まえがき
今の仕事でメディアデバイスのコントローラを作っていることもあり、「上位レイヤにあたるファイルシステムの理解を深めたいなぁ」と社内勉強会を開催したりしていたので、ちょっとアレンジして外向けに公開しようと思いました。
前々からOSレイヤの勉強を進めるにあたって、ユーザビリティに影響の大きな3大コンポーネント メモリ管理、プロセススケジューラ、ファイルシステムの内、ファイルシステムだけパッとイメージしにくい雰囲気を個人的に感じていました。メモリ管理はその名の通りメモリを管理する、プロセススケジューラはプロセスの処理順序をスケジューリングする、**ファイルシステムは・・・・何をやってるんでしょう?**って感じです。 ファイルやディレクトリが見えているのはファイルシステムのおかげというのはなんとなく理解出来るんですけどね。
色々と手当たり次第に本を読んでみたのですが、自分の疑問に対して一番明確な解答になってくれたのは @tkato に教えていただいた Practical File System Design with the Be File System (PDF) でした。どうやら Amazon でもペーパーバック/Kindle版で売っているようです。
Be File System は BeOS (Wikipedia やこちらの記事参照) に載ってたファイルシステムであり、この本の出版は多少古い (ストレージがHDDであることが前提だったりする) ものの Be File System に特化しすぎる内容ではなくファイルシステムを構成する上で一般的に必要な概念や仕組みを解説してくれているので非常に勉強になりました。
というわけで、この Practical File System Design の中身に沿って進めている勉強会の初回の内容を本記事の内容として公開します。本の該当箇所は Chapter 2 "What Is a File System?" となっています。勉強会資料は私個人の見解も含まれてますので、正確な情報を得るには原文をご参照ください。
ファイルシステムの存在しない世界
ここは導入部分であり、本には存在していない内容です。
とある日常風景
とあるストレージがやってきました。Read/WriteするAPIは存在するものとします。
とりあえず使ってみる。
誰かに見つかって・・・
上書きされます。
もちろん、前に書いた人は期待するデータが読めません。
怒ります。
激オコです。
どうすればよかったか?
みなさんお気づきだと思いますが、こんな問題を起こさないためにはストレージを管理できてればよかったですね。例えば以下のような仕組みがあれば良いのではと。
- 使用領域を記録する (どのユーザがどのブロックを使ったか、等)
- 上書き・削除しようとしたら警告を出す
- 書き込み要求に対して空きブロックを提示する
-
アクセスする権利が用意されている→ データに対するアクセスが適切に制御されている1 - etc.
新しいストレージが用意されるたび、さらに、新しいユーザが操作するたびに人間の手でこれらの管理作業をやってたら大変です。その作業をやってくれるのがファイルシステムということになります。
ファイルシステムとは何か?
改めて掲題の疑問に戻ります。
本の 2.1 The Fundamentals に書いてある通り、コンピュータは基本的にデータを生成・処理・蓄積・検索する目的で使われるものですが ファイルシステムはこれらをサポートするための仕組みとなります。具体的には以下3つの役割に集約される機能を担っていると考えられます。
- 永続ストレージを管理する
- 永続ストレージに保存されているデータをOS/ユーザに抽象オブジェクトとして見せる (File, Directory, or etc.)
- 抽象オブジェクトに対する操作 (API) を定義・提供する
ファイルシステムの種類
Wikipedia "Comparison of file systems" より
2019/02/10 時点の Comparison of file systems を見ると、以下の通り1964年のDECtapeから2017年のNOVAまでの53年間で98種類ものファイルシステムが並んでいます。この中には掲載されていないものも多数存在します。例えば、フラッシュメモリ向けのファイルシステム (JFFS, JFFS2, YAFFS, UBIFS, LogFS) やテープ装置向けの Linear Tape File System (LTFS)、京コンピュータで使われている FEFS などです。研究用途で開発されていた(いる)ものも含めると恐らく200種類は超えるでしょう。
1996年の Be File System に色を付けてみましたが、それ以降も相変わらず年に2,3個開発され続けているのは凄いですね。近年、フラッシュメモリ向けにApple社が開発した Apple File System (APFS) や the University of California, San Diego がオープンに開発している NOVA が出てきたことから考えると、まだまだ NVM 用ファイルシステムは出てくるんじゃないかなと思います。一昔前の F2FS から派生した OrcFS というのも開発されてますし、期待が高まります。

最強のファイルシステムは?
2.1 The Fundamentals
... There is no “correct” way to write a file system. In deciding what type
of filing system is appropriate for a particular operating system, we must
weigh the needs of the problem with the other constraints of the project.
上記の通り、特定用途に適するファイルシステムは存在しても「正しい」ものは存在しません。逆にいうとファイルシステムを選択・開発するときは、どんな目的でどのように使うかハッキリとした目標を定めておく必要があるということになります。どんなファイルシステムでも苦手なアクセスパターンでRead/Writeされれば性能は落ちますので、必要となる要件や機能を選定しないといけません。
もちろん、システムやデバイス側が進歩してファイルシステム処理がボトルネックになった場合などはファイルシステムも進化していく必要があり、時代の要求に応じて様々な開発が行われているので、新しい方が良い場合は多いです。HDDが前提であった頃と比較してコンシューマ向けSSDが普及し、3D XPoint などのNVMが出てきた現代で新しい仕組みのファイルシステムが必要となってきている理由も明白な気がします。
ファイルシステムの技術用語
次は、どんなファイルシステムにおいても共通して使用される概念を含めた技術用語について説明します。基本的に本の 2.2 The Terminology に基づいてます。
共通しているといっても各ファイルシステムにおいて微妙に定義が異なっていたりするので、それぞれの仕様・定義をよく確認していただきたいです。さらに、新しい概念も出てくるかと思いますが (ZFS のストレージプール等)、ここに挙げる用語を理解しておけば何のことを指している概念なんだなというのがスッと頭に入るようになると思います。
Disk
- あるサイズを持った永続ストレージメディア
-
セクタサイズ or ブロックサイズ を持っている
- Disk への Write/Read の最小単位
- ほとんどの HDD は 512 Byte (だった)
- 今となれば 4 KiB も浸透してきたか?
Block
- Disk や File System の書き込み可能最小単位
- File System の操作は全て Block に対する操作により構成
-
Block サイズ
- 「File System Block サイズ」 = 「Disk Block サイズ」 or 「Disk Block サイズ の整数倍」
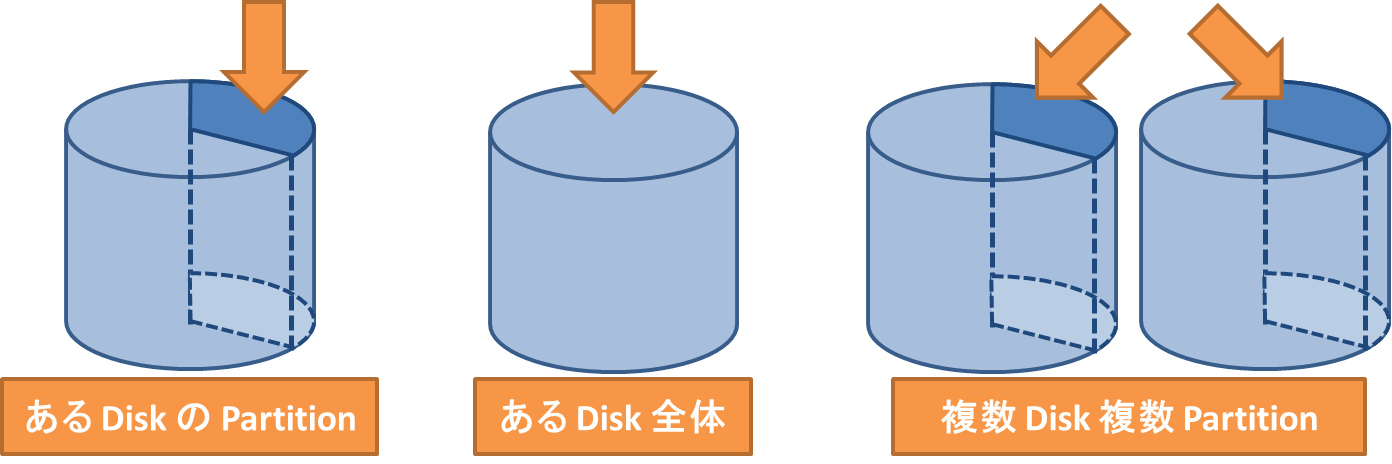
Partition
- ある Disk における全 Block の部分集合
- Disk は複数の Partition を持つことができる
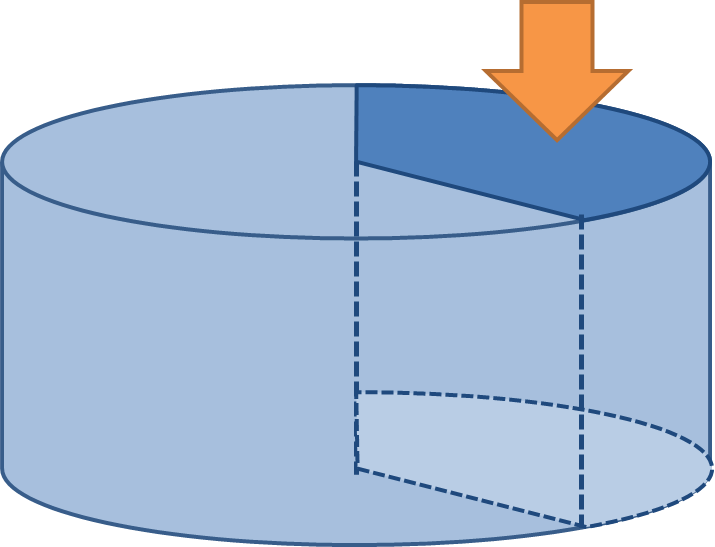
Volume
- いくつかのストレージメディアにまたがる複数 Block をひとまとめにしたもの
- ある File System で初期化した Disk や Partition のこと を指す場合が多い
Superblock
- Volume 全体の重大な情報を蓄えている Volume の一部領域
-
Superblock に含まれる情報
- Volume 名
- Volume サイズ
- etc.
Metadata
- 一言でいうとData about Data
- 例
- 「ファイルサイズ」 != 「ファイルの中身」
Journaling
電源遮断や予期せぬリブートが発生しても、File System の Metadata の正しさを保証するための方法の一つ。
I-node
- File System がある File について必要となる全ての Metadata 情報を蓄えておく場所
- File の中身と、その File に関連するあらゆる他のデータの結び付きを提供
- i-node という単語は歴史的に UNIX 起源
- またの名を File Control Block (FCB) or File Record
Extent
- Disk 上の開始 Block 番号と連続 Block 長をひとまとめにしたもの
- またの名を Block Runs
Attribute
- いわゆる属性
- ある名前 (文字列) とその名前に関連付けられた値
- 型が定義された値 or 単なる任意のデータ
抽象オブジェクト
続いて本の 2.3 The Abstructions から、あらゆる File System の基礎となる File と Directory について説明します。
この節のタイトルにも中身にも Object という単語は一切入っていないのですが、個人的に File や Directory は「抽象化されたオブジェクトと考える方がしっくりくる」という意識からあえて付けるようにしています。
File
File とは
File System は「名前を付けたデータ片を保存し、後からそのデータ片に与えた名前を使ってデータを取り出すための方法を提供」しています。この名前を付けたデータ片こそが File を表すものです。さらに File の特徴として以下のようなものが挙げられるでしょう。
- File は、ユーザが永続的に保存しておきたいあらゆるバイト列の集合である
- File サイズは数バイト ~ Volume全体に及ぶ
- File 数は ~数百万程度
- というのは本出版当時のことで、近年のファイルシステムなら上限はもっと上
- 作成可能な i-node 数に依存する場合がほとんど
File の構造
File System が File に構造を持たせるか否かについてはどちらでも良いです。ここで言う構造というのは、とある拡張子で判別されるファイルのことではなく、そもそもデータをどうやって管理するかというお話。構造の有り無しなので、大きく分けて以下の2パターンに分かれます。
-
非構造型
- こちらの方が一般的
- プログラムが希望する通りのあらゆる順序でRead可能
- I/Oリクエスト、アラインメントサイズは気にしなくて良い
-
構造型
- Record という概念を持つ
- 特定の Record サイズとフォーマットが存在する
- 全てのI/OがRecord単位 (Recordの整数倍)
- メインフレームなどで使用される
- 構造化手法 → 一般的でないためここでは扱わないが以下のような手法がある
- VSAM (virtual sequential access method)
- ISAM (indexed sequential access method)
- 構造化手法 → 一般的でないためここでは扱わないが以下のような手法がある
また、構造の有り無しに関わらず、ユーザは File への名前付けが可能であり、File の検索キーとして利用されます。昔は、少なくとも32文字長の名前付けが可能だったようです。組み込みシステムの場合、ファイル名の長さにさらに制限が課せられる場合もあります。
File の Metadata と Data
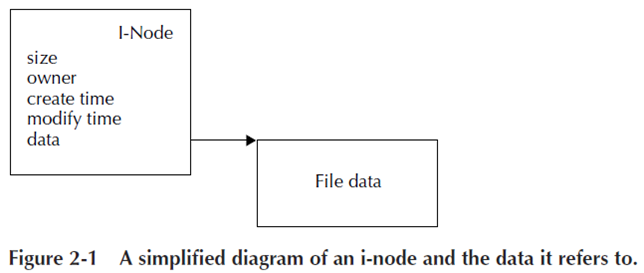
技術用語で説明したように Metadata 情報は i-node に保存されています。Metadata として格納される情報としては File System によって異なりますが、一般的にファイル名、ファイルサイズ、所有者、アクセス権、作成・修正日付などがあり、最も重要な Metadata 情報はファイルデータの保存先となります。
本から図を持ってくるとこんな感じのイメージ (Figure 2-1) です。I-node からファイルのデータが参照できるようになっています。
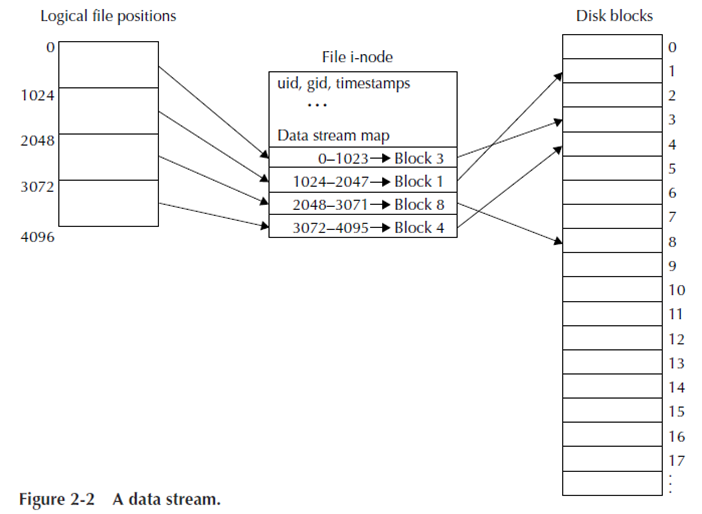
実際に File と中身のデータがどのような対応関係にあればよいかを表したものが以下の図 (Figure 2-2) となります。ファイルサイズが 4KiB、Disk の Block サイズが 1KiB と考えてください。ファイルサイズからデータを保存するのに4つの Block が必要であり、I-node ではその4つ分の Block アドレス (物理アドレス) とファイルオフセット位置 (論理アドレス) がマッピングされています。論理的に1つのファイルは連続していますが、それを構成するデータの物理アドレスは連続になっていなくても構いません。
Block マッピング方法
上記の Figure 2-2 では i-node に File に対応する Block への参照情報がリスト上になっていましたが、実際には i-node 自体のサイズにも限度があるためファイルデータの参照情報の持ち方を考えなければなりません。
I-node も Disk に格納される情報なので2のべき乗のサイズが扱いやすく、サイズと格納可能なアドレス数はトレードオフの関係にあり、単純リストで管理していると扱えるアドレス範囲が小さくなってしまう。これらの問題の解決策の一つが Indirect Block です。
-
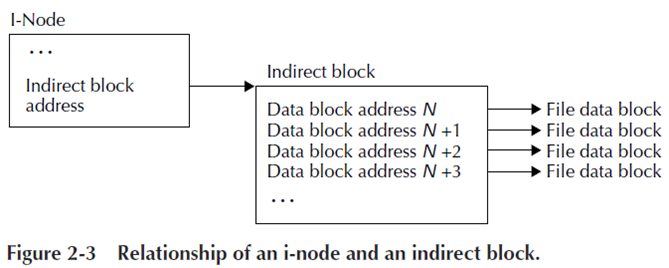
Indirect Block
イメージ図を Figure 2-3 に示します。I-node から Indirect Block への参照があり、その中に Data Block への参照情報がファイルのオフセット順に並んでいます。いわゆる Block への間接参照です。
Indirect Block のサイズをそのまま File System Block サイズとすると管理が楽ですね。例えば、File System Block サイズが 1KiB, Data Block Address が 64bit (=8Byte) アドレスとすると1つの Indirect Block には最大128個の Block への参照情報が登録できます。
ただし、良く考えてみると図の File data block のサイズも File System Block サイズと等しいので、たかだか 128個 × 1KiB = 128KiB のファイルサイズまでしか扱えないことになります。今時ファイルサイズがMiBもいかないのはちょっとね・・・ということで、さらに改善が必要となります。
-
Double-indirect Block
次なる改善策は Indirect Block を2段で使う Double-indirect Block です。イメージ図は適当に作ってみました。この仕組みだと参照が2段なので先ほどと同じ前提とすると、128 × 128 × 1KiB = 16MiB まで扱えるファイルサイズが拡張されます。
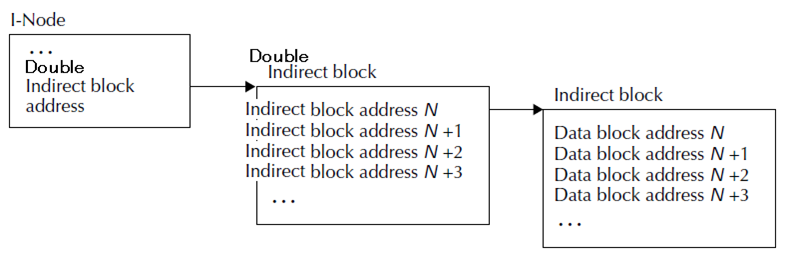
しかし、まだまだファイルサイズとしては小さいのでもっと大きなサイズを扱えるようにしたくなるのは当然です。Dobule があるなら Triple もということで、単純に間接参照を多段にしていけばファイルサイズの拡張は (論理的に) 簡単なのですが 本にはほとんどの場合 Double で十分と書かれています。理由は File System Block が 4KiB で Data Block Address が 4Byte とすると、Double/Indirect Block に入る参照情報の個数は1024個となるので、1024 × 1024 × 4KiB = 4GiB サイズのファイルが扱えるようになるから、というもの。
この見解は1980年台後半の当時のHWを考えると妥当かもしれませんが、さすがに現代でTiB級のストレージを個人で持っており数GiBの動画ファイルをガンガン保存するし、そこそこの並列システムでも1ファイルで数百TiBのやつも存在するなんて想像できなかったんでしょう。Data Block が 4Byte アドレッシングの場合、2^32 * 4KiB = 16TiB ですからストレージのサイズとしても個人PCで結構厳しくなってくる状況に思えます。というわけで、どういう制限を付けて実装するかがポイントになりそうです。 -
Extent を使う場合
さて、技術用語で定義した Extent を使っても Block マッピングは可能です。Indirect Block と合わせて利用すると以下のようなイメージとなります。Indirect Block に詰まっているのは Extent 情報となり、Extent のサイズも上手いこと2のべき乗にしてやるとキレイに収納できます。例えば、Data Block Address が 8Byte の場合、6Byte Address + 2Byte length とすれば128個の Extent データが入ります。図の Xn が連続するブロック長を示しています。
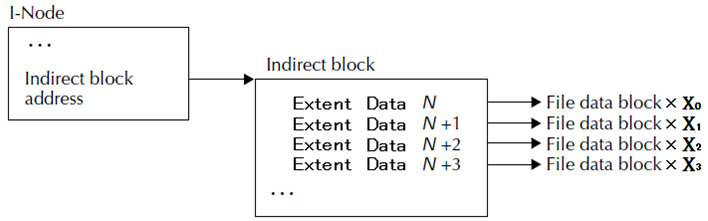
連続している Block を表現するには便利な Extent ですが、Indirect Block と比べて不利な点があります。それは、ファイル位置検索です。1つの Extent がマッピングするアドレスサイズが可変であるため、ある位置を特定するには毎回先頭アドレスからマッピングしているサイズを計算し、目的位置を算出する必要があります。これと比較して Indirect Block 方式では登録された有効な参照情報さえ分かれば簡単に計算できます。
上記では Block マッピング方法を別々に説明しましたが、それぞれメリット・デメリットがあり複数の方法を組み合わせて表現することもあります。その分管理が複雑になりますが、様々なファイルアクセスに対して性能を出すには色々戦略が必要なので、既存のファイルシステムでも直接参照・間接参照の両方を持つ i-node を備えている場合が多いようです。
Directory
Directory とは
File がたくさん増えてくると複数の File をひとまとめに名前付けをして管理したくなってきます。これを実現する抽象オブジェクトこそ Directory または Folder です。以下では、呼び方を Directory に統一して説明します。
ひとまず Directory の中身の概念図 (Figure 2-4)を見てみましょう。

非常に単純化された図ですが重要なのは、Directory が名前のリストを持っている、かつ、その名前に対応する i-node 番号を参照できるということです。この Directory に保存される名前と i-node 番号の1つの組を Directory Entry と呼ぶことにすると「ある Directory には0個以上の Directory Entry が存在する」ということになります。
上記であえて「File の名前のリスト」と言わずに「名前のリスト」と表現したのは、Directory Entry の名前に別の Directory の名前を入れても良いからです。後で Directory 階層構造についても説明しますが、今みなさん使っている File System で Directory が入れ子にできないものなんてないですよね。
また、Directory のデータも Disk に保存しておく必要があるため、Directory 情報をまとめた Metadata が File と同様に必要となります。この Directory の Metadata を i-node で表現すれば、File と全く同じように Directory の名前と対応する i-node 番号の組を Directory Entry として扱えます。
というわけで、File または Directory を探すには名前をキーとして検索でき、その名前に対応する i-node が分かれば Metadata・実データにアクセス可能という仕組みが出来上がりました。
Directory Entries の保存方法
Directory Entry をどのように保存したら良いでしょうか?一般的な要求としては効率的に検索可能で、適切な処理時間で挿入・削除が可能であることとなります。
Directory Entry 数が少なければソートあり or なしの単純リストで十分かも知れません。しかし、挿入・検索・削除の内、かならず処理時間が O(N) となってしまう操作がでてきてしまい、数が増えた場合は悪影響が出てきます。
どの操作も適切な処理時間でということになるとやはり木構造が使う必要が出てきて、とりわけ File System における Directry Entry の管理は B-tree (もしくは、亜種の B+ Tree や B* Tree も) が選択されているようです。B-tree であれば、数に対してスケールすることも可能です。
さらに、File System 開発者が検討しなければならないポリシーとして、File / Directory の名前の最大長や使用可能な文字セット、文字エンコーディング、ファイルパスのセパレータ等々盛りだくさんです。なかなか大変ですね。
階層構造
たった1つの Directory に全ての File を突っ込むのは小さな組み込み・スタンドアロンでは可能かもしれませんが、それ以外のシステムでは現実的ではありません。人やマシンにとって最も自然な方法で File / Directory を管理する必要があり、その方法の一つが階層構造です (Figure 2-5)。
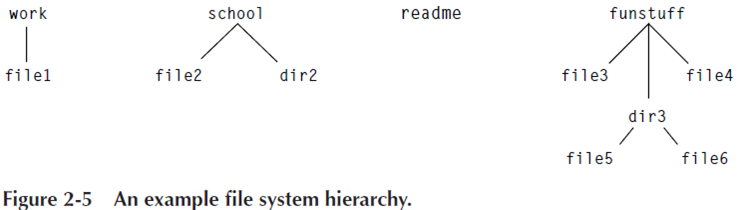
階層構造を実現するには、既に述べたとおり Directory のエントリに別の Directory への参照を含む、というのが最も単純な方法です。これにより、論理的にはサイズ・深さは無制限で任意の階層構造を構築可能となります。構築する File System によっては2段の階層があれば十分である場合も多々あるかと思いますが、要求をよくよく検討する必要があります。
検討課題
より柔軟な設計をしてあげることで、ユーザがデータを参照しやすくすることもできます。例えば、プログラマが複数のプロジェクトを抱えており、そのプロジェクト名を付けたディレクトリには複数のサブディレクトリがあったとします。管理する情報はどのプロジェクトでも似たり寄ったりなので、ソースコード用ディレクトリやドキュメント用ディレクトリ等に分かれていることでしょう。
ある時、プロジェクト横断して全ファイル中からソースファイルを検索したいとすると、単純にディレクトリ階層構造を順番に確認していくしか方法がないとしたら非常に時間がかかってしまいます。ソースコードであろうがドキュメントであろうが、ユーザがリクエストするファイルを階層構造に関わりなく検索しやすいシステムが求められます。
File System Operations
File と Directory という2つの抽象オブジェクトの説明が終わり、後はこれらをどのように操作するかということになりますが、非常に細かくなってくるので説明は割愛させていただき、詳細については本を参照していただきたいと思います。
以下で挙げる File System が提供すべき操作は、User レベル API と同等というわけではありません。例えば、ls コマンドを使って引数の Directory に含まれる File の作成時刻一覧を見たいとしても、File System が提供しているのはその情報を取り出すのに必要なプリミティブAPIであり、それを ls コマンドがシステムコールを駆使して利用しているにすぎません ls コマンドがこれらのAPIをシステムコール経由で駆使することで必要な情報を収集・表示しています2。なので、良く使用するコマンドも操作を分解していけば File System としてはこんな動作をしてるんだろうな、ということを想像しながら眺めていると理解できると思います。
Basic Operations
基本的な操作を一覧にすると以下の通りです。文字だけ見ても何となくどんな処理なのかは想像できるかと思います。
- Initialization
- Mounting / Unmounting
- Creating Files
- Creating Directories
- Opening Files
- Writing to Files
- Reading Files
- Deleting Files
- Renaming Files
- Reading Metadata
- Writing Metadata
- Opening Directories
- Reading Directories
中でもちょっと分かりづらい Initialization と Mounting / Unmounting について簡単に説明すると、Initialization はある Volume を特定の File System で使える状態にすること (Superblock や root directory が作られる)、Mounting は使える状態にした Volume にユーザがアクセスできる準備をすること、Unmounting は逆にアクセスできないようにすること、ですかね。
気を付けないといけないのは Mount できたからと言ってその Volume が健全であるとは限らないことです。不正電源遮断 (急な reboot) などでデータ破壊が起きている可能性はあるので、それらを File System として保護する仕組みを用意するか、リスクが低いので何も対策をしないかのどちらかを選択するか考えなければなりません。
Extended Operations
以下の操作一覧はより便利な扱いができるようになるための拡張です。
- Symbolic Links
- Hard Links
- Dynamic Links
- Memory Mapping of Files
- Attributes
- Indexing
- Journaling / Logging
- Guaranteed Bandwidth / Bandwidth Reservation
- Access Control Lists
ここも細かくは説明しませんが、上記の説明を理解していれば Symbolic Links や Hard Links は i-node を2つ用意して同じデータを指すようにすればよさそうだな、という想像もつきます どのように実現すれば良いか想像できるかもしれません3。実装するには色々と面倒ですが、じっくり考えてみるのも良いでしょう。
あとがき
非常に駆け足で File System とは何かということについて説明させていただきました。これを読んで「File System って意外と自分で作れそうだから実装してみよう!」と思っていただける人がいれば幸いです。
実装してみると色々と考える部分が沢山出てきます。i-node も何かをキーにして検索できるようにしなきゃ、とか Metadata と Data ってそれぞれどの (物理) アドレスに保存しておくのがいいんだろうとか、非常にサイズが小さい・大きいファイルを効率よく扱うにはどうするんだろう、等々。
Linux で File System を実装するなら仮想ファイルシステム (VFS) のインタフェースや、File System 層の下のレイヤにいるブロックデバイス層の挙動もある程度理解しておかないといけないので、ハードルは低くはないですが仕組み自体そんなに複雑ではないです。
性能を追求しないのであれば、特定のデバイスに Write/Read できただけで満足できる(?)ので是非実装もお試しください。次回は Log File System について調べた内容でもまとめようかと思います。