League of Legends(以下、LoL)のAPIデータにおいて、
ランク戦で試合時間20分以下の試合情報に、
ロールに奇妙なデータが設定されやすいことが分かった。
ランク戦では各プレイヤーがロールを決めたうえで使用するチャンピオンを決める。
だが、以下のURLによると各プレイヤーがどの場所で
CSやキルを取ったかの情報がAPIに反映されるそうだ。
https://discussion.developer.riotgames.com/questions/959/getting-role-of-players-in-a-match.html?childToView=981
普通、adcとsupでDUOで組むがjgとsupがduoでロームすると
APIではjgとsupがDUOと認識され、adcがソロとして認識されるかもしれない。
そこで、ロールやレーンと各チャンピオンの関係について
チャレンジャーとマスターの試合情報をAPIから取得し、分析した。
分析内容
ロール、レーンとチャンピオンに関係はあるか?
関係が見つかれば、機械学習につながる
結果
更なる分析が必要だが、試合時間20分以下ではロールで異常データの混入が頻発した。
試合時間20分超では、ほとんど見当たらなかった。
分析方法
- チャレンジャー、マスターのサモナーデータをAPIで取得
- 1を基に、各サモナーのアカウントIDを取得
- 2を基に、直近のランク戦のゲームIDを取得
3を基に、ランク戦の試合情報を取得し、JSONとしてローカルに落とす
※1-4については以下URLを参照
https://github.com/curogihu/LoLAnalysis/tree/master/python/collectInformation
getALLInfo.py, utility.py以下のコードで試合時間20分以下のデータを取得し、分析する。
import json
import os
import glob
json_files_path = glob.glob(os.path.join("C:", os.sep, "output", "game", "info", "*.json"))
output_csv_file_path = os.path.join("C:", os.sep, "output", "edit", "info", "less_then_20mins.csv")
# しばらく決め打ち
SMITE_SPELL_ID = 11
SOLO_DUO_Q = 420
TWENTY_MINUTE_SECONDS = 1200
with open(output_csv_file_path, 'w') as csv_f:
tmp = ""
for i in range(5):
tmp += ",championId{0},role{0},lane{0},haveSmite{0},haveSupportItem{0}".format(i)
# 項目名の出力
csv_f.write(tmp[1:])
csv_f.write("\n")
# 1試合づつ読み込み
for json_file_path in json_files_path:
game_id, ext = os.path.splitext(os.path.basename(json_file_path))
with open(json_file_path, 'r') as f:
json_data = json.load(f)
# ランク戦のみ取り込んでいるはずが、チュートリアルのデータも入ってる
# 不要なので、読み飛ばす
if json_data['queueId'] != SOLO_DUO_Q:
# print("{0} is skipped".format(game_id))
continue
# 試合時間20分超のデータは扱わない
if json_data['gameDuration'] > TWENTY_MINUTE_SECONDS:
continue
print(game_id, json_data['gameDuration'])
participants = json_data['participants']
participants_of_match = {}
cnt = 0
for participant in participants:
# print(participant["participantId"])
# tmp_participant = OrderedDict()
tmp_participant = {}
tmp_participant['participantId'] = participant["participantId"]
tmp_participant['championId'] = participant["championId"]
tmp_participant['role'] = participant["timeline"]["role"]
tmp_participant['lane'] = participant["timeline"]["lane"]
if participant["spell1Id"] == SMITE_SPELL_ID or participant["spell2Id"] == SMITE_SPELL_ID:
tmp_participant["smite"] = 1
else:
tmp_participant["smite"] = 0
participants_of_match[participant["participantId"]] = tmp_participant
tmp = ""
for i in range(0, 2):
# print(i)
# 1-5, 6-10と1チーム5人ずつ設定し、出力する
for x in range(i * 5 + 1, i * 5 + 6):
tmp += ',{championId},{role},{lane},{smite},{support_item}'.format(championId=participants_of_match[x]["championId"],
role=participants_of_match[x]["role"],
lane=participants_of_match[x]["lane"],
smite=participants_of_match[x]["smite"],
support_item="")
# 異常ケースを含むチームがあるかどうかのざっくり目視確認
# print(tmp)
csv_f.write(tmp[1:])
csv_f.write("\n")
tmp = ""
print("ended")
調査したところ、1チーム5人のはずなのに
5人全員のロールに"DUO_SUPPORT"の値が設定されているケースを確認した。
試合時間20分以下の試合に参加した3004チームの分析結果
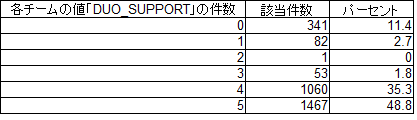
1チームにDUO_SUPPORTを4,5件ある割合は約84%ある。
さらに0件を含むと、約95%になる。
なお、DUO_SUPPORTの件数1件の割合は全体の2.7%しかなかった。
次に、試合時間が20分超のデータを以下のコードで取得し、分析した。
# 変更部分
# if json_data['gameDuration'] > TWENTY_MINUTE_SECONDS:
# → if json_data['gameDuration'] <= TWENTY_MINUTE_SECONDS:
import json
import os
import glob
json_files_path = glob.glob(os.path.join("C:", os.sep, "output", "game", "info", "*.json"))
output_csv_file_path = os.path.join("C:", os.sep, "output", "edit", "info", "less_then_20mins.csv")
# しばらく決め打ち
SMITE_SPELL_ID = 11
SOLO_DUO_Q = 420
TWENTY_MINUTE_SECONDS = 1200
with open(output_csv_file_path, 'w') as csv_f:
tmp = ""
for i in range(5):
tmp += ",championId{0},role{0},lane{0},haveSmite{0},haveSupportItem{0}".format(i)
# 項目名の出力
csv_f.write(tmp[1:])
csv_f.write("\n")
# 1試合づつ読み込み
for json_file_path in json_files_path:
game_id, ext = os.path.splitext(os.path.basename(json_file_path))
with open(json_file_path, 'r') as f:
json_data = json.load(f)
# ランク戦のみ取り込んでいるはずが、チュートリアルのデータも入ってる
# 不要なので、読み飛ばす
if json_data['queueId'] != SOLO_DUO_Q:
# print("{0} is skipped".format(game_id))
continue
# 試合時間20分以下のデータは扱わない
if json_data['gameDuration'] <= TWENTY_MINUTE_SECONDS:
continue
print(game_id, json_data['gameDuration'])
participants = json_data['participants']
participants_of_match = {}
cnt = 0
for participant in participants:
# print(participant["participantId"])
# tmp_participant = OrderedDict()
tmp_participant = {}
tmp_participant['participantId'] = participant["participantId"]
tmp_participant['championId'] = participant["championId"]
tmp_participant['role'] = participant["timeline"]["role"]
tmp_participant['lane'] = participant["timeline"]["lane"]
if participant["spell1Id"] == SMITE_SPELL_ID or participant["spell2Id"] == SMITE_SPELL_ID:
tmp_participant["smite"] = 1
else:
tmp_participant["smite"] = 0
participants_of_match[participant["participantId"]] = tmp_participant
tmp = ""
for i in range(0, 2):
# print(i)
# 1-5, 6-10と1チーム5人ずつ設定し、出力する
for x in range(i * 5 + 1, i * 5 + 6):
tmp += ',{championId},{role},{lane},{smite},{support_item}'.format(championId=participants_of_match[x]["championId"],
role=participants_of_match[x]["role"],
lane=participants_of_match[x]["lane"],
smite=participants_of_match[x]["smite"],
support_item="")
# 異常ケースを含むチームがあるかどうかのざっくり目視確認
# print(tmp)
csv_f.write(tmp[1:])
csv_f.write("\n")
tmp = ""
print("ended")
試合時間20分超の試合に参加した17206チームの分析結果

DUO_SUPPORTの件数1件の割合は全体の93.6%と多く、さらなる調査のしがいがある。
試合時間20分以下のケースにあった、DUO_SUPPORT件数4,5件の割合は全体の0.1%しかなかった。