~手元データの要約、視覚化を超簡単に実現して、探索的データ解析(EDA)しよう(DataPrep編)~

2022/05/09更新
公式のGithub に公開されているDemo in Colab の通り、ライブラリインストールを!pip install -U git+https://github.com/sfu-db/dataprep.git@develop --quiet としていました。以前はGoogle colabで動作していましたが、importで引っかかるので、!pip install dataprep としました。これで私の環境では動作しています。
はじめに
「”すぐ” このデータまとめて欲しい」に ”すぐ”に超簡単に応えられる Python の・・・ と題し、
「おい、悪いが”すぐに”このデータまとめてくれ」
に応えるための探索的データ分析(EDA)ツールを、これまでに4つ紹介しました。
今回紹介するのは、DataPrepという名のEDA。
この手のAutoEDAツールでは、PandasProfiling(以下参照)が一番ポピュラーではないかと思いますが、
DataPrepは、よりインタラクティブで、しかも処理がめちゃくちゃ速いので、個人的には一番のおすすめです。
この記事で紹介するDataprepについて
DataPrep.EDAは、Pythonで最も速く、最も簡単なEDA(Exploratory Data Analysis)ツールです。数行のコードで美しいプロファイルレポートを作成することができます。
このライブラリは、公式のGithub に公開されているDemo in Colab をベースに ①外部ファイルの読込み、②フォームによるカラム設定、③日本語化 を図ったものです。
データについて
- csvデータの表形式は以下としてください。
| 列1 | 列2 | 列3 | 列4 | 列5 | 列6 | … |
|---|---|---|---|---|---|---|
| data | data | data | … | data | … | data |
| data | data | data | … | data | … | data |
| ・ | ・ | ・ | … | ・ | … | ・ |
| ・ | ・ | ・ | … | ・ | … | ・ |
| ・ | ・ | ・ | … | ・ | … | ・ |
- [注意] csvデータは文字コードを「UTF-8」としてください。
実行手順
- メニューバーの「ランタイム」から「すべてのセルを実行」をクリック。
- ライブラリインストール完了後、[ファイル選択] を促されるので、クリックしてデータ(csvファイル)を指定する。
- Google colabのフォーム機能を利用し、分析を行うカラムを番号で指定できるようにしています。指定番号変更後は該当のセルを再実行してください。
実行条件など
・Google colabで実行
・Titanicのデータセットで実行
ライブラリのインストールおよびインポート
!pip install dataprep
# ライブラリのインポート
from dataprep.eda import *
from dataprep.datasets import load_dataset
from dataprep.eda import plot, plot_correlation, plot_missing, plot_diff, create_report
import pandas as pd
import warnings # 実行に関係ない警告を無視
warnings.filterwarnings('ignore')
ファイル読込み
#@title ファイルを指定してください
from google.colab import files
uploaded = files.upload()
if len(uploaded.keys()) != 1:
print("アップロードは1ファイルにのみ限ります")
else:
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
プロファイルレポート作成
create_report() で、データセットの包括的なプロファイルレポートを生成します。 このレポートには、以下の情報が含まれています。
- 概要:データフレーム内の列の種類を検出する
- 変数:変数の種類、ユニークな値、distint count、欠損値
- 最小値、Q1、中央値、Q3、最大値、範囲、四分位範囲などの四分位統計量
- 平均値、最頻値、標準偏差、総和、中央値絶対偏差、変動係数、尖度、歪度などの記述統計量
- 長さ、サンプル、レターなどのテキスト分析
- 相関関係:相関の高い変数のハイライト、スピアマン、ピアソン、ケンドール行列
- 欠損値:欠損値の棒グラフ、ヒートマップ、スペクトル
#@title プロファイルレポート
create_report(df)
** ↓ 以下がプロファイルレポート**
データセット概観
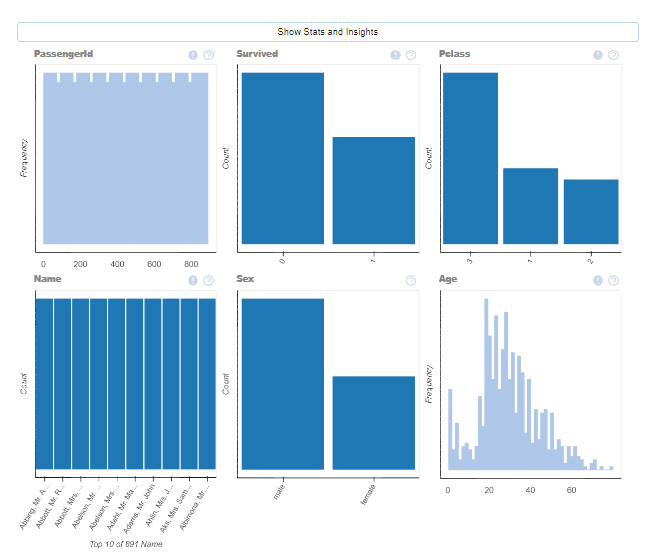
plot()関数は、データセットの分布と統計量を調査します。
データフレームdfに対するplot()の機能は以下の通りです。
- plot(df): 各カラムの分布をプロットし,データセットの統計量を計算する
- plot(df, x): 列xの分布を様々な方法でプロットし、列の統計量を計算する
- plot(df, x, y): 列 x と y の間の関係を表すプロットを生成する
#@title データカラム、欠損値とデータ型の確認
df.info()
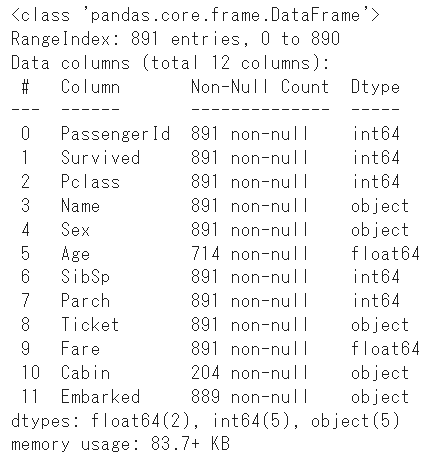
#@title データセットの各カラムの統計量と分布のプロット
plot(df)
要素毎の詳細確認
欠損値の影響確認
plot_missing()関数は、欠損値とそれがデータセットに与える影響を確認することができます。
データフレーム df に対する plot_missing() の機能は以下の通りです。
- plot_missing(df): 欠損値の量と位置、および列間の関係をプロットする。
- plot_missing(df, x): 列 x の欠損値が他の全ての列に与える影響をプロットする。
- plot_missing(df, x, y): 列 x の欠損値が列 y に与える影響を様々な方法でプロットする。
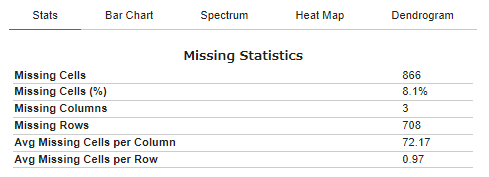
1. データセットの欠損値
#@title データセットの欠損値サマリ
plot_missing(df)
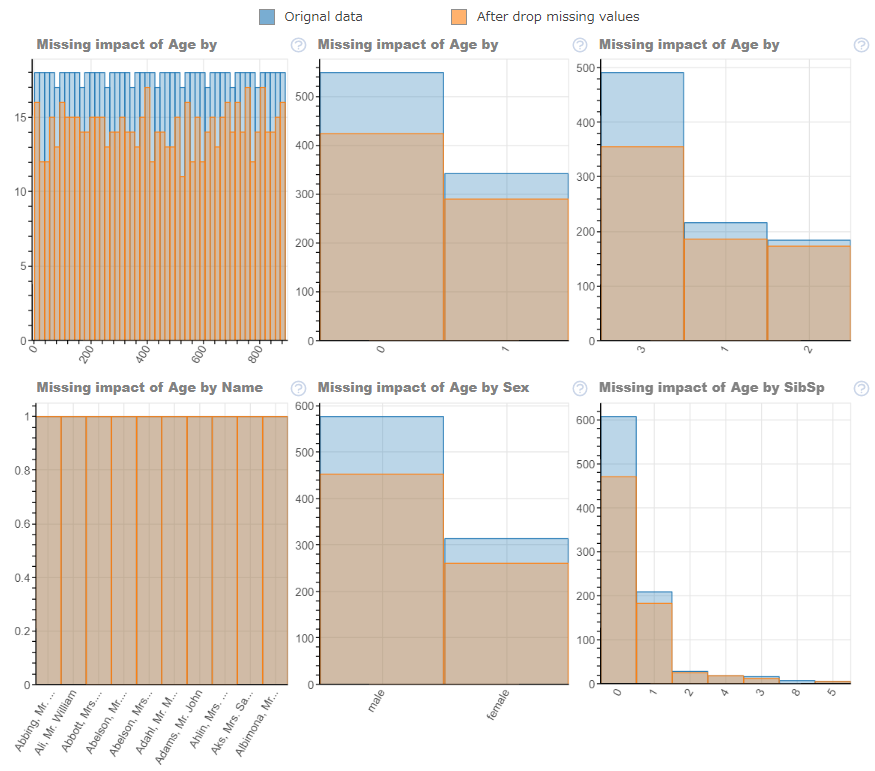
2. 指定したカラムの欠損値が他のカラムに与える影響
#@title データカラムを確認しましょう
df.info()
#@title 欠損値影響を確認したいカラム番号を指定してください(カラム番号は 0~です){ run: "auto" }
Missing_column_Number = 5 #@param{type:"number"}
print('** ↓指定カラムは以下です↓ **')
df.columns[Missing_column_Number]
#@title 欠損値影響の可視化
#plot_missing(df, "x") ← x を指定
plot_missing(df, df.columns[Missing_column_Number])
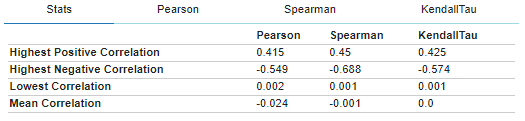
相関関係の確認
plot_correlation()関数は、様々な方法で、複数の相関メトリックを使用して、列間の相関を調べます。
与えられたデータフレーム df に対する plot_correlation() の機能は以下の通りです。
- plot_correlation(df): 相関行列をプロットする(列のすべてのペアの間の相関)。
- plot_correlation(df, x): 列xに対して最も相関のある列をプロットする。
- plot_correlation(df, x, y): 列 x と列 y の結合分布をプロットし、回帰直線を計算する。
1. データセットの相関関係
#@title データセットの相関関係
plot_correlation(df)
2. 指定したカラムと他のカラムとの相関
#@title データカラムを確認しましょう
df.info()
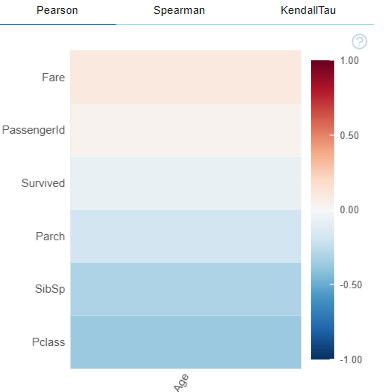
#@title 相関を確認したいカラム番号を指定してください(カラム番号は 0~です){ run: "auto" }
Corr_column_Number = 5 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Corr_column_Number]
#@title 指定したカラムと他のカラムの相関関係
#plot_correlation(df, "x") ← x を指定
plot_correlation(df, df.columns[Corr_column_Number])
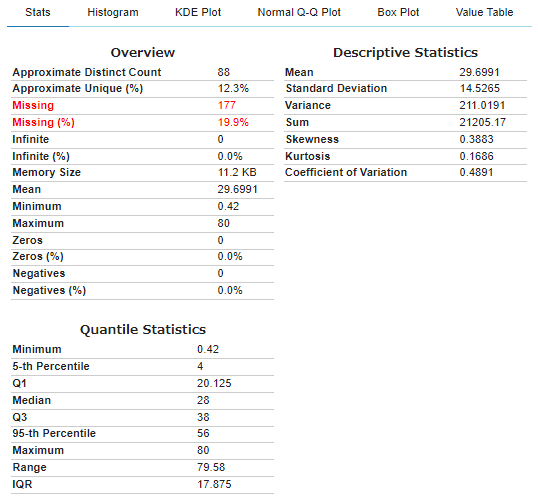
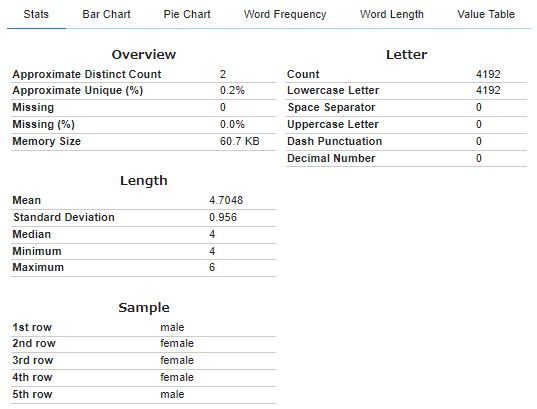
詳しく見たいカラムの分析
plot()関数は、データセットの分布と統計量を調査します。以下は、与えられたデータフレームdfに対するplot()の機能を説明するものです。
- plot(df): 各カラムの分布をプロットし,データセットの統計量を計算する
- plot(df, x): 列xの分布を様々な方法でプロットし、列の統計量を計算する
- plot(df, x, y): 列 x と y の間の関係を表すプロットを生成する
※以下3つの枠を設けていますので、3つのカラムまでは同時表示できます。
「Column_Number1:」,「Column_Number2:」,「Column_Number3:」にてカラム番号を指定してください。
1. 指定カラム1のプロット&統計量
#@title データカラムを確認しましょう
df.info()
#@title 分析したいカラム番号を指定してください(カラム番号は 0~です) { run: "auto" }
Column_Number1 = 5 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Column_Number1]
#@title 指定カラムのプロット&統計量
#plot(df, "x") ← x を指定
plot(df, df.columns[Column_Number1])
2. 指定カラム2のプロット&統計量
#@title 分析したいカラム番号を指定してください(カラム番号は 0~です) { run: "auto" }
Column_Number2 = 4 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Column_Number2]
#@title 指定カラムのプロット&統計量
#plot(df, "x") ← x を指定
plot(df, df.columns[Column_Number2])
3. 指定カラム3のプロット&統計量
#@title 分析したいカラム番号を指定してください(カラム番号は 0~です) { run: "auto" }
Column_Number3 = 10 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Column_Number3]
#@title 指定カラムのプロット&統計量
#plot(df, "x") ← x を指定
plot(df, df.columns[Column_Number3])
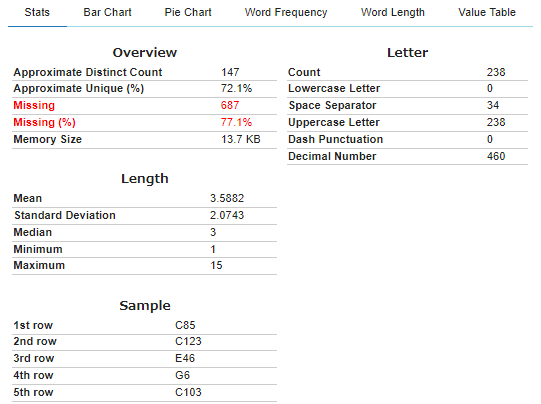
#@title データカラムを確認しましょう
df.info()
#@title ヒストグラムを描きたいカラム番号を指定してください(カラム番号は 0~です) { run: "auto" }
Hist_column_Number = 5 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Hist_column_Number]
#@title ヒストグラム表示
plot(df,df.columns[Hist_column_Number], display = ["Histogram"])
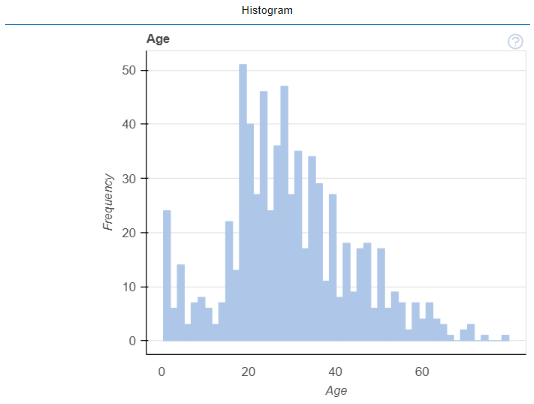
#@title ヒストグラム表示(カスタマイズ) { run: "auto" }
plot(df, df.columns[Hist_column_Number], display = ["Histogram"], config = {"hist.bins": 1000, "height":500})
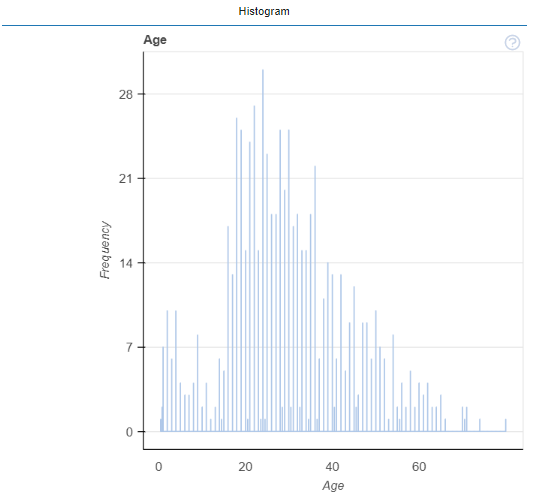
変数間の関係確認
1. カラムA1とB1の関係
#@title データカラムを確認しましょう
df.info()
#@title 比較したいカラム番号を指定してください(カラム番号は 0~です)
Column_Number_A1 = 5#@param{type:"number"}
Column_Number_B1 = 9#@param{type:"number"}
print('↓指定カラム A, B↓')
df.columns[Column_Number_A1],df.columns[Column_Number_B1]
#@title カラム同士の関係
#plot(df, "x", "y") ← x, y を指定
plot(df, df.columns[Column_Number_A1], df.columns[Column_Number_B1])
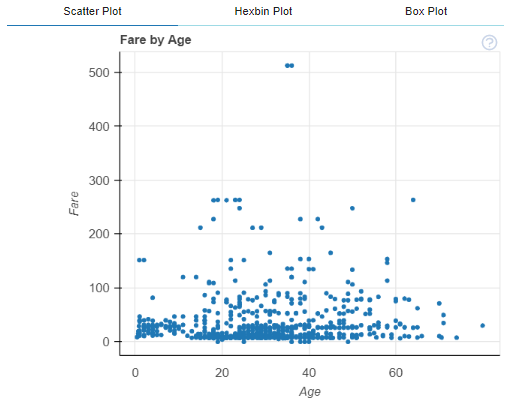
2. カラムA2とB2の関係
#@title 比較したいカラム番号を指定してください(カラム番号は 0~です)
Column_Number_A2 = 5#@param{type:"number"}
Column_Number_B2 = 4#@param{type:"number"}
#plot(df, "x", "y") ← x, y を指定
print('↓指定カラム A2, B2↓')
df.columns[Column_Number_A2],df.columns[Column_Number_B2]
#@title カラム同士の関係
#plot(df, "x", "y") ← x, y を指定
plot(df, df.columns[Column_Number_A2], df.columns[Column_Number_B2])
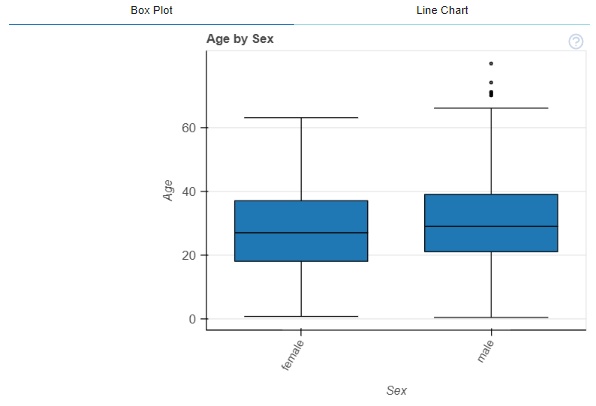
3. カラムA3とB3の関係
#@title 比較したいカラム番号を指定してください(カラム番号は 0~です)
Column_Number_A3 = 4#@param{type:"number"}
Column_Number_B3 = 1#@param{type:"number"}
#plot(df, "x", "y") ← x, y を指定
print('↓指定カラム A3, B3↓')
df.columns[Column_Number_A3],df.columns[Column_Number_B3]
#@title カラム同士の関係
#plot(df, "x", "y") ← x, y を指定
plot(df, df.columns[Column_Number_A3], df.columns[Column_Number_B3])
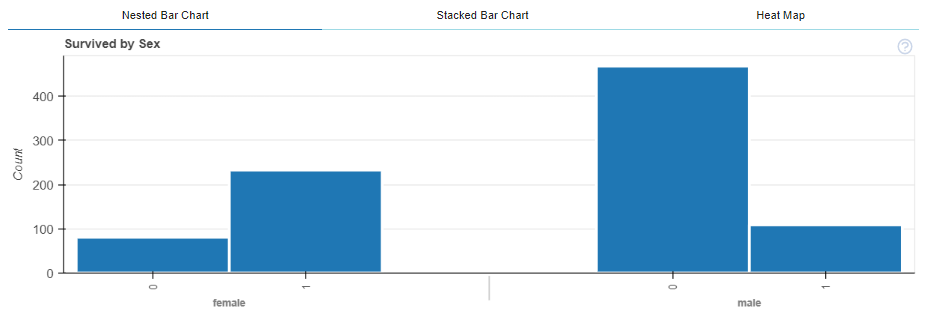
0/1の目的変数を0と1で区分し、説明変数毎で比較
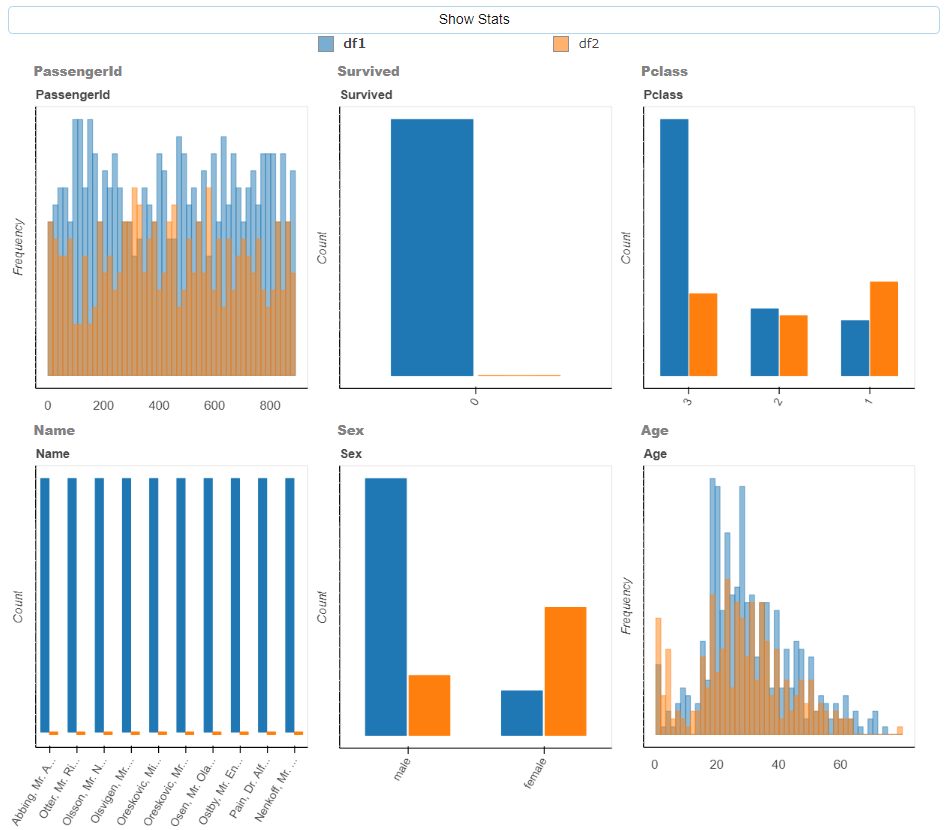
plot_diff()関数は、0/1の目的変数を0と1で区分し、説明変数毎で比較するような場合に、データフレームを目的変数 0と1のデータに分割し、説明変数毎の分布や統計量の違いを調べることができます。複数のデータセットにまたがる場合も同様です。
#@title データカラムを確認しましょう
df.info()
#@title 0/1でデータ区分したい目的変数カラムを指定してください(カラム番号は 0~です) { run: "auto" }
Diff_column_Number = 1 #@param{type:"number"}
print('↓指定カラム↓')
df.columns[Diff_column_Number]
#@title 0/1区分 可視化
df1 = df[df[df.columns[Diff_column_Number]] == 0]
df2 = df[df[df.columns[Diff_column_Number]] == 1]
plot_diff([df1, df2])
【参考】地理的データ分析
country = load_dataset("countries")
plot(country, "Country")
最後に
とにかく速い。
まったくストレスを感じないし、インタラクティブでとてもいい。
私は、これまで試した Auto-EDAのなかで DataPrep が一番のお気に入り。、
関連記事
参考サイト