音を用いたOpenposeの解析時間の短縮
人の姿勢を解析してくれるopenpose、この解析時間を音を用いることで短縮しました。この手法を用いてボクシングフォームの解析を行っていきたいと思います。
実行環境
マシン:GoogoleColab
Openpose:キーポイントを取得するため、下記のソースコードを利用させていただいています。実行する際は、こちらに書いてある手法によりgitからドライブにクローンしておくことをお勧めします。 https://colab.research.google.com/drive/1VO4TGJHKXnRKgiSAsNEeQcEHRgzUFFv9
現状の課題
動画の解析に時間がかかる。7分間のミット打ちの動画をOpenposeで解析しようとしたが、GoogleColabを使っても1分解析するのに1時間半かかってしまっている。全部解析するのに10時間半かかってしまい、ランタイムや消費電力を考えると短縮の必要がある。
解決策
音を用いて欲しいシーン(パンチを打つ瞬間と当たった時)のみを抽出し動画を再作成。動画の時間が短縮したのでそれを解析することで実行時間も短くなる。
続きをソースコードと共に解説します。
GoogoleDriveのマウント
下記のコードでGoogleColabからDrive上にあるデータを引用できます。
``` from google.colab import drive drive.mount('/content/drive') ```動画から音声ファイルを生成する
必要なライブラリをインポート
``` import shutil !pip3 install pydub from pydub import AudioSegment ```動画ファイルの読み込みと出力に必要なパスを宣言
``` # 解析する動画ファイルの名前 onlyFileName = "box1911252" # 動画の拡張子を+で追加する filename = onlyFileName + ".mov" # 実行ファイルのあるフォルダを宣言 foldapath = '/content/drive/My Drive/Colab Notebooks/openpose_movie/openpose/' # ファイルのコピー shutil.copy(foldapath + filename, "output.mp4") # 解析する動画ファイルの場所を宣言 filepath = '/content/drive/My Drive/Colab Notebooks/openpose_movie/openpose/'+filename # 切り出しだ動画の画像を音データに基づいて保存するパス filepath = foldapath + filename savepath = foldapath + '/resultSound/'+onlyFileName ```動画ファイルから音声ファイルの切り出し
``` # 動画から音声への変換 !ffmpeg -i output.mp4 output.mp3 # 音ファイルのパスを宣言 filepathSound = './output.mp3' # soundに音データを入れる sound = AudioSegment.from_file(filepathSound, "mp3") ```動画のフレームの数を取得
音データでパンチのタイミングを検出するためには音とそれに対応するフレームを紐づける必要がある。しかし、同じ動画でも音のデータ数とフレーム数は同じではない。例えば2分ほどの動画の場合、音データ数は3480575でもフレーム数2368ある。故にフレーム数で音データを割り、そのフレームに対応する音を抽出するため、このタイミングでフレーム数を取得する必要があります。
``` import cv2 import os def save_all_frames(video_path, dir_path, ext='jpg'): cap = cv2.VideoCapture(video_path) if not cap.isOpened(): return os.makedirs(dir_path, exist_ok=True) digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)))) n = 0 print(digit) while True: ret, frame = cap.read() if ret : #cv2.imwrite('{}_{}.{}'.format(base_path, str(n).zfill(digit), ext), frame) n += 1 else: print(n) frameLength = n return frameLength frameLength = save_all_frames(filepath, 'sample_video_img') ```音データの波形を出力
ここで収集した音データ波形で出力し、確認してからハイパーパラメータを決定する。自動化しようか悩んだが、自由度を持たせるため目視で確認し、パラメータを決定することにしました。
まず、下記のコードで波形を出力
``` ## Input import numpy as np import matplotlib.pyplot as plt import pandas as pd samples = np.array(sound.get_array_of_samples()) sample = samples[::sound.channels] plt.plot(sample) plt.show() df = pd.DataFrame(sample) print(df) max_span = [] # frameLengthは前のセルで検出された動画の総フレーム数が入る len_frame = frameLength span = len_frame for i in range(span): max_span.append(df[int(len(df)/span)*i:int(len(df)/span)*(i+1)-1][0].max()) df_max = pd.DataFrame(max_span) ```こんな感じで波形を見ることができます

この波形はパンチのタイミングで一時的に波形が大きくなっている。部分的に大きくなっている値は大体10000Hz以上となっているので、これをハイパーパラメータとして用いる。下記のコードでハイパーパラメータを設定し、それを超えたタイミングをフレーム番号と紐づけて配列に保存する。
# df_maxは等分した時の音の大きさ、のちに使う
print(df_max)
punchCount = []
soundSize = 10000
for i in range(len(df_max)):
if df_max.iat[i, 0] > soundSize: #ハイパーパラメーター
#print(i,df_max.iat[i, 0])
punchCount.append([i,df_max.iat[i, 0]])
df_punchCount = pd.DataFrame(punchCount)
print(df_punchCount)
抽出動画の生成
以上の処理を元にパンチのタイミングを動画として出力する。
``` # 指定された音量以上が検出されたタイミングでframeを保存する import cv2 import osdef save_all_frames(video_path, dir_path, basename, ext='jpg'):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
return
os.makedirs(dir_path, exist_ok=True)
base_path = os.path.join(dir_path, basename)
digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
frame = []
n = 0
#連続して大きい音を検出しないようにする
slipCount = 0
#出力するvideoファイルの保存パス
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
video = cv2.VideoWriter('/content/drive/My Drive/data/movies/'+onlyFileName+'.mp4', fourcc, 20.0, (960, 540))
#分析用のvideoファイルの保存パス
videoAnalize = cv2.VideoWriter('/content/drive/My Drive/data/movies/'+onlyFileName+'Analize.mp4', fourcc, 20.0, (960, 540))
#何フレーム分を動画に出力するか指定
numFrames=10
#while True:
for i in range(frameLength):
ret, a_frame = cap.read()
if ret :
n += 1
#メモリが増えすぎないように削除していく
if n > 15:
frame[n-15] = [] #複数出力しないので不要
frame.append(a_frame)
if n < len(df_max) and df_max.iat[n,0] > soundSize and slipCount==0:
slipCount = 12
pre_name = "box"+str(n)+"-"
cv2.imwrite('{}{}.{}'.format(base_path,pre_name+str(n-10).zfill(digit), ext), frame[n-10])
cv2.imwrite('{}{}.{}'.format(base_path,pre_name+str(n-2).zfill(digit), ext), frame[n-2])
#nには配列の長さが入るからエラーが出る
for m in range(numFrames):
img = frame[n+m-numFrames]
img = cv2.resize(img, (960,540))
print(img)
video.write(img)
if m == 0 or m>6:
videoAnalize.write(img)
elif slipCount > 0:
slipCount -= 1
else:
video.release()
print(n)
return
save_all_frames(filepath, savepath, 'samplePunch_img')
<p>
以上によりパンチのタイミングを抽出した動画を生成することができました。
生成した動画はMy Drive/data/moviesにあります。
Colabはフォルダ生成してくれないので、フォルダが無い場合自分で作る必要があります。</p>
<h2>Openposeでの解析</h2>
<p>基本的にはこちらにある動画の解析手法を用います。詳細はこちらのURLに書いてあるので実行コマンドのみ記述します。</p>
<a>https://colab.research.google.com/drive/1VO4TGJHKXnRKgiSAsNEeQcEHRgzUFFv9</a>
!git clone --recursive https://github.com/hamataro0710/kempo_motion_analysis
cd /content/kempo_motion_analysis
!git pull --tags
!git checkout refs/tags/track_v1.0
!bash start.sh
!python estimate_video.py --path='/content/drive/My Drive/data/' --video={onlyFileName}"Analize.mp4"
<p>以上によりOpenPoseの動画の解析が終了しました。下のリンクから動画を確認できます。</p>
<a>https://www.youtube.com/embed/BUIfu-QD8x8</a>
<h2>結果</h2>
<p>ハイパーパラメータの値と抽出フレームの枚数にもよりますが、実行時間は10時間→1時間〜30分ほどになりました。</p>
<h2>課題</h2>
<p>これを用いることで体の各パーツの座標を時系列で取得することができます。
しかし、複数人が写っている場合誰がどのデータに紐づくかがわからないという課題があるためYOLOなどを用いて判別も行う必要があると考えられます。</p>
<h2>番外編</h2>
<p>ただ、一人の場合は通常に解析ができるのでサンドバック打ちをこの手法を用いてボクシングのパンチフォームの解析を実施しました。</p>
<p>ボクシングの良いパンチは打つ時に肘が伸びきっています。そこで、ボクシングのパンチの瞬間にパンチが伸びきっているものと、伸びきっていないものをOpenposeを用いて解析し、写真を取得して比較しました。</p>
<p>腕が伸びきっていないパンチの例</p>
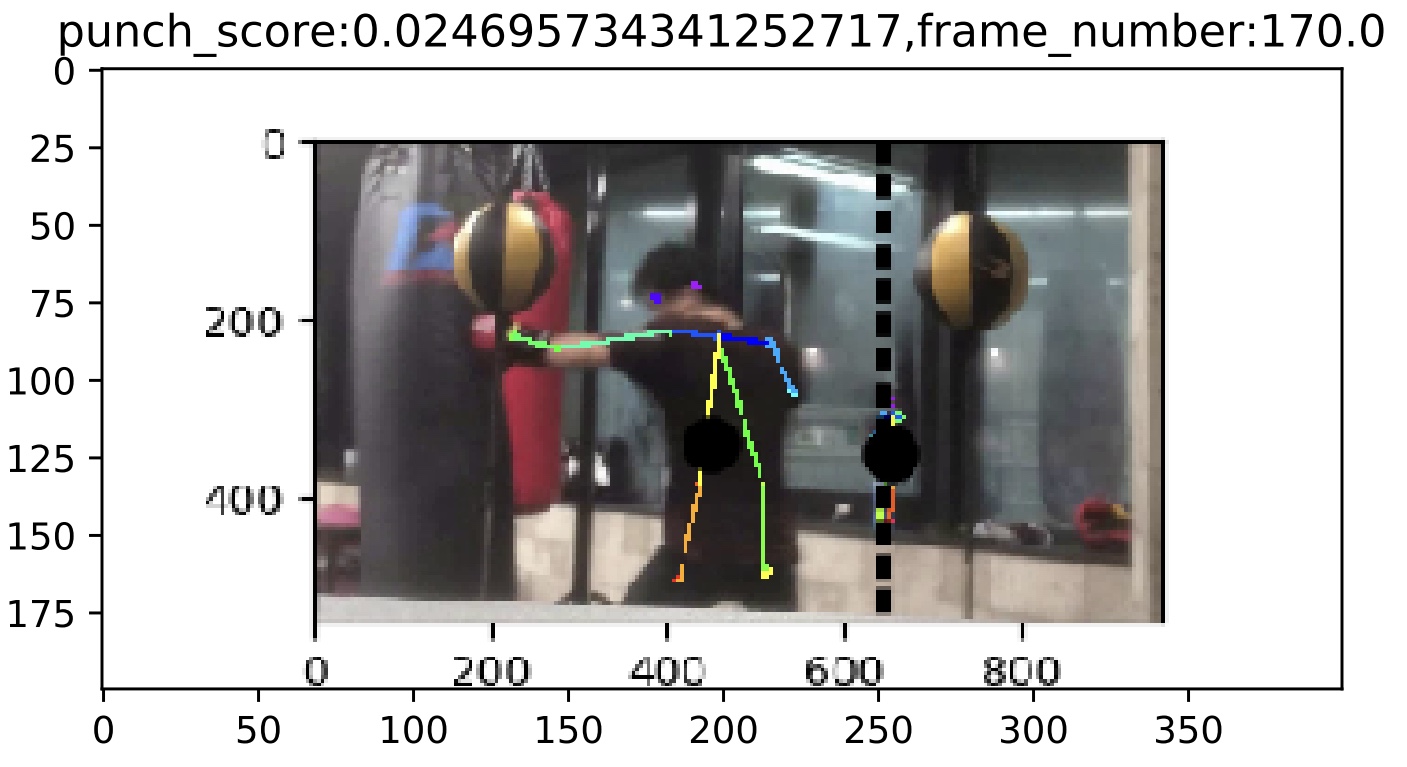
<p>腕が伸びきっているパンチの例</p>
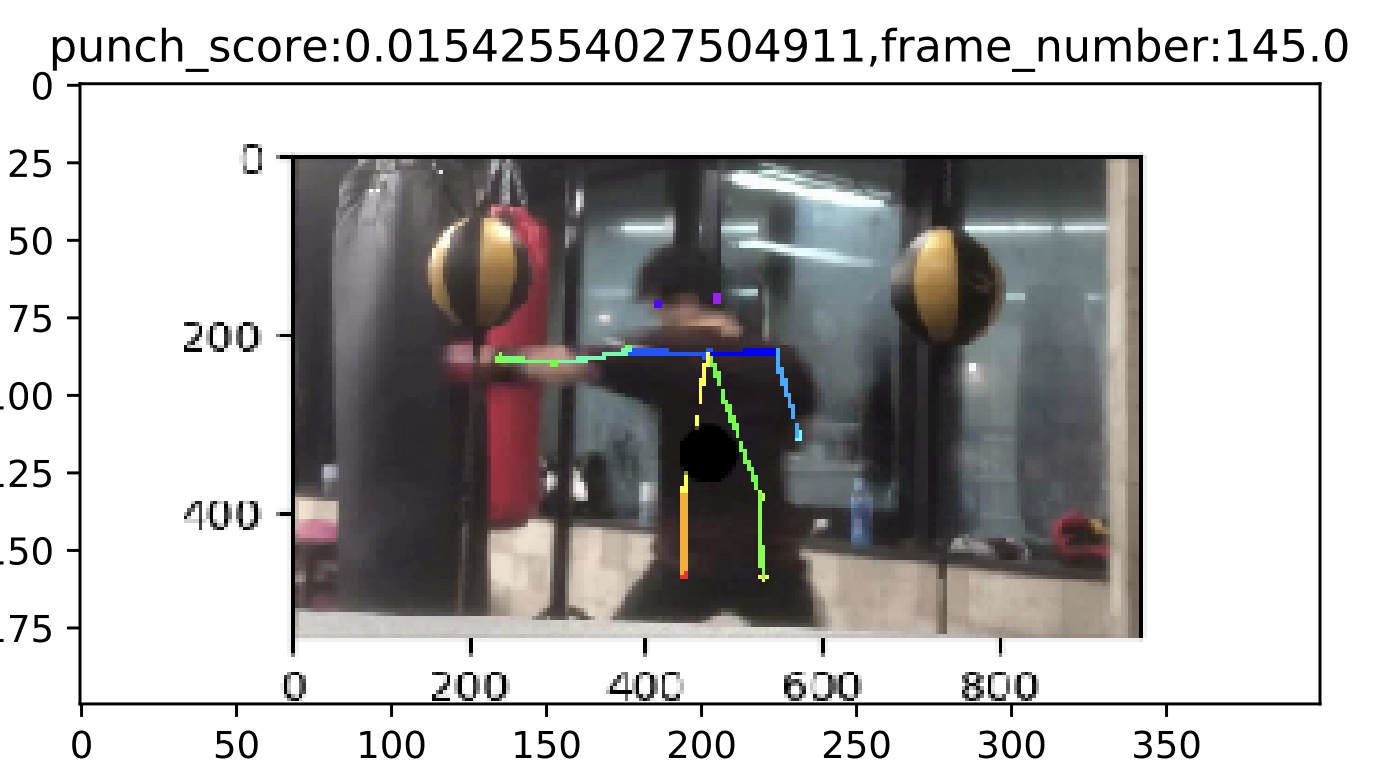
<p>上記の例を比較した時に腕が伸びきっているパンチは、肩が水平になっていて、両肩から手までが一直線になっている。逆にパンチが伸びきっていない場合、片方の肩が上がっていて、肩から手間でのラインが一直線になっていない。このことから手を出すことより肩を回し切ることを意識することで、良いパンチが打てるようになれると考えられます。</p>
<p>今後データを増やして相関係数を出して仮説を確かめたり、色んな手法を用いてデータ解析をしていきたいと思います。</p>
<h2>最後に</h2>
<p>クソコードばかりでごめんなさいm(_ _)m</p>