Python Advent Calendar 2022のトップバッター務めさせていただきます。
はじめに
有益な情報サイトは多く存在するが少しカスタマイズできれば見やすくなるのになと思うことが多々ある。
そこで投資情報サイト「フィスコ」が提供している「出来た株・動いた株」の情報を整形してより見やすくしてみる。

このサイトの大引け後の15:45に発表される情報でも終値でないザラ場情報の場合があるので注意。
対象読者
本記事は以下の項目に興味があれば参考にしていただきたい。
-
Python-Seleniumを使ったスクレイピング -
pandas_datareader/mplfinanceを用いたデータの取得および可視化 - 上記をGoogle Colaboratoryを使って実装
利用環境
お手軽に利用できるGoogle Colaboratoryを用いる。
ローカル環境で実行する場合は必要に応じて環境構築を行う。
実装
対象サイト
フィスコが取引日に定期的に更新している「出来た株・動いた株」は大きく動いた銘柄を紹介しており投資活動の参考情報となる。
以下がオリジナル。

各銘柄が順不同で表示されているので上昇したのか下落したのか、またどのくらいの値幅で動いたのかがぱっと見わかりにくい。
なので次のように価格変動(上昇・下落率)の大きい順番で表示してみたい。

ライブラリのインストール
Google Colaboratoryに標準インストールされていないものをpipで導入する。
!apt-get update
!apt install chromium-chromedriver
!pip install pip --upgrade
!pip install selenium
インポート
単純に文字情報をスクレイピングするだけならseleniumを使うまでもないのだが、このサイトはJavascriptでコンテンツを動的に吐き出しているのでbs4などではうまく処理できない。
import re
from IPython.display import HTML, display
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
変数定義
Seleniumの待ち時間、サイトのURLや文字列操作用の正規表現のパターンを定義する。
wait = 1
url = 'https://market.fisco.co.jp/update/analysis/kabu.jsp'
pattern = '\*(.+)<(\d+)>\s(\d+)\s(.+\d+)\n(.+)'
rc = re.compile(pattern, re.MULTILINE | re.DOTALL)
# Yahoo!ファイナンスのエンドポイント
stock_base_url = 'https://finance.yahoo.co.jp/quote/'
Seleniumの初期化
SeleniumをGoogle Colaboratoryを使う場合はheadlessモードにする必要がある。
ローカル環境でやる場合はheadlessモードを設定せずに視覚的に楽しんでほしい😁。
options = webdriver.ChromeOptions()
options.desired_capabilities = DesiredCapabilities.CHROME
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
service = Service(executable_path='/usr/lib/chromium-browser/chromedriver')
driver = webdriver.Chrome(service=service, options=options)
driver.implicitly_wait(wait)
データ取得
生データの取得はわずか数行で実現できる。
# seleniumを使ってデータ取得
driver.get(url)
# 後で使うがサブタイトルの日付データとしてugodeki_uptimeというIDを持つ要素を取得。
elem = driver.find_element(By.ID, 'ugodeki_uptime')
date_text = elem.text
# 株価情報としてugodekiというIDを持つ要素を取得
elem = driver.find_element(By.ID, 'ugodeki')
word_list = re.findall(pattern, elem.text)
得られたword_listはこんな感じに銘柄、コード、株価、増減、コメントに分解してリスト化している。
[('マツキヨココ', '3088', '5480', '+230', '23年3月期業績予想を上方修正。'),
('日本製鋼所', '5631', '2973', '-157', '上半期営業利益56%減。'),
('コマースワン', '4496', '813', '-107', '上半期営業利益は前年同期比14%減。第1四半期の同9%減から減益率拡大。'),
...
加工および並び替え
株価が上昇したのか下落したのかがわかりやすいように色付けする。
さらに変動率の高いもの順に並び替える。
ソートキーについては値幅を用いてもよいが株価が高いものほど大きくなりやすいのでここでは変動率とした。
またratioの算出箇所がDRYになっていないが+でも-でもないデータがたまに入ってくるのでその時の元データの構造がわからず例外を発生しそうなのであえてこう実装している。
word_list_updated = list()
for x in word_list:
if x[3].startswith('+'):
color = '#090'
ratio = float(x[3]) / (float(x[2]) - float(x[3])) * 100
elif x[3].startswith('-'):
color = '#900'
ratio = float(x[3]) / (float(x[2]) - float(x[3])) * 100
else:
color = '#000'
ratio = 0
word_list_updated.append(x + (color, ratio))
word_list_updated.sort(key=lambda x: x[6], reverse=True)
加工したword_list_updatedは以下のようになる。色コードと変動率を追加して並び替えている。
[('Abalance',
'3856',
'2826',
'+481',
'通期業績予想を上方修正している。',
'#090',
20.51172707889126),
('KPPGHD',
'9274',
'957',
'+150',
'通期業績予想を大幅に上方修正。',
'#090',
18.587360594795538),
...
]
出力
htmlを生成してdisplayメソッドでIPythonやGoogle Colaboratory上で表示する。
output = '<h1>(フィスコ)出来た株・動いた株</h1>'
output += f'<h2>{date_text}</h2>'
output += '''
<table>
<thead>
<tr>
<th>コード</th>
<th>銘柄</th>
<th>株価</th>
<th colspan="2">変動価格</th>
<th>コメント</th>
</tr>
</thead>
<tfoot></tfoot>
<tbody>
'''
for x in word_list_updated:
output += f'''
<tr>
<td><a href="{stock_base_url}{x[1]}.T" target="_blank">{x[1]}</a></td>
<td>{x[0]}</td>
<td style="text-align: right;">{int(x[2]):,}円</td>
<td style="color: {x[5]}; text-align: right">{x[3]}円</td>
<td style="color: {x[5]}; text-align: right">{x[6]:1.2f}%</td>
<td>{x[4]}</td>
</tr>
'''
output += '''
</tbody>
</table>
'''
display(HTML(output))
出来上がりは以下。
拡張
これを使うようになって感じたのは大きく動いた銘柄は文字情報だけでなくチャートも確認したくなるということだった。
銘柄のところがリンクになっているのでYahoo!ファイナンスで詳細を確認することはできるのだが、いちいちクリックするのも面倒である。
そこでこうしてみた。
追加モジュール
!pip install mplfinance
import base64
import datetime
from io import BytesIO
import mplfinance as mpf
import pandas_datareader.data as pdr
import requests
そして前準備。
# User Agent
user_agent = {
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0',
'Accept': 'application/json;charset=utf-8'
}
session = requests.Session()
session.headers.update(user_agent)
# Interval
end = datetime.date.today()
start = end - datetime.timedelta(weeks=13) # 3ヶ月分のデータ(好みで変更)
出力
細かい説明は割愛してソースを紹介する。
処理時間が30秒近くかかる。
output = '<h1>(フィスコ)出来た株・動いた株</h1>'
output += f'<h2>{date_text}</h2>'
output += '''
<table>
<thead>
<tr>
<th>銘柄情報</th>
<th>チャート</th>
</tr>
</thead>
<tfoot></tfoot>
<tbody>
'''
for x in word_list_updated:
symbol = f'{x[1]}.T'
stock_url = f'{stock_base_url}{symbol}'
chart_url = f'{stock_url}/chart'
df = pdr.DataReader(symbol, 'yahoo', start, end, session=session)
buffer = BytesIO()
mpf.plot(df, type='candle', figsize=(4, 2), xlabel='', ylabel='', mav=(4, 9, 18), savefig=buffer)
img = base64.b64encode(buffer.getvalue()).decode("ascii")
output += f'''
<tr>
<td>
<ul>
<li><a href="{stock_url}" target="_blank">{x[1]} {x[0]}</a></li>
<li>{x[2]}円 <span style="color: {x[5]}">{x[3]}円({x[6]:1.2f}%)</span></li>
<li>{x[4]}</li>
</ul>
</td>
<td><a href="{chart_url}" target="_blank"><img src="data:image/png;base64,{img}" /></a></td>
</tr>
'''
output += '''
</tbody>
</table>
'''
display(HTML(output))
簡単に解説するとpandas_datareaderでデータ取得してmplfinanceでプロットする。
チャートはbase64でエンコードしてデータURI形式で表示している。
結果
(引用: フィスコ,pandas_datareader(Yahoo!Finance))
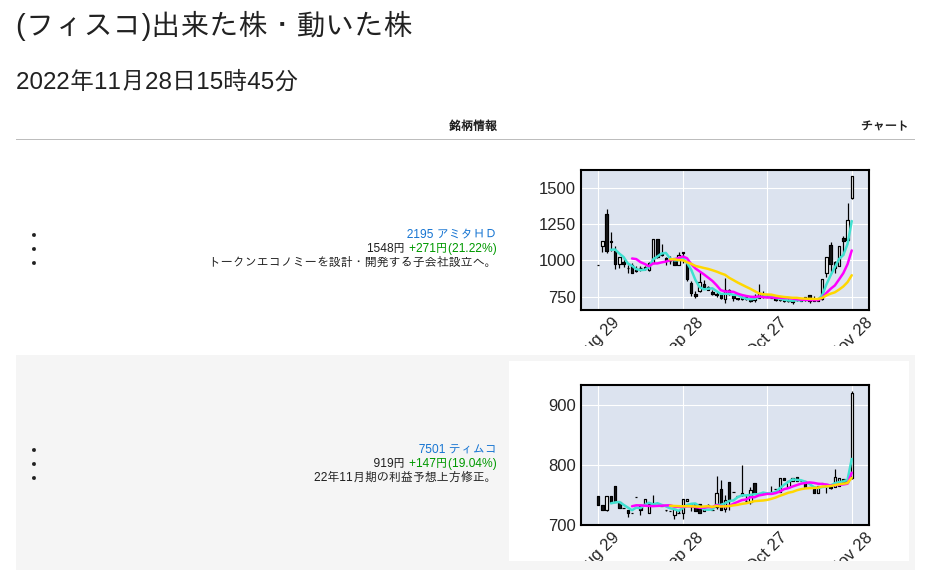
もともとYahoo!ファイナンスからスクリーンショットをキャプチャすることを考えていたのだがスクレイピングは禁止されているので本バージョンに修正した。
スクショとってPILでゴニョゴニョするテクニックも紹介したかったが。。。
チャート生成することで結果的には処理時間が大幅に短縮できたのと表示のカスタマイズできるので大きな改善となった。
ソース
今回用いたソースは以下。
Github上ではhtmlソースを出力する箇所のhtmlタグが反応してしまい表示が崩れている。そのため詳細はダウンロードしてソースを確認してもらいたい。
まとめ
投資情報の解釈について
株価が事前に大きく動くことがわかっていればいいのだが、実際はそうはいかず結果でしか知ることはできない。
大きく下落したので反発狙いで買ってもずるずる下がったり、逆に強い上昇を見せたものを買っても高値掴みになってしまったり。
個人的には6ヶ月あたりのレンジで上昇トレンドであれば瞬間的に下落しても戻すことが考えられるので、一旦ファンダメンタルズを確認して問題なさそうなら買いを検討する。
ファンダメンタルズの確認は絶対必要。不祥事とかが原因であれば戻りは期待しにくい。
絶対にやらないのは下降トレンドでさらに下落したものの取引。これは買いも売りも危険すぎる。
それでもうまく行く場合もあればそうでない場合もあるが損切りを含めた手仕舞いポイントとしっかり掴んでおけば利益を生み出すことはできる。
それが簡単でないのが問題なのだが。
しかし取引とは関係なくこの情報は見ているだけで楽しく感じる。
「これを買っておけば大きく儲かったな」とか勝手に想像しているのが楽しいのだ。
宝くじで大当り情報を聞いて思いを馳せるのに近いか。
既に手放した銘柄が大きく下落していて「おっーセーフ」とか思う時もある。
なお、宝くじは買ったことがない。
Google Colaboratoryでの実装
多少の礼儀作法には従う必要があるもののGoogle Colaboratoryを使うとどこからでもお手軽に実行できるので最近は好んで使っている。色々制限はあるが、諦めずに調べると意外と問題解決できたりする。
スクリプトと実行結果が一つにまとめられてレポート形式に表示できるのもよい。
難点はバージョン管理がしにくいことかな。まあ適時Githubにコピればいいんだけど。