はじめに
MLflowに学習パラメータやメトリクス、学習済みモデルを保存するためには、学習スクリプトにロギングを実行するメソッドを追加する必要があります。本記事では、MLflowでロギングを行う方法について、サンプルを通じて説明していきたいと思います。
学べること
- 実験の名前を設定するメソッド(set_experiment)の使い方
- パラメータ・メトリクス・モデルなどを手動ロギングするメソッド(log_param, log_metric, log_artifact)の使い方
- 自動ロギングするメソッド(autolog)の使い方 ←←便利!
サンプルスクリプト
下のサンプルスクリプトを使って、ロギングメソッドの説明をしたいと思います。
https://github.com/highitoh/ML_pinchos/blob/master/mlflow/train_manuallog.py
このスクリプトは、TensorFlow 2.0向けに実装されたYOLOV3の学習スクリプトをベースにして作成しています(参考リンク)。ベースのスクリプトに対して、ロギングのために次の内容を追加しています。
【212~213行目】
import mlflow
mlflow.set_experiment("signal_detect")
【215~227行目(一部略)】
mlflow.log_param("dataset", FLAGS.dataset)
mlflow.log_metric("loss", float(history.history['loss'][epoch - 1]))
mlflow.log_artifact("checkpoints/yolov3_train_" + str(epoch) + ".tf.index")
213行目は実験の名前の設定するメソッド、215~227行目はMLflowへのロギングを実行するメソッドになります。それぞれのメソッドの概要について、これから説明していきます。
実験の名前を設定するメソッド
パラメータやファイルの保存を実行する前に、実験の名前を設定しておきます。
実験の名前はset_experimentメソッドで設定できます。サンプルスクリプトでは、名前を"signal_detect"として設定しています。
mlflow.set_experiment("signal_detect")
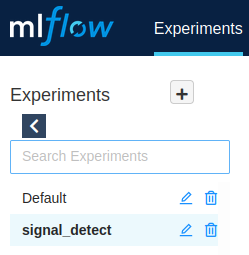
実験の名前を設定すると、MLflowのUIのサイドバーに表示されるようになります。**実験の名前を設定しておくと、学習結果をプロジェクトごとに分けて管理しておくことができます。**なお、名前を設定せずにロギングをしたときは、"Default"に結果が保存されます。
手動ロギングするメソッド
MLflowにはロギングのメソッドがいくつかありますが、ここでは主要なものとして下の3種類を説明します。
-
log_param(パラメータの保存)
学習時に設定したパラメータを保存するときに使用します -
log_metric(メトリクスの保存)
学習時の評価指標(lossなど)を保存するときに使用します -
log_artifact(成果物の保存)
学習済みモデルなどのファイルを保存するときに使用します
log_paramとlog_metricは、ロギングしたいパラメータやメトリクスの名前を第一引数、値を第二引数に入れて実行します。
mlflow.log_param("dataset", FLAGS.dataset)
mlflow.log_metric("loss", float(history.history['loss'][epoch - 1]))
log_artifactは、保存したいファイルのパスを引数に入れて実行します。
mlflow.log_artifact("checkpoints/yolov3_train_" + str(epoch) + ".tf.index")
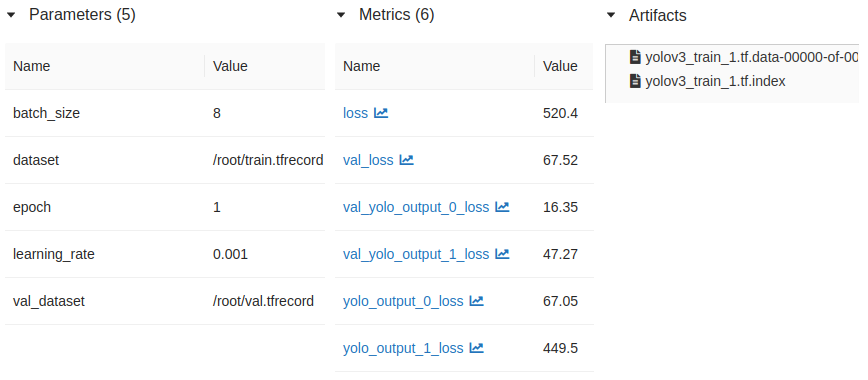
サンプルスクリプトを実行して、MLflowのUIで実験結果を参照すると、下のように表示されます。メソッドに応じてデータをカテゴライズして保存してくれていることがわかります。
自動ロギングするメソッド
上で紹介したロギングするメソッドはシンプルなので、使い方に悩むことはあまりないと思いますが、一つ一つロギングしたいパラメータやモデルを指定することを、面倒に感じる人もいるかもしれません。そこで便利なのが自動ロギングです。自動ロギングを実行すると、学習に使用したパラメータやメトリクス、学習済みモデルなどを自動的に識別してロギングしてくれます。
自動ロギングは、autologメソッドを呼び出すことで実行できます。自動ロギングをするサンプルスクリプトを下に載せています。
https://github.com/highitoh/ML_pinchos/blob/master/mlflow/train_autolog.py
ベースのスクリプトとの変更箇所は、下の3行のみです。特に、ロギングの実行に関するメソッドは最後の一行だけです。
import mlflow
mlflow.set_experiment("signal_detect")
mlflow.tensorflow.autolog()
自動ロギングを使用するには、学習に使うAIフレームワークがMLflowの自動ロギングに対応している必要があります。今回のモデルはTensorFlow 2.0を使用しているので、mlflow.tensorflowのautologメソッドを呼び出しています。対応しているフレームワークは、下のリンクに書かれています。TensorFlow/Kerasの他に、PytorchやScikit-Learnなど主要なものは対応していそうです。
https://mlflow.org/docs/latest/tracking.html#automatic-logging
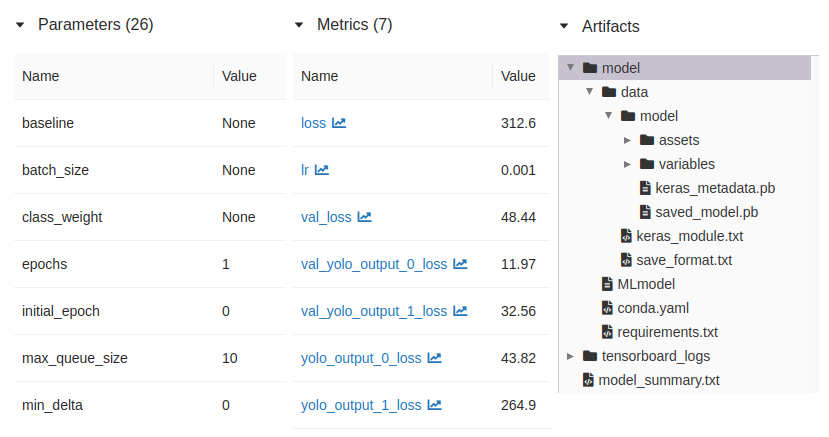
サンプルスクリプトで自動ロギングしたときのUI表示を下に載せます。**パラメータ、メトリクス、成果物ともに多くの種類が保存されていることがわかります。**ロギングされる内容に不満がなければ、自動ロギングを使うほうが実装も少なくて楽ですね。
おわりに
本記事では、MLflowにパラメータやモデルを保存するのに実行するメソッドを説明しました。自動ロギングを使うと、数行追加するだけで学習のロギングができるようになり便利ですので、ぜひ試してみてください。
参考リンク
- MLflow Tracking
https://mlflow.org/docs/latest/tracking.html - MLflow Python API
https://mlflow.org/docs/latest/python_api/index.html - MLflow with TensorFlow 2.0.0
https://github.com/mlflow/mlflow/tree/master/examples/tensorflow/tf2 - YoloV3 Implemented in TensorFlow 2.0
https://github.com/zzh8829/yolov3-tf2