はじめに
毎年この時期に新入社員向けの研修を担当させてもらっている。
自分の持ち回りとしてはウェブ技術に特化した話をしている。
ただでさえも毎日詰め込みで研修している中、小難しい話をしても眠たくなるだけだろうからなるべく興味をもってもらおうと心掛けているのだが、通常の主担当業務とは別に対応する案件なので準備が煩わしく適当に済ます時もあった。
経験上、それなりに内容を考えて実践すると反応はよく手を抜くと反応は悪い。しかし準備万端でも受講側が緊張している雰囲気の中、つまらんギャグがすべったりしてそのままノリの悪い進行になる場合もたまにある。
あと、いつも同じパターンでやっているとこちらも飽きてくるので今回は内容を刷新してみた。
アイスブレーク
まず事前にいただいた自己紹介文を元に、少し話を掘り下げてトークするいわゆるアイスブレークを実施した。
また簡単なアンケート調査をしてその中で使用しているSNSを聞いてみるとLine, Instagram, Youtubeは全員よく使っており、Twitterはその次でFacebookはほとんど使っていない。
自分はやっていないけど一応TikTokも聞いてみたがこちらの利用者も少ない。もっと若い子が使ってるのかな。
世界で最も有名なプログラムを紹介
次に「小難しい話」をしないっと言っておきながらK&Rの例のやつを見せて実行結果を予想してもらった。
hello.c
#include <stdio.h>
int main(void) {
printf("hello world!\n");
return 0;
}
恐らく人生で初めてソースコードを見たのかもしれないのでどんな回答するか楽しみだった。
結果
- 「コピーが開始される」(なんの?)
- 「helloと入力すると次へ進む」
- 「時間によってハローとグッドナイトが表示される」
最後のが笑った。
もちろん、正解に近いものもあったしわからないから無回答のものもあった。
今は小学生でもプログラミングを習う時代なのでその頃には違う回答を得られるかもしれない。
で、実行結果を見せたのだけどもその前にコンパイルがいる
make hello
./hello
実行結果を見せた時の反応はまあ薄い。そりゃそうだそんな面白いプログラムでもない。
そしてできあがった実行ファイルhelloの中身を見せてわけのわからないものが出来上がっていることを紹介した。
次にPython版を紹介
hello.py
print("hello world!")
同じ結果が表示されることを説明。hello.cにはプログラミング言語のいろんなエッセンスが含まれた素晴らしいものだと改めて思うけども彼らには伝わらないであろうから逆に同じことをするにも今ではこんな簡単にできるんだよという説明にした。もちろんコンパイルも不要だし。
InstagramやYoutubeのデータを取得
若干堅苦しい話になってきたので視点を変えてみた。
まずInstaloaderを使って渡辺直美さんの4月1日以降のデータを取得するデモを行った。
instaloader --post-filter="date_utc >= datetime(2022, 4, 1)" watanabenaomi703
ダウンロード用のフォルダに画像が溜まっていくところを見せると割と反応がよかった。
次にyoutube-dlを使って適当に動画をダウンロードしてみた。
youtube-dl <適当なvideo-id>
こちらは反応は薄かった(泣
いずれにしても著作権侵害にも該当しかねない旨は伝えてあくまでも技術的にはこういうことは可能だよという説明にした。
実践RPA
ここから本題。RPAといってもスクレーピングの話だ。
ただいきなり結果のみを見せるのではなく順序立ててやってみた。
グーグルのページを操作
最初はページを開くだけ
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
driver.get('https://www.google.com/')
こちらはソースも見せてわずか3行でできることを伝えた。
次、キーワード検索してみる(参考Google Search Automation with Python Selenium)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('chromedriver')
driver.implicitly_wait(0.5)
#launch URL
driver.get('https://www.google.com/')
# identify search box
m = driver.find_element(By.NAME, 'q')
#enter search text
keywords = 'ウクライナ'
m.send_keys(keywords)
time.sleep(2)
#perform Google search with Keys.ENTER
m.send_keys(Keys.ENTER)
自動化しているとはいえここまでは人間が実際にブラウザを操作するのとあまり変わらないので便利さがよくわからないだろうと説明した。
そして【Python】Google検索結果をExcelに出力する - stmtkの技術ブログを参考にして、検索結果をエクセルファイルに出力した。
最後にエクセルファイルを開くように修正している(Linux環境なのでwpsを用いた)。
import datetime
import subprocess
import time
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('chromedriver')
driver.implicitly_wait(0.5)
#launch URL
driver.get('https://www.google.com/')
# identify search box
m = driver.find_element(By.NAME, 'q')
#enter search text
keywords = 'ウクライナ'
m.send_keys(keywords)
time.sleep(0.2)
#perform Google search with Keys.ENTER
m.send_keys(Keys.ENTER)
# 検索結果のリンクを取得する
elements = driver.find_elements(By.CSS_SELECTOR, '.g .yuRUbf > a')
# URLとタイトルを取得する
data = list()
for element in elements:
url = element.get_attribute('href')
title = element.find_elements(By.CSS_SELECTOR, 'h3')[0].text
data.append({'url': url, 'title': title})
driver.quit()
# Excelに出力する
book = openpyxl.Workbook()
sheet = book.active
sheet.cell(row=1, column=1).value = 'キーワード'
sheet.cell(row=1, column=2).value = ' '.join(keywords)
sheet.cell(row=2, column=1).value = '検索順位'
sheet.cell(row=2, column=2).value = 'タイトル'
sheet.cell(row=2, column=3).value = 'URL'
for i in range(len(data)):
sheet.cell(row=3 + i, column=1).value = 1 + i
sheet.cell(row=3 + i, column=2).value = data[i]['title']
sheet.cell(row=3 + i, column=3).value = f'{data[i]["url"]}'
sheet.cell(row=3 + i, column=3).value = f"=HYPERLINK(\"{data[i]['url']}\")"
sheet.column_dimensions['A'].width = 10
sheet.column_dimensions['B'].width = 60
sysdate = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
output = f'検索結果_{sysdate}.xlsx'
book.save(output)
# WPS Officeで開く
subprocess.run(['wps', output])
グーグルで調べた結果をエクセルにまとめるという作業が自動化されたのでこれは便利さが伝わったかと思う。
ECサイトの操作(基本編)
ここからが本題。だけども業務に関わる内容なのでソース公開は控えたい。
特定のECサイトを取り上げいろいろ操作するデモを実践した。
手順はこんな感じ。
最初のデモ
ログインページを表示するだけ
二番目のデモ
アカウント情報を元にログインしてみる
三番目のデモ
ログイン後、検索画面に検索項目を入力して表示されることを確認。
また適当に検索項目の値を変更して実演。
ECサイトの操作(応用編)
基本編での反応はどうだったかあまり確認していなかったが気にせず応用編に行く。
スクリーンショットの取得
視覚的に訴えるなら文字情報を出力するよりスクショを撮ったほうがよい。
seleniumでは簡単にできる
driver.get('https://www.google.com')
driver.save_screenshot('screenshot.png')
ただし上記のやり方だと画面の表示領域しか取得できない。
ランディングページのように縦に長いものを取るときはヘッドレスモードにしてフル画面を取得する。
w = driver.execute_script('return document.body.scrollWidth')
h = driver.execute_script('return document.body.scrollHeight')
driver.set_window_size(w, h)
driver.save_screenshot('screenshot.png')
(参考)【Python】Seleniumでページ全体のスクリーンショット撮るならマルチプロセスで! - Qiita
Lineに送る
一昔前だとメールに送るデモにするが、今回はLine Notifyを使って上記スクショを送ってみる。
import requests
token = 'あなたのトークン'
endpoint = 'https://notify-api.line.me/api/notify'
headers = {'Authorization': f'Bearer {token}'}
data = {'message': 'スクショ撮ってみた'}
with open('screenshot.png', 'rb') as f:
binary = f.read()
files = {'imageFile': binary}
resp = requests.post(endpoint, headers=headers, data=data, files=files)
実演前にスマホを皆の前に置いておき、実行した後、通知音がなった時に歓声があがった。よし。
改良版
ここで終わってもよいんだけど上記サンプルだとスクショが縦長すぎてかつLineで送るファイルサイズの容量制限があるのでリサイズしたらなんだかよく伝わらない画像になった。
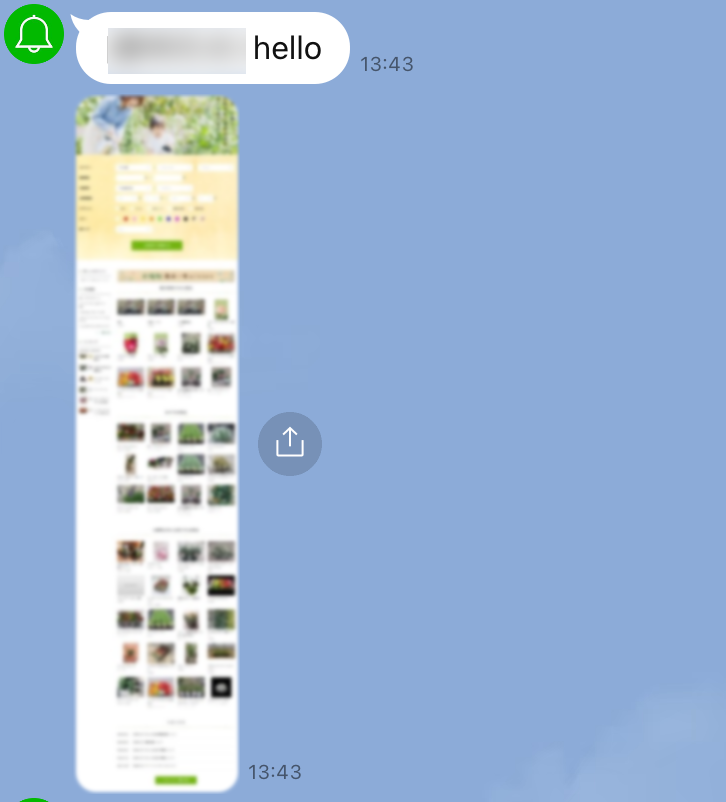
ヘッダやフッタが長いし。サイドバーもいらん。
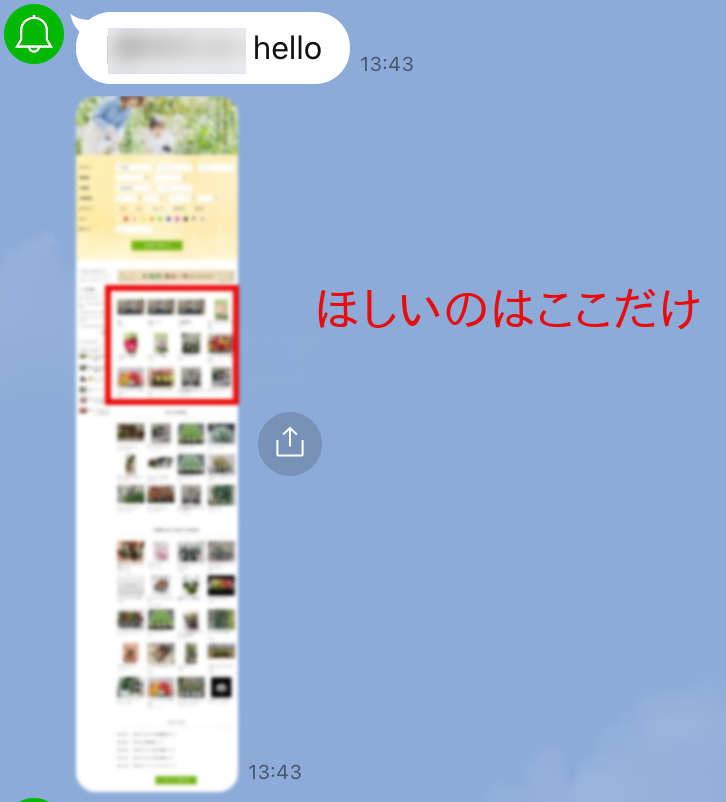
なので切り取ってみる。
正確にやるにはPillowを使ってcropすべきだが、適当に座標を決め打ちしてやってみた。
driver.execute_script("window.scrollTo(400, 1440);")
driver.save_screenshot(screenshot)
結果

最後に本当に自動で行っているか証明するためにcronで指定の時間に設定した。
そして待つこと数分。。。
ピコっ
(Lineの通知音のつもり)
皆から拍手をいただいた(満足)。
最後に
うまく伝わったかわからないけど少しでも興味を持ってもらえたら満足だ。
まだまだ慣れないだろうけども一日も早く戦力になってほしい。