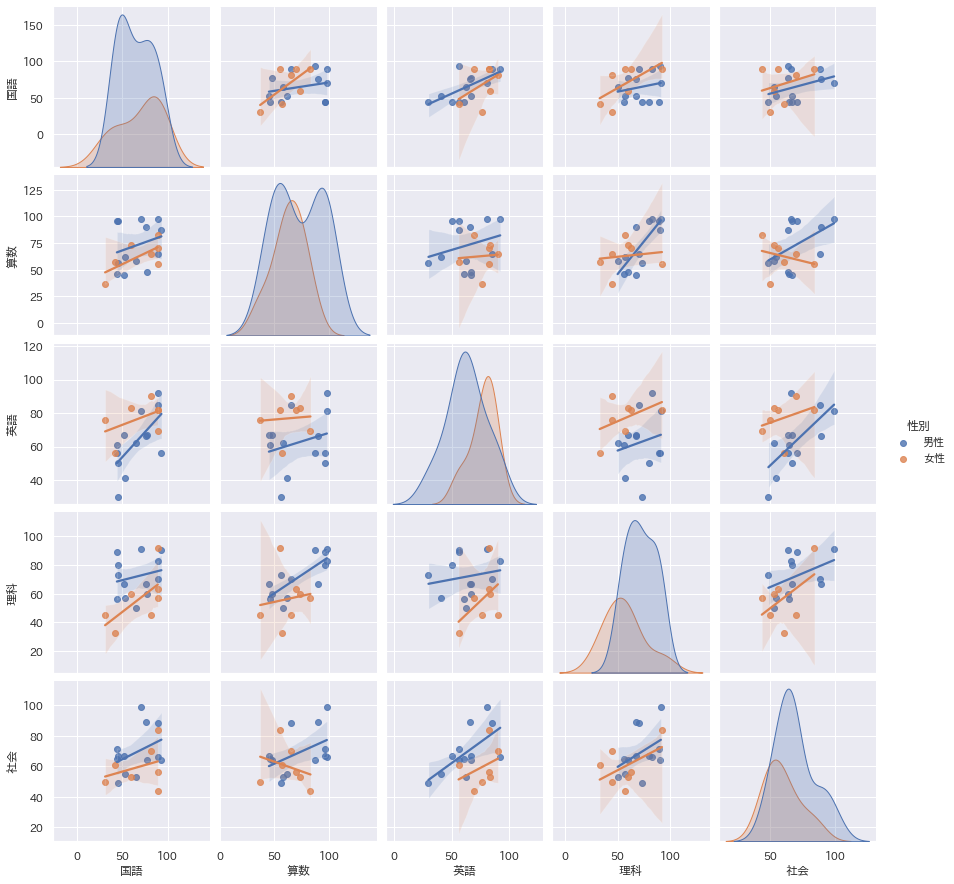
散布図行列
もうこのグラフは感動ものですね。ペアプロットとも呼ばれるこのグラフを書くためだけにPythonを使うというのもありと思います。
層別も回帰直線+信頼区間表示も簡単です。
多くのデータがあり、まず全体傾向を掴みたいという時、これはかなり重宝します。
同じように、以下のコードをコピーし、▶︎ 入力枠にペーストし、実行するだけです。
sns.pairplot(data=df)
plt.show()
例
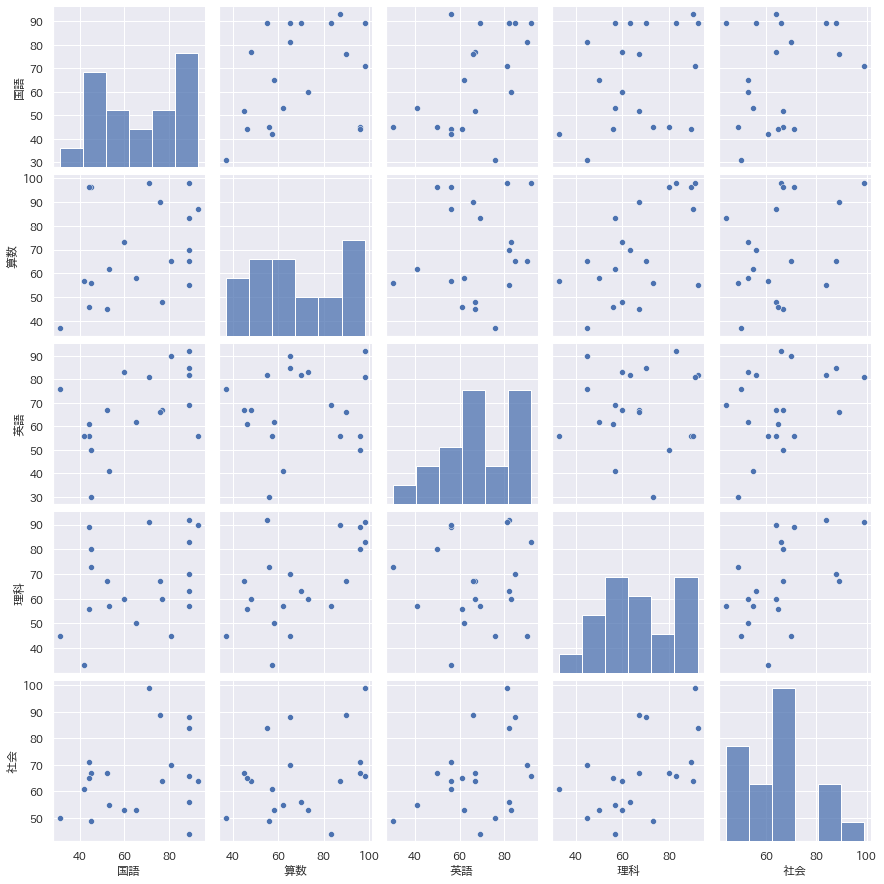
- hue="クラス"で層別
sns.pairplot(data=df,hue="層別列")
列
sns.pairplot(data=df, kind="reg")
plt.show()
例
sns.pairplot(data=df, kind="reg",hue='列の名前')
plt.show()
例
最後に
まずは、Pythonでどんなグラフが描けるか?を知ることが先決。
あくまで代表的なものだけとなるが、知っていただくきっかけになればと思います。
「Python」というだけで拒否反応を示す方もいるかもしれないけれど、描きたいグラフがはっきりしていれば、コードをコピペすればできます。
言語を理解することも大事だと思いますが、さわって楽しめないと続かない気もしますので、そこからでも全然ありと思います。
参考サイト