今回は同じ内容のスクレイピングを__Python__と__Ruby__両方でやってみた記事です。
レベルとしては簡単な内容となります。
スクレイピング自体は色んな言語でできると思うのですが、__Python__は機械学習系ではスタンダートですし、一方__Rails__プロジェクトの中のクローリング処理実装したい場合はNokogiriを使うハメなるのでPythonとRubyのどちらでもスクレイピングの実装ができるようになりたいなあと思っています。
今回の目標はこちらのサイトのメガ進化含めた807匹のポケモン種族値表をスクレイピングしてcsvファイルに出力しExcelで閲覧できるようにすることです。
https://yakkun.com/sm/status_list.htm
使用するライブラリ
| Python | Ruby | |
|---|---|---|
| html取得 | urllib | open-uri |
| html解析 | BeautifulSoup | Nokogiri |
| csv出力 | pandas | csv |
基本的にスクレイピングではリクエスト処理をしてhtmlを取得するライブラリとそれを解析するライブラリを使用することになります。
htmlの取得は、Pythonではrequestsなども使えますが今回は標準ライブラリのurllibを使用します。ちなみにスクレイピングの解説記事などでurllib2を使ったものをよく見かけますが、Python3ではurllib2はurllibに名称変更されているので注意してください。
まずPythonでやってみる
ライブラリのインストール(もししてなければ)
pip install bs4
pip install pandas
# Anaconda環境なら
conda install bs4
conda install pandas
実装
# ライブラリのインポート
import urllib.request as req
from bs4 import BeautifulSoup as bs
import pandas as pd
url ="https://yakkun.com/sm/status_list.htm"
# urlにアクセスしてhtmlを取得
html = req.urlopen(url)
# htmlをparseする
soup = bs(html, "html.parser")
ここでchromeのデベロッパーツールなどで取得したいhtmlの構造を確認すると
table要素の中にthead要素とtbody要素がありそれぞれ、thead>tr>th, tbody>tr>tdという親子孫構造になっているのがわかると思います。こんな時はselectメソッドで楽に取れます。
# 親要素に thead>tr を持つth要素を取得したリストを返す
thead = soup.select("thead tr th")
# タグ内の文字列を取り出してリストに追加
headers = []
for h in thead:
headers.append(h.text)
# 親要素にtbodyを持つtr要素を取得
rows = soup.select("tbody tr")
pokemons = []
for row in rows:
pokemon = []
for r in row:
pokemon.append(r.text)
pokemons.append(pokemon)
# データフレームを作成
df = pd.DataFrame(pokemons, columns=headers)
実行環境でjupyterを使用している場合、dfを出力するとこのようになります。
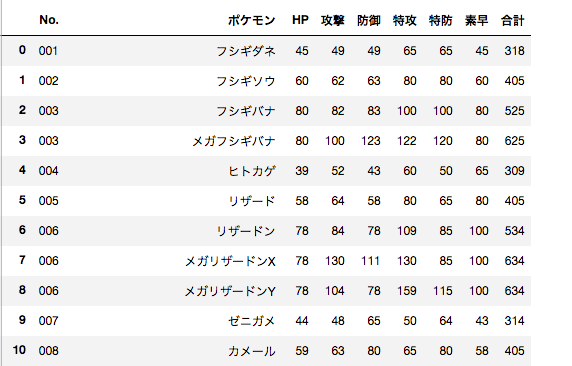
あとはこれをcsvにしてexcelで見れるようにするだけです。
文字コードがutf-8だとexcelで文字化けするのでshift-jisに変換しています。
また一番左列のインデックスもいらないので index=False を引数に追加して非表示にしています。
df.to_csv("pokemon_list.csv", encoding="shift-jis", index=False)
これで同じディレクトリ内にpokemon_list.csvが作成されるので, excelで文字化けせずに閲覧できるでしょう。
次にRubyでやってみる
pythonの場合と流れはおんなじです。コードの感じも結構似てますね。
htmlパーサーはNokogiriですが、BeatutifulSoupのselectメソッドと似ているxpathメソッド使用して、親子関係の子要素を取得することができます。
またxpathメソッドで取得したオブジェクトはNodeSetと呼ばれるリスト型配列ですが、挙動が普通の配列とは異なるので慣れが必要そう。
ライブラリのインストール
gem install nokogiri
# ライブラリのインポート
require 'nokogiri'
require 'open-uri'
require 'csv'
url = 'https://yakkun.com/sm/status_list.htm'
# open-uriでhtmlを取得し、結果を直接Nokogiriに渡している
doc = Nokogiri::HTML(open(url))
thead = doc.xpath('//thead/tr/th')
headers = []
thead.each do |h|
headers << h.text
end
rows = doc.xpath('//tbody/tr')
pokemons = []
rows.each do |row|
pokemon = []
row.xpath('td').each do |r|
pokemon << r.text
end
pokemons << pokemon
end
# csv出力
CSV.open("pokemon_list.csv", "w", :encoding => "SJIS") do |csv|
csv << headers
pokemons.each do |pokemon|
csv << pokemon
end
end
これでOK
最後に
個人的には直感的に書ける感じと厨二っぽい名前のライブラリが多いことからRubyが好きなんですが、pandasで二次元データを色々ブン回せる強みを考えるとPython強いですね。
またBeautifulSoup, Nokogiriどちらも結構メソッドあるので勉強することはたくさんありそうです。