始めに🍵
突然ですが、皆様抹茶スイーツはお好きでしょうか?
神社仏閣を巡って御朱印を貰ったことはありますか?
私は抹茶スイーツと神社仏閣を巡るのが大好きで京都に住んでいるような変わり者です。
まあそんな特殊な人はあまりいないと思うのですが。
けれどそのどちらも普段は行わないだろう方も、折角京都に来たのならどっちか、
あわよくばどちらも巡りたいな〜と思ったりしないでしょうか?思いますよね?
抹茶スイーツ何選紹介記事とかはありますし、神社仏閣情報が豊富なサイトは勿論あります。
しかしそのどちらもが同時に載っているサービスは存在しないのです……
えっ。。何故。。絶対需要があるのに!
そうだないなら作ろう!私がユーザーだ!
というわけで今回作ったサービスが以下になります。
[サービスURL]
[GitHubのURL]
目次
| 章 | タイトル | 備考 |
|---|---|---|
| 始めに🍵 | ||
| 1 | サービス概要⛩ | 一瞬で読めます |
| 2 | サービスで出来ること🍡 | サービスの機能とかの紹介です |
| 3 | 苦労した点🍁 | 技術的な話がこちら |
| 4 | 主な使用技術📚 | |
| 5 | ER図🌸 | |
| 6 | 終わりに🌙 | |
| 7 | 参考文献📖 |
1サービス概要⛩
京都にある抹茶スイーツのお店の近くにある神社仏閣を調べたり、
京都にある神社仏閣近くの抹茶スイーツを調べたりすることができ、
現在地近くにある抹茶スイーツ店と神社仏閣を調べることができるサービスです。
スマホ・PC対応(※若干スマホ寄りのレイアウトです)

ちなみにアップデート情報とかはこちらの垢で告知しています!よければこちらも見てみてください!
2サービスで出来ること🍡
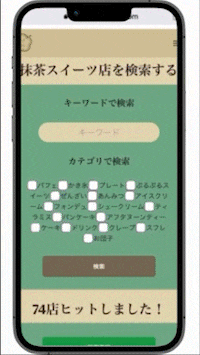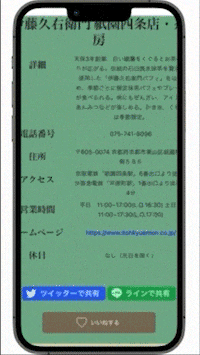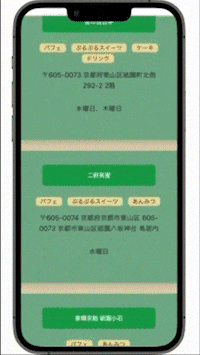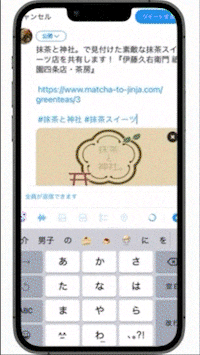
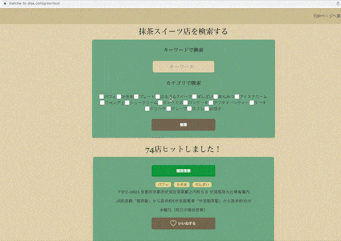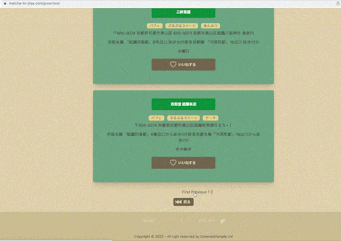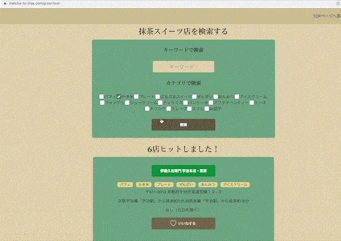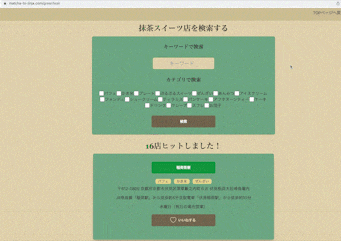
一. 抹茶スイーツと神社仏閣が検索できる
抹茶スイーツはキーワードとスイーツのカテゴリで、
神社仏閣はキーワードと地域で検索ができます。
一覧ページでは施設の名前、カテゴリ(地域)、住所、アクセス、定休日をわかるようにしており、
気になったら詳細ページに飛べるようになっています。
| 抹茶スイーツの検索 | 神社仏閣の検索 |
|---|---|
 |
 |
二. 詳細ページでは、それぞれの情報とその近くにある施設を見ることができる
抹茶スイーツ店・神社仏閣の詳細ページではそれぞれの情報と、
半径1.5km以内にある抹茶スイーツ店・神社仏閣を見ることができます。
またTwitterやLineで抹茶スイーツ店・神社仏閣を共有することもできます。
三.現在地検索で近くにある抹茶スイーツ店と神社仏閣を調べることができる
京都にいれば、現在地周りの抹茶スイーツ店と神社仏閣を見ることができます。
茶のアイコンが抹茶スイーツ店、神のアイコンが神社仏閣になっており、
吹き出しをクリックすると、詳細ページにアクセスすることができます。

四. ユーザーログインするといいね機能が使える
ユーザー登録することで「いいね機能」が利用可能になります。
登録&ログインは、Twitter・LINEの外部認証から選択できます。
※ログインして出来る機能は今後拡張予定です

3苦労した点🍁
一. Rails7のキャッチアップ
私はCSSフレームワークでTailwindCSSを使用したかったのですが、
Rails6ではwebpackerと仲良くなれなくて、うまく導入できず……
rails new時にCSSフレームワークを選ぶと一緒にセットアップしてくれるのが良すぎて、
軽い気持ちでRails7を選びました。これが修羅の道だとも気付かずに……
他人事みたいにファイッとか言うてる場合じゃないんだよ
注意
ちなみに皆さんご存知だとは思いますが、
Rails6でも普通にTailwindCSSを入れることは可能です。
私が諦めただけです。
Rails7はRails6と比べるとまず技術記事も少なくて……
ですがその中でも後々紹介する記事などに沢山お世話になりました。
まず紹介するのも今更感ありますが、Rails7を使用するならまずこの記事を読むのがおすすめです。
今回PFを作成していて細かいところで色々苦労したのですが、特にこの苦労したのが以下の3点です。
I. TailwindCSSコンポーネントライブラリ『daisyUI』の導入が中々できなかった
II. sass-rails Gemが使用されない為、rails-adminが使用できなかった
Ⅲ. Rails7からデフォルトになったHotwireに中々慣れなかった
I.TailwindCSS コンポーネントライブラリ『daisyUI』の導入が中々できなかった
TailwinsdCSSのメリットはCSSのクラス名を考える必要が一切ないとか、CSSを新たに書く必要がないとか、
色々あると思われます。
またReactやVueを使っている人で導入するCSSフレームワークに悩んでいる場合は、選択肢の一つとしてかなり有力らしいです。私はそこまでキャッチアップできていなかったので関係ないけど
ただ私の場合は、スクールで流行っているとかBootstrapは古いのか!?とかそういう打算的な意味で選びました。
その為最初からキャッチアップして全部コード書いていくとか絶対しんどい。
そんな時『daisyUI』というコンポーネントライブラリを教えてもらいました。
というかTailwindCSS自体がコンポーネント思考なのでそういうコンポーネントが沢山あるみたいです。
今回私がdaisyUIを選んだ理由は、シンプルに用意されている『retro』というテーマが、
私のサービスに合うと感じたからです。
京都のお店や神社を巡るサービスなので、和風にしたいと考えていましたが、私はデザインセンスが微妙なので、
最初からレトロな色を揃えてくれているこのコンポーネントはとてもハマっていました。
<%= link_to '抹茶スイーツで検索', greenteas_path, class: 'btn btn-wide btn-secondary', style: 'color: white' %>

わかりやすい短いコードで上のような柔らかい緑色のボタンが生成されるの絶対良い!
色の配色センスも問われないし!
とウキウキでインストールしようとしましたが、何故か反映されません……。
何故だ〜とネットで調べていたところ、同じスクール生の方の記事を見付けました。
もうドンピシャですね。
私はこの記事に巡り会うまで、この方も辿り着いている、
この質問サイトに辿り着いて途方にくれていたので、本当に助かりました。ありがとうございます。
後から考えると、daisyUIのインストールページに、
『Node.js と Taiwind CSSがインストールされている必要があります。』
と書いてあった為、脱Node.jsを掲げている、importmap-railsとはうまくいかなさそうだな……
と思い付けそうなものなんですけど、あの当時の私はひたすら沼りました。
最初のオプションでimportmap-railsがデフォルトになっているので、
何も知らずにインストールしてしまいましたし……。
なので私は色々あってrails newを4回ぐらいしています。
皆様もCSSフレームワークとコンポーネントを入れる際は、十分調査してから導入してください。
II. sass-rails Gemが使用されない為、rails-adminが使用できなかった
下記記事内に、
最近ではCSSフレームワークを使うようになっていて、Sassは使用されなくなってきているので
sass-railsGemが標準ではGemfileに含まれないようになりました。
という表記があります。
私がそれをあまり知らずに、管理画面を作ろうとして偶々rails-adminを使用したところから起きた悲劇です。
rails-admin自体はとてもいいgemです。
簡単に管理画面を作れ、sorceryとも相性抜群です。
なので開発環境では、簡単に導入ができ、ルンルンでHerokuにpushしたところ悲劇が起きました。

何度見てもHerokuのエラーは怖いです。
結局rails-adminを導入した際に、gem "sassc-rails"も一緒に導入されてしまい、
SassC::SyntaxError: Error: Function hsla is missing argument $saturatioが生じてしまったようです。
最終的に、下記記事をスクールの講師の方に教えて頂いて参考にし、
production.rbに下記コマンドを記載することでHerokuへのPushが上手くいきました!
config.assets.css_compressor = nil
こちらを記載することで、sprocketsがassets:precompileステップでsassモードとSassCgemを使用するのを防ぐことができるとのことでした。
これはどのRailsのバージョンを使っていても同じなのでしょうが、
gemによっては上手く使えない物もあるということをちゃんと確認するべきだったなと感じております。
とても便利に使えてしまうからこそ。
後はこまめに本番環境で動くかどうかを確認することが大事だと痛感しました……。
管理画面関係のGemは本番環境で予期せぬエラーがよく生じるイメージがあります。
皆様も十分お気を付けください。
Ⅲ. Rails7からデフォルトになったHotwireに中々慣れなかった
HotwireやTurboに関しては下記の神記事が凄い参考になってわかりやすいので、
是非そちらを読んで欲しいのですが。
簡単に言うと、JavaScriptとか使用せずに非同期通信を行える手法になっています。
このメイン機能として使用されるのがTurboです。
これが最初非常に厄介でした。
例えば検索機能。
検索ページに遷移して、チェックボックスにチェックを入れて、検索ボタンをクリックしても、
何故か検索できないのです。
一度リロードすることで、検索が出来るようになりましたが、これがTurboの性質だと中々気が付けず……
現在は <div data-turbo="false"></div>で囲まれた箇所は、Turboがオフにできる為、
検索ページに飛ぶリンクをこちらで囲むことで対処しています。
<div data-turbo="false">
<li><%= link_to '抹茶スイーツで検索する', greenteas_path %></li>
<li><%= link_to '神社仏閣で検索する', temples_path %></li>
</div>
最初はページ全体を<div data-turbo="false">で囲んでいました。
しかしTurboを使っている場合、link_toメソッドのmethod:オプションの書き方が変わり、
data: { turbo_method: :post } という風にturboを使用して記載する必要があります。
その為link_toメソッドを使用している箇所がルーティングエラーなどになってしまう為、全体を囲むのは稀になっています。
ただTurboを使用することで、ページネーションでの遷移、検索結果の表示の仕方が速くなるのは、
とても動きがサクサクになっているように見えて凄いです!しかもコードの記載の方法も簡単です。
例えばページネーションでの遷移を非同期にしたい場合は、
非同期にしたい箇所を、
<%= turbo_frame_tag 'greentea-list' do %>
<!-- 抹茶スイーツ一覧 -->
抹茶スイーツ一覧のコード
<!-- ページネーション -->
ページネーションのコード
<% end %>
<%= turbo_frame_tag '〇〇' %>で囲むだけ!
更に検索結果を非同期にしたい場合は、
<%= search_form_for @search, html: { data: { turbo_frame: 'greentea-list' } } do |f| %>
search_form_forにhtml: { data: { turbo_frame: '〇〇' } } を追加するだけ!
その際にid(greentea-listとか)は一覧ページと同じものをつけてください。
このコードを書くだけで検索とページネーションが高速化されます!便利〜
しかしこの中に違うページへのリンクがある場合は(今回だといいねボタンとか詳細ページへのリンクボタン)、
リンクに上手く飛べなくなってしまっていたので、
<div data-turbo="false">でそこだけTurboをオフにしています……
もっと上手くコードが書ければと思っているのですが……まだまだTurboと仲良くなれていないです。
でももっと極めれば、やれることが無限大に広がりそうなHotwire、もっと仲良くなりたいですね。
二.スクレイピングのやり方
今回神社仏閣のデータはとある情報サイトからスクレイピングで取ってきています。
※一部神社を除く
本当は神社APIとかあれば一番よかったのですが、個人では使用できそうではなく……。
スクレイピングが禁止じゃないか、法律的に問題がないかを弁護士さんに相談してから、
スクレイピングに挑みました。
とはいえスクレイピングは初めてでしたので、
最初class名とかtag名を引っ張ってこれたらいいんだよな〜と軽い気持ちで、
サイトの情報を見て絶望しました。
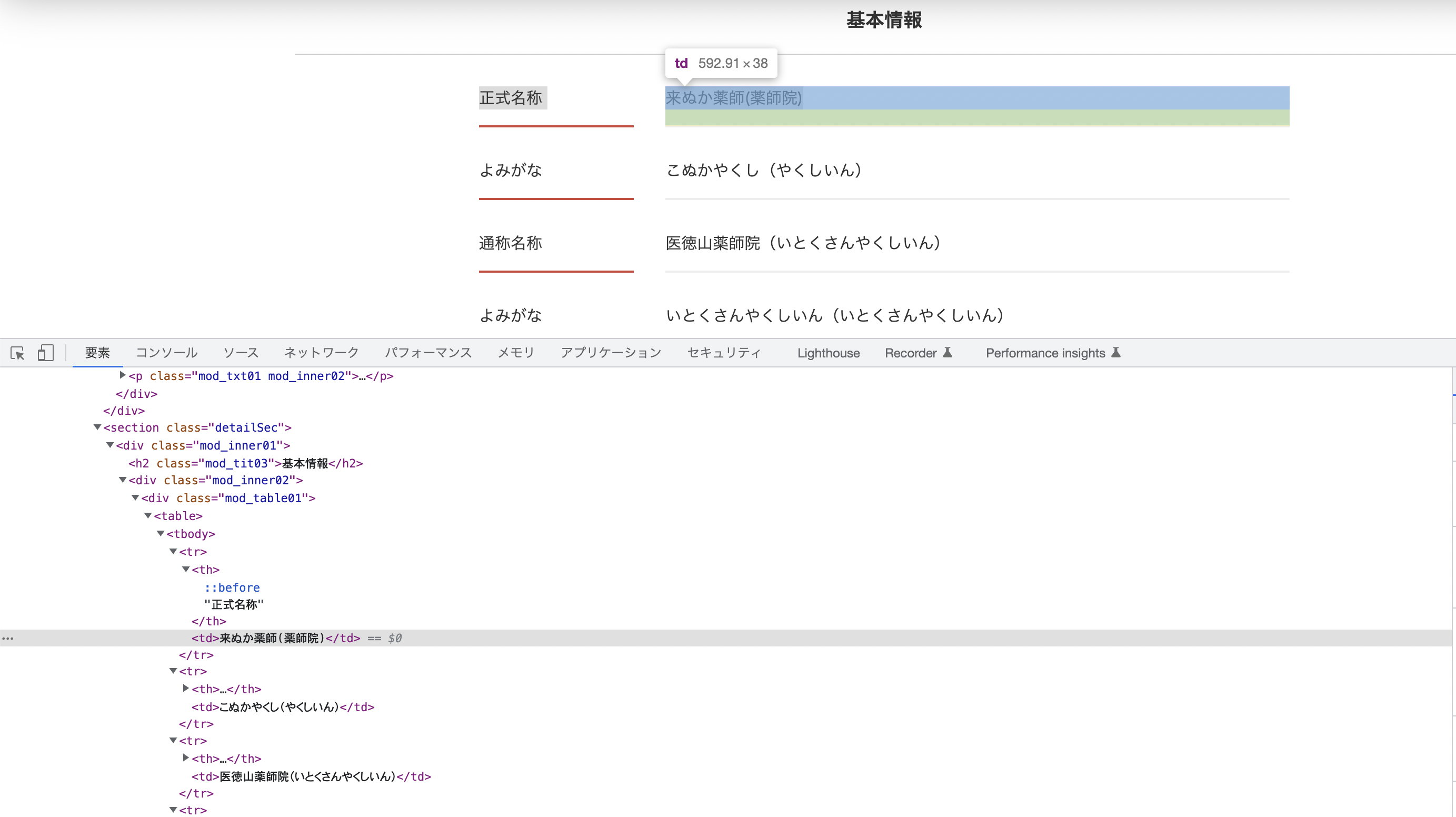
ちょうど欲しいな思っているデータに全然タグやクラスがない〜!
でもスクールで嘆いていたら校長に、
そう言うサイトの方がほぼなくて階層でセレクタ指定すると教えて頂きました。
なるほど……となって結局スクレイピング作業で最終的に書いたコードがこちらになります。
require 'open-uri'
require 'nokogiri'
require 'debug'
require 'CSV'
# 詳細ページに遷移する
# visit tourism_id each 190~683
urls = []
(190..683).each do |i|
urls = urls.push(%W(https://ja.kyoto.travel/tourism/single01.php?category_id=7&tourism_id=#{i}))
end
# 詳細ページからデータを取得する
header = ['name', 'description', 'address', 'access', 'business_hours', 'holiday', 'phone_number', 'homepage']
rows = []
rows << header
# 欲しいデータのセレクタをリスト化する
begin
urls.each do |url|
file = url.join
result = URI.open(file)
# Nokogiriを使用してdomを取得する(各データ分)
doc = Nokogiri::HTML(result)
header = ['name', 'description', 'address', 'access', 'business_hours', 'holiday', 'phone_number', 'homepage']
rows = []
rows << header
# 欲しいデータのセレクタをリスト化する
begin
urls.each do |url|
file = url.join
result = URI.open(file)
# Nokogiriを使用してdomを取得する(各データ分)
doc = Nokogiri::HTML(result)
# 取得したdomからテキストを抽出する
description = doc.at_css('p.mod_txt01.mod_inner02').inner_text
element = doc.css('.mod_table01 td')
name = element[0].inner_text
address = element[4]
access = element[5]
business_hours = element[7]
holiday = element[8]
phone_number = element[9]
homepage = element[10]
rows << [name, description, address, access, business_hours, holiday, phone_number, homepage]
rescue OpenURI::HTTPError => e
puts e
sleep 2
next
end
end
ポイントは表の情報をelement = doc.css('.mod_table01 td')で定義して、
更に欲しい情報をelement[4]とかで取ってきていることですね。
最初の方はスクレイピングする為に必要なGemとか、スクレイピングに必要な処理を書いているだけです。
後私は直接DBに入れる前にデータの修正をしたかったので、
CSV.open("./temple_info.csv","w",:force_quotes=>true) do |csv|
rows.each do |row|
csv << row
sleep 2
end
end
csvに一旦データを保存する処理を書いています。
スクレイピング自体はここでおしまいです。
しかしそれをやる時はサイトを落としてしまわないか、攻撃にならないかとてもヒヤヒヤしました。
データを取れてきた時は感動しましたが、あんまり頻繁にはしたくないな〜と私は思っていますw
ちなみに抹茶スイーツのデータの方は完全に手動で作成しております。
執念のなせる技ですね。
4主な使用技術📚
バッグエンド
・Ruby 3.1.2
・Ruby on Rails 7.0.3
フロントエンド
・JavaScript
・TailswindCSS-daisyUI
インフラ
・Heroku
使用API
・Google Geocoding API(緯度経度の取得に使用)
・Google MapsJavaScript API(マップ作成に使用)
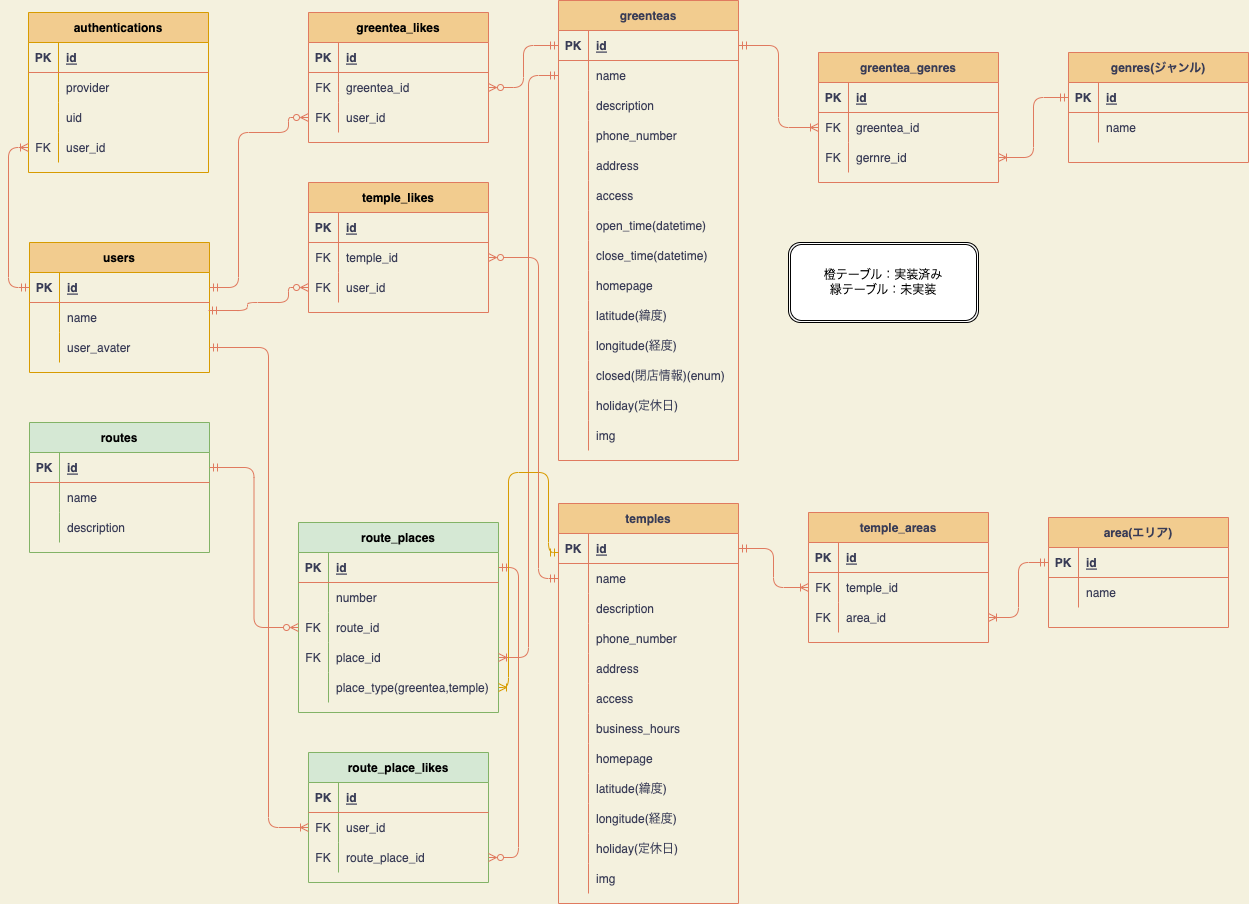
5ER図🌸
6終わりに🌙
長文にも関わらず最後までご覧いただきありがとうございました!
このサービスを通じて抹茶スイーツや神社仏閣にも興味を持って頂ければ嬉しいです🍵⛩
そして皆様の京都旅行のお役に立てればとても嬉しいです!
またRails7でサービスを作る方が増えればいいなと思います。
もっと知見が増えて欲しい。
そして是非一度サービスに遊びに来てください♪
7参考文献📖
この記事は以下の記事を参考にして執筆させて頂きました。