はじめに
【論文】日本におけるテキストマイニングの応用(齋藤朗宏氏) に、以下のテキストマイニングの現状に関する記述がありました。
『テキストマイニングには多くの応用事例がある。しかし、分析という観点からみると、用いられている手法はかなり絞られている。単純な集計を行うか、単語間の出現の割合を分析するか、テキストの属性の特徴を出現単語を用いて分析するといった、記述的な分析手法が大半を占めている。推測的な方法としては、機械学習によるテキストの分類が主となっている。
テキストデータの場合、形態素解析され、また、係り受け解析されたデータから必要な部分をいかに抽出して実際に用いるデータとするかは、本来的には分析者に委ねられているものであり、(中略)個々の目的に合わせたデータの作り方をするのは応用研究を行うものには困難が大きい。ソフトウェアが示す手順通りに分析を行うとなると、基本的な名詞を抽出して単語間の関連を見る、単語と属性の関係を見るという段階に留めざるを得ないのが現状なのだろうと思われる。』
まさに実情を言いあらわしておられるなと思います。
テキストマイニングには、機械学習によるテキスト分類(word2vecなど)等、様々なアプローチがありますが、これらは出現単語や単語の関連傾向を区分しているもの=基本的な計量テキスト分析に留まっていることが多く、テキストの訴えや志に近づけていない。。。近年、自然言語分析技術は飛躍的な進化をとげていますが、すべて機械頼みとするのは乱暴に思えます。
ただ、切り札や特効薬はありませんので、その時々の目的に応じ、アプローチを考えて試行錯誤するしかありません。
このような現状ですから、「このテキストデータまとめて欲しい」という依頼が飛び込むと「マジか」となります。まとめる道筋も、どこまでやればケリがついたといえるかも定まらないからです。
このような時、何度かわたしを救ってくれたのが「共起ネットワーク」です。
以前は目立った単語だけを拾い集めて「こんなことなんじゃないかなぁ」といった解釈で終わっていましたが、
『何もかもを「共起ネットワーク」にすがるのではなく、テキストのバラエティ把握までの活用に留め、そこから先は人的に分析するぞ。』
このように割り切ってから、スムーズに実行できるようになったように思います。
また、バラエティ把握までの活用に留めたことで、ネットワークの用語や姿をより把握しないと思うようになり、これもプラスに働いたように思います。
これらを踏まえ、ネットワークって何なの?ということと、自然言語ライブラリ nlplot を利用したバリエーション把握までの手続きについて書いてみましたというのが、このコラムです。
友人関係をネットワークで例えると?!
ネットワークの例えとして、以下のようなケースを想定してみます。
- 友人はとても多いが友人同士に関わりはない ⇔ 友人がとても多く友人同士の関わりも深い
- 友人は少なく友人同士の関わりもない ⇔ 友人は少ないが友人同士の関わりは深い
どのケースの友人関係が把握しやすいでしょうか?
取り上げたケースが、友人関係の関わりの多さと深さで表現されているとわかれば、どのケースが把握しやすいかは簡単にわかります。
友人関係がもっとも把握しやすいのは「友人は少ないが友人同士を含めた関わりは深い」ケース、もっとも把握しにくいのは「友人はとても多いが友人同士に関わりはない」ケースです。
テキスト分析も友人関係と同じで、「関連単語は少ないが関連単語同士を含めた関わりは深い」というケースは把握が容易で、「関連単語はとても多いが関連単語同士に関わりはない」というケースは把握しにくくなります。
次に、友人関係の違いによって、ネットワークの姿がどうなるかについてみてみたいと思います。
- 友人はとても多いが友人同士に関わりはない
というときは、あるホストとなる友人から放射状にパスが広がったネットワークとなります。- 友人がとても多く友人同士の関わりも深い
というときは、あるホストとなる友人から放射状にパスが広がり、かつ広がった先の友人同士のパスもつながったネットワークとなります。- 友人は少なく友人同士の関わりもない
というときも、ホストとなる友人から放射状にパスが広がったネットワークとなります。先との違いはパスの数が少ないというものです。- 友人は少ないが友人同士の関わりは深い
というときも、あるホストとなる友人から放射状にパスが広がり、かつ広がった先の友人同士のパスもつながったネットワークとなります。先との違いはパスの数が少ないというものです。
要するに
- 把握しやすいネットワークの姿は、パスが少なくパスの先の同士もパスがつながっている。
- 把握しにくいネットワークの姿は、多くのパスが放射状に広がっている。(例:複数端末がホストPCにつながるが端末同士はつながっていない等)
友人の関わりのケースを通して、ネットワークの姿をイメージしてみました。
ただ、現実は このケースように単純に把握できるものばかりではありませんね。
複雑なネットワークの把握を容易にするには?
ここまでは、友人の関わりを例とした単純なケースのネットワークに触れましたが、現実はいくつかの要素が複合的に混在した複雑系ばかりです。
友人関係でいえば、地元の友人、学生時代の友人、仕事関係の友人等となり、地元の友人のなかにも、習い事仲間、飲み友達、幼なじみ等の要素の混在が想定されます。
これらの把握を容易にするため、ネットワークの全体をいくつかのブロックに分ける方法があります。
これはコミュニティと呼ばれ、「ネットワークの内部の頂点間の結合が密で、外部の頂点との結合が疎である部分ネットワーク」のことだそうです。
シンプルには「密に結びついた部分ネットワーク」ということになります。
コミュニティは、クラスター分析のような性質のものなので、1つのコミュニティは1つのクラスターとなります。このグループ分けにあたるコミュニティ毎に、関わりの多さ、関わりの深さ をとらえられると把握の助けとなります。
ややこしいネットワークの用語は、例えて慣れるしかない
ここで、ネットワークの用語に触れたいと思います。
以下は、友人のケースをネットワーク用語で表現したものです。
- 友人 :ノード
- パス :エッジ
- グループ分け :コミュニティ
- 関わりの多さ :エッジの数
- 関わりの深さ :クラスタ係数(0~1)
- 影響の大きさ :中心性
あらたに中心性という用語が出てきました。
「友人はとても多いが友人同士に関わりはない」というケースの場合、キーとなる友人が存在しなければ友人との関係は完全に途切れます。
ホストPCから多くの端末つながっているという場合は、ホストPCの死はネットワークの死を意味します。
これら例のように、ネットワークの各要素には影響の大小があり、これが中心性という特徴量になります。
ネットワーク統計量の補足
- 中心性(centrality)は、あるノードのネットワーク内における中心度のこと。次数中心性、近接中心性、固有ベクトル中心性、媒介中心性などさまざまな指標がある。共起ネットワークで利用されていることが多い媒介中心性(betweennesscentrality)は、あるノードが、それ以外の2つのノードを結ぶ最短経路上にあるかどうかについての指標で値が大きいほど中心性が高い。
- 密度(density)は、ネットワークの混み具合を示す度合。ノードの数nを、エッジの数をmとすると、無向グラフはdensity=2m/n(n-1) で定義される。(有向グラフは density=m/n(n-1))密度はグラフのエッジの混み具合を示す指標で、エッジの数が多いほど密度は大きく、ネットワークは複雑になる。密度は0〜1の値をとり、すべてのノードとノードがエッジがつながったグラフの密度は1のとなり、これを完全グラフとよぶ。
- クラスター係数は、ノードの近傍の関係を示す度合。あるノードに隣接するノード同士の間につながりがあるかどうか、つまり、三角形ループが形成されるかどうかについての指標。すべてのノードのクラスター係数の平均値をネットワーク全体のグローバルクラスター係数と言い、個別のノードのクラスター係数をローカルクラスタ一係数と言う。
テキストを共起ネットワークで見てみよう
テキスト分析におけるネットワークといえば「共起ネットワーク」です。
共起ネットワークは、どの単語とどの単語が同時に出現しているかをJaccard係数というものを用いて判定し、そのつながり具合が反映されたネットワークです。
自然言語ライブラリ nlplot で共起ネットワークを描くと、
まず目につくのが、色分けされたバブル(ノード)です。色の違いはコミュニティを表しており、同じ色=同じコミュニティとなります。
バブル(ノード)サイズは、パス(エッジ)が多いほどが大きくなっており、関連する単語はパス(エッジ)で結ばれています。
パスがどのようなつながりが持つかによって「関わりの深さ」が、ネットワークにおけるバブル(ノード)の位置づけから「影響の大きさ」がわかるというものとなっています。
以下は、前回の記事 で描いた共起ネットワークです。

また、nlplot は sunburst chart というチャートも描けます。(※適用データは上の共起ネットワークと同じです)
コミュニティ毎の単語が円グラフに配置され、エッジの数がグラフの幅で、中心性(影響の大きさ)が色の濃さで表現されます。
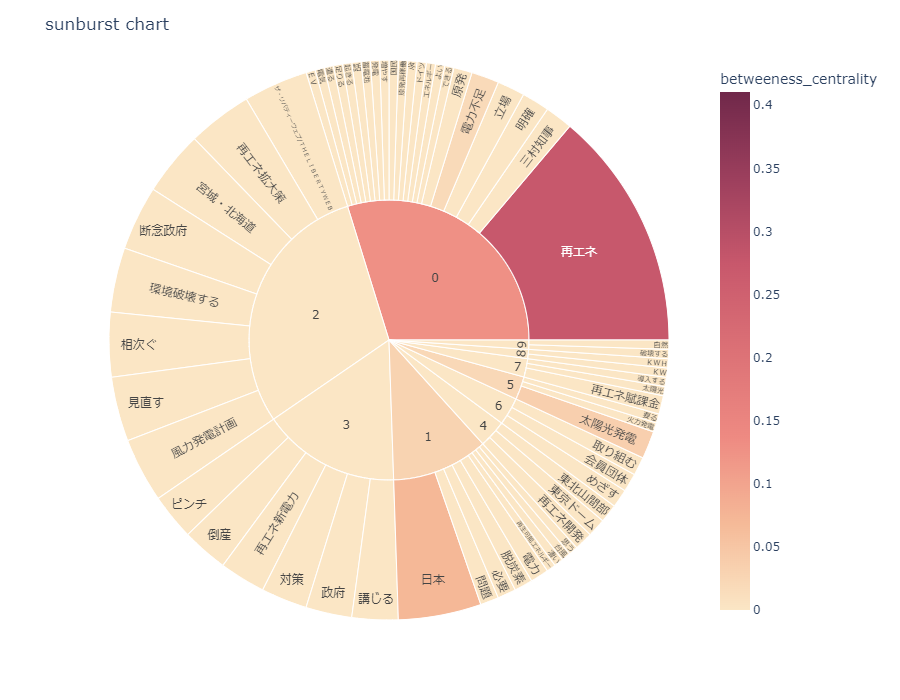
また、コミュニティ番号(円グラフの内側の番号)をクリックすると、以下のようにクリックしたコミュニティ番号に絞られた円グラフになります。(再度番号クリックで元に戻せます。)

この sunburst chart と共起ネットワークを照らし合わせれば、グループ(コミュニティ)毎の単語種類、単語の関係の多さ、影響の大きさ、関わりの深さがわかります。
これを頼りに原文を辿れば、効率的にテキスト分析を進めることができます。これは便利です。
※bettweeness_centrality というのは(媒介)中心性、部分ネットワークにおける影響度の大きさを示しています。再エネに次いで大きいのは電力不足。あとは影響度が低いものばかりです。また、円の幅は他の単語との関連の多さです。
影響度が低く、関連も少ない単語は重要ではないということではありません。共起ネットワークを見るとよくわかりますが、円の幅も狭く影響度も低いものはネットワークの外に・・・要はこれで部分ネットワークにおける単語の位置づけがわかるのです。
※共起ネットワークもコミュニティ毎にできれば・・・、もう最高なのですが、これはできません。
共起ネットワークを手掛かりに効率的な原文検索を
共起ネットワークを描いた時点では、ネットワーク全体の意味もブロック分けされたコミュニティの意味もわかりませんので、ネットワークを読みながら理解をすすめていくことになります。
まずは
- コミュニティ毎にネットワークの姿や単語を確認する(sunburst chart との合わせ技が便利)
次に
- 単語の関係の多さ、関わりの深さで原文検索のポイントを絞る
とした時、
単語同士の関連が深いネットワークは、ネットワーク内の単語のどれかを検索すれば、関連単語も引っ掛かりますが、単語同士の関連が薄いネットワークは、やみくもに検索するのはよくなさそうです。「友人同士の付き合いが薄いある友人を調べても友人関係をつかむことはできない」という状況になるからです。
以下は、前回の記事で描いた共起ネットワークでこのケースに該当する関係を切り取ったものです。
この場合、「再生可能エネルギー」だけを検索しても部分把握にしかならないことがわかります。もっとも多くの単語と関わりを持つ「日本」で検索しないとコミュニティ(部分ネットワーク)の把握にはつながりません。

関連する単語が多い単語、ネットワークの中で中心性が大きい単語を捕まえることが重要となります。
以下は別の箇所を切り取ったものです。
「宮城・北海道-再エネ拡大策-見直す」、「三村知事-立場-明確」という2つのトライアングルがあります。3つの単語の組合せだけで雰囲気が予想できます。このケースの場合、単語間に関わりがありますので、コミュニティ(部分ネットワーク)の把握につなげる原文検索は いずれかの単語を検索するだけでよいということになります。

最後に
ネットワーク全体を眺め、全体におけるコミュニティを把握し、コミュニティの理解を深めてゆく・・・
「全体感を把握する上で欠かせないと思える原文」をコミュニティ毎にピックアップすれば、きっと効率的なテキスト把握につなげられると思います。
このコラムでは、ネットワークをすこし身近なものとするため、コミュニティ、エッジの数、クラスタ係数、中心性等、普段なじみのない用語を、ベタなケースに置き換えてみました。
すこしでもネットワークが身近になり、テキスト分析に適用した時の抵抗感が和らぐとよいなと思います。
余談
このコラムに書いた内容は、ありがたいことに自然言語ライブラリ nlplot でスルスル実行できます。
※ 前回の記事でツイートデータを題材としたテキストのバリエーション把握を取り上げています。
また、 nlplot は、このコラムで触れた、エッジの数、クラスタ係数、中心性というネットワークの特徴量をデータフレームに取り出すこともできます。
エッジの数、クラスタ係数、中心性は、単語の関係の多さ、関わりの深さ、影響の大きさとなるので、おまけでグラフに表示(縦軸をエッジの数(単語の関係の多さ)、横軸をクラスタ係数(関わりの深さ)、中心性(影響の大きさ)はバブル)してみました。

ただ、だから何?という感じです。
先の通り、テキスト分類にはいくつかのアプローチがありますが、私は nlplot によるアプローチが、一番 単語の関係や状況を立体的に示してくれているように感じます。これはありがたいです。
参考