概要
GraphCMSとHugoの連携三回目。
今回はPythonでGrapQLを実行してGraphCMSからコンテンツを取得する方法の解説をする。
前準備
GraphCMSのトークン発行
GraphCMSのAPIにアクセスするにはエンドポイントとトークンが必要となる。
まずエンドポイントだが、これはプロジェクト作成とともにできているので以下で確認できる。
ダッシュボード>Settings>API Access>Endpoints
次にトークンを発行する。
Permanent Auth Tokensにて以下を設定してCreate tokenをクリック。
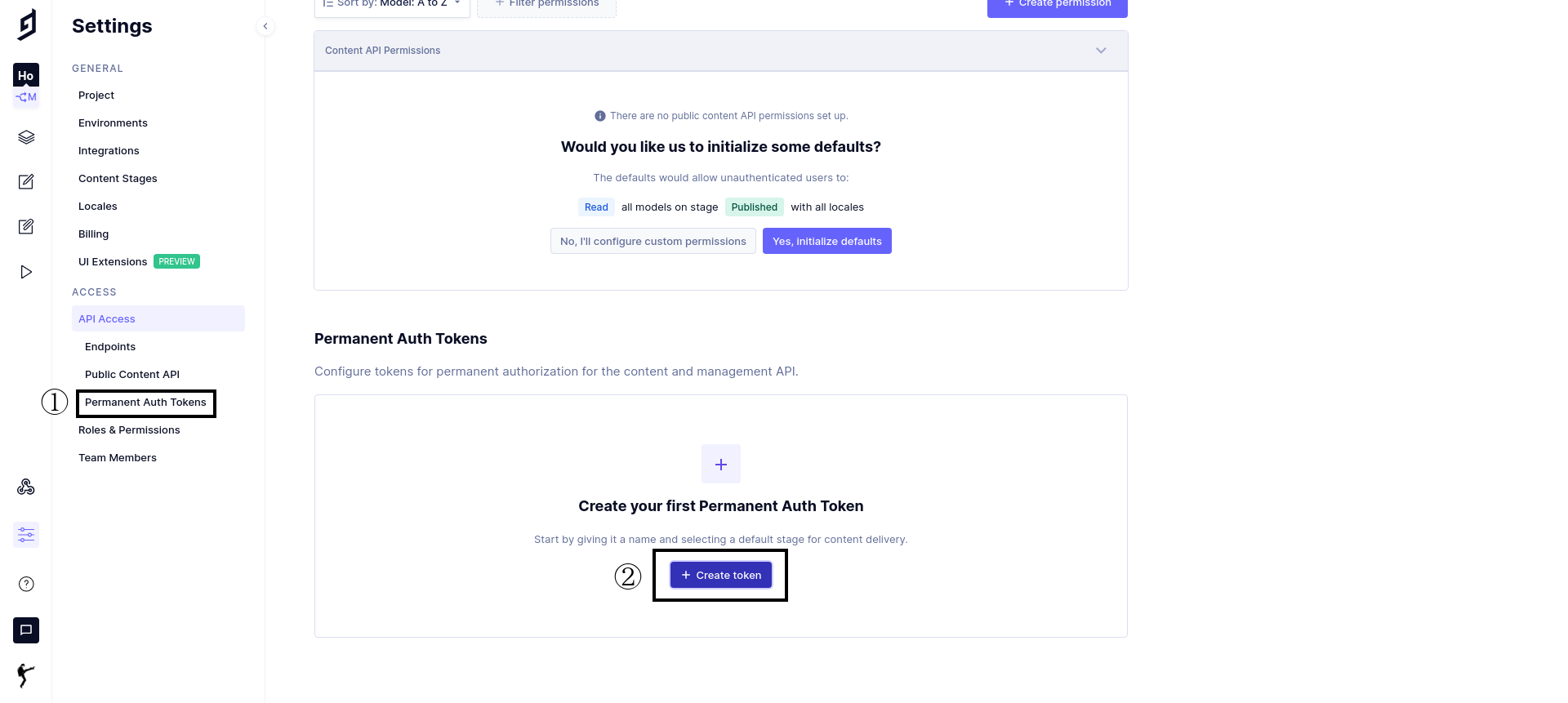
-
Token Name: 適当な名前 -
Description: 適当な説明(省略可) -
Default stage for content deliverry:Publishedをチェック -
Create & configure permissionsをクリック
そうするとトークンが発行される。
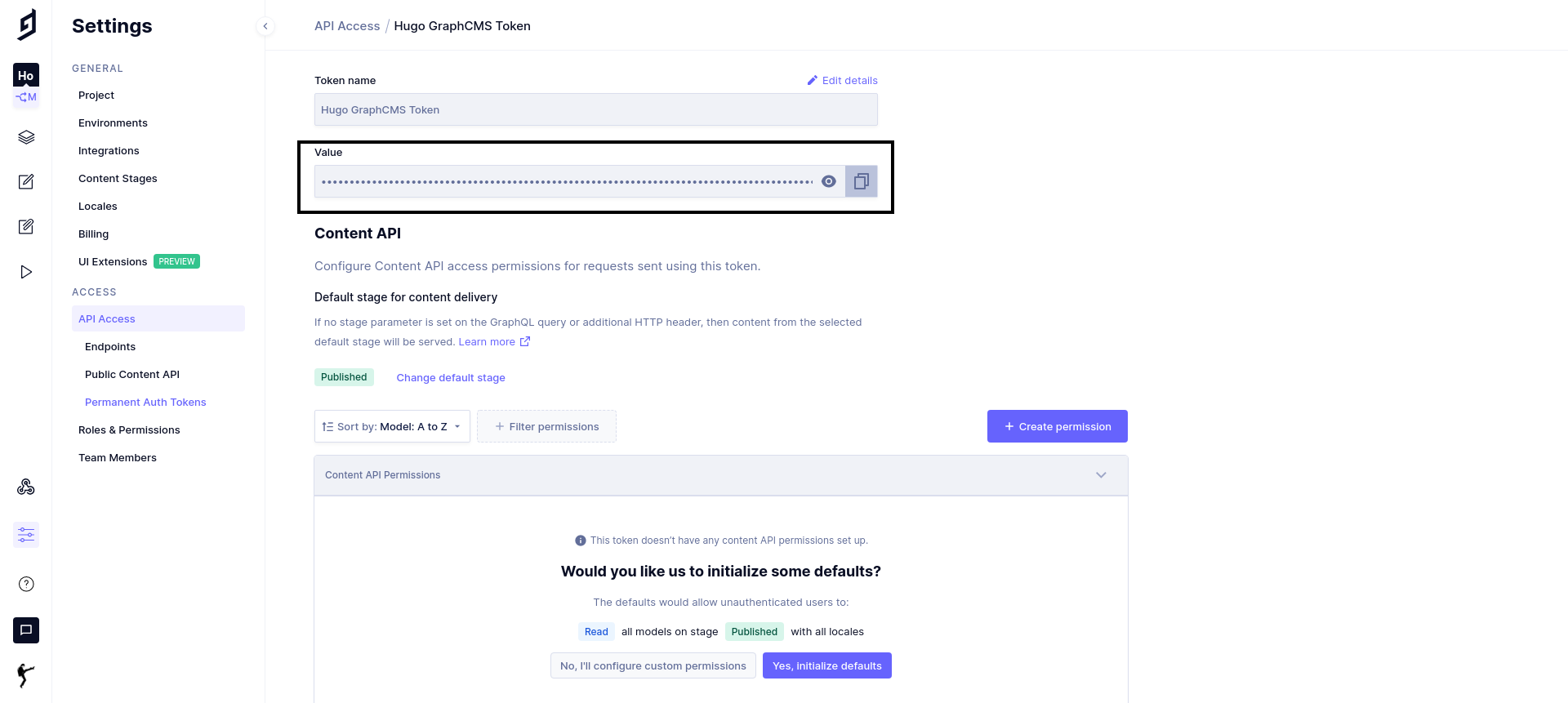
最後にパーミッションを設定する。
デフォルトのYes, initialize defaultsをクリックする。
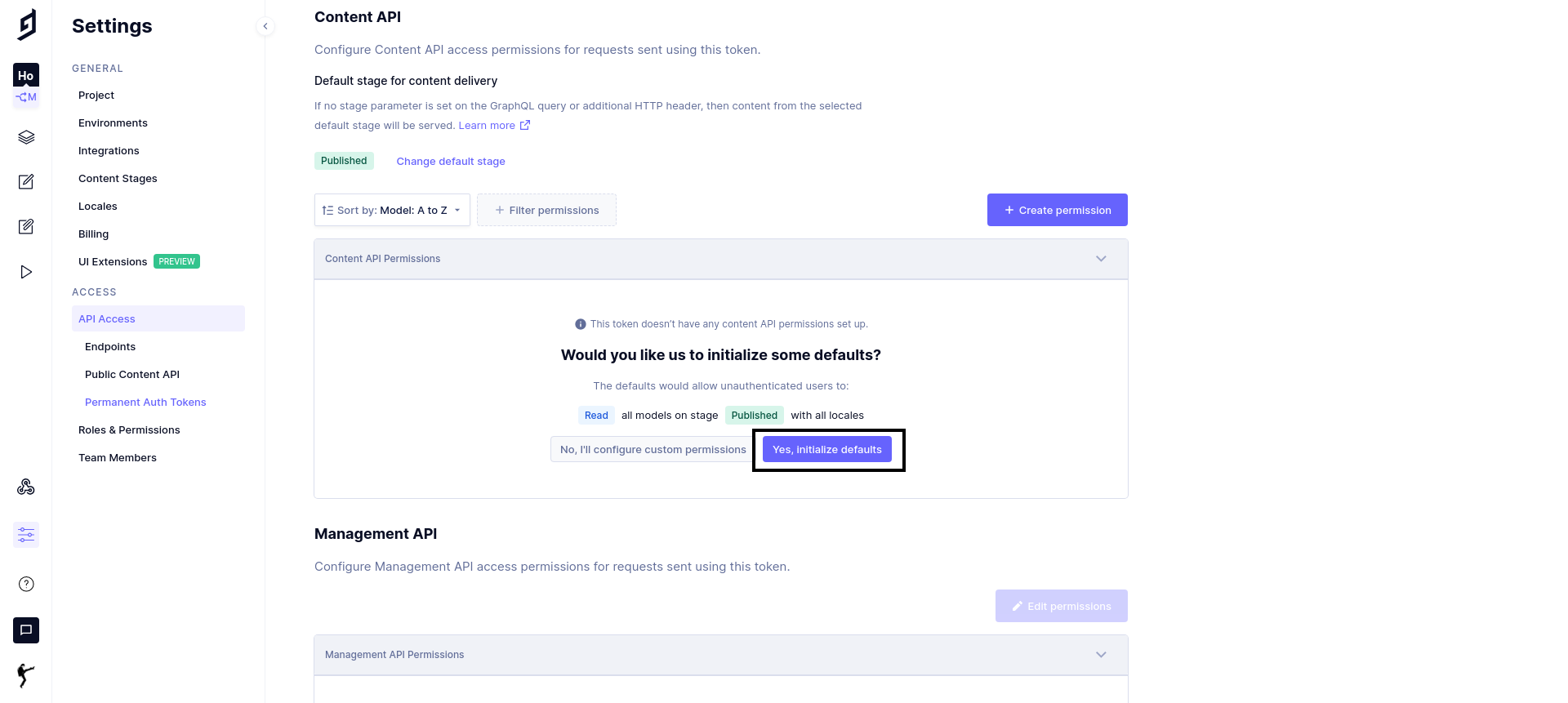
デフォルトでは全モデル、全ロケールのReadパーミッションが付加される。
今回はこれでよいが必要に応じてWriteなども設定できる。
そして先程説明したエンドポイントとトークンを環境変数として使う。
.env
GRAPHCMS_ENDPOINT=https://xxx.graphcms.com/v2/xxxxxxxx/master
GRAPHCMS_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
GraphCMSのAPIを叩く
砂場遊び
まずは手始めに簡単なリクエストを投げる。
環境変数が設定されていない場合は直接入力してもよい。
curlの場合
curl -X POST ${GRAPHCMS_ENDPOINT}
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${GRAPHCMS_TOKEN}" \
-d '{"query":"{posts {title body}}"}' \
結果
{"data":{"posts":[{"title":"初めての投稿","body":"ブログ始めました。 \n三日坊主にならないようがんばります。}]}}
vs codeのREST Clientを使っているならこんな感じでリクエストすればよい(環境変数は.envで定義)。
POST {{$dotenv GRAPHCMS_ENDPOINT}}
Content-Type: application/json
Authorization: Bearer {{$dotenv GRAPHCMS_TOKEN}}
{
"query": "{posts {title body}}"
}
ポイントとしてはGraphCMSというよりはGraphQLの仕様だが、メソッドはPOSTでクエリー内容をリクエストボディのjson形式で投げる。
RESTと違い、リソースつまりエンドポイントは1つ。メソッドも1つ。
レスポンスで受け取る内容(データ形式)はリクエストのクエリーで自由にカスタマイズできる。
上記の場合はtitleとbodyを要求しているので結果もその2つを返している。
今回は紹介しないけども、GraphQLで感嘆したのはリファレンス設定とかない全く独立した複数のモデルの内容も一度のリクエストで取得できることだ。
(その分レスポンスのデータ形式も複雑になるが)
PythonでGraphQLを実行する
PythonでGraphQLを扱う場合gqlなどのライブラリを使うと簡単である。
しかし今回は非同期処理とかの複雑なことは考えていないのでシンプルに標準モジュールのurllibで実装することにした。
まずは上記APIコールをPythonに移植。
import json
import urllib.request
GRAPHCMS_ENDPOINT='https://xxx.graphcms.com/v2/xxxxxxxx/master'
GRAPHCMS_TOKEN='xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
headers = {'Authorization': f'Bearer {GRAPHCMS_TOKEN}'}
query = {"query": "{posts {title body}}"}
req = urllib.request.Request(GRAPHCMS_ENDPOINT,
data=json.dumps(query).encode(),
headers=headers)
with urllib.request.urlopen(req) as response:
payload = json.loads(response.read())
status_code = response.getcode()
print(status_code, payload)
キモになるのはもちろん以下のクエリー部分だが
query = {"query": "{posts {title body}}"}
この程度のシンプルなクエリーならまだよいが、通常は可読性を考慮してこういうふうに書きたい。
query = {
"query": "{
posts {
title
body
}
}"
}
可読性の向上に加えてGraphCMSのAPI Playgroundで試したクエリーを直接コピーしたほうが便利である。
しかしGraphQLのクエリーには改行コードを入れてはいけないので上記はエラーになる。
そこでスクリプト内で変換をかける。
これらを考慮した完成版がこちら。
app/__main__.py
# -*- mode: python -*- -*- coding: utf-8 -*-
import json
import os
import pathlib
import re
import urllib.request
from dotenv import load_dotenv
APP_DIR = os.path.abspath(os.path.dirname(__file__))
PROJECT_DIR = pathlib.Path(APP_DIR).parent
HUGO_CONTENT_DIR = os.path.join(PROJECT_DIR, 'content', 'post')
dotenv_path = os.path.join(PROJECT_DIR, '.env')
load_dotenv(dotenv_path)
class GraphcmsManager(object):
def __init__(self, endpoint, token):
self.endpoint = endpoint
self.headers = {'Authorization': f'Bearer {token}'}
def __format_query(self, s):
s = re.sub(r'\s+', '' ' ', s).replace('\n', ' ')
return {'query': f'{s}'}
def __query_statement(self):
return '''\
{
posts {
id
title
slug
date
eyecatch {
url
}
body
tag
}
}'''
def query(self, data=None, is_raw=True):
if not data:
data = self.__query_statement()
if is_raw:
data = self.__format_query(data)
req = urllib.request.Request(self.endpoint,
data=json.dumps(data).encode(),
headers=self.headers)
status_code = 500
try:
with urllib.request.urlopen(req) as response:
payload = json.loads(response.read())
status_code = response.getcode()
except urllib.error.HTTPError as e:
payload = {'error': e.reason}
except urllib.error.URLError as e:
payload = {'error': e.reason}
except Exception as e:
payload = {'error': str(e)}
return status_code, payload
def gen_hugo_contents(self, payload):
result = list()
data = (payload.get('data'))
for model, content_list in data.items():
for x in content_list:
data_map = dict()
front_matter = f'title: "{x["title"]}"\n'
front_matter += f'slug: "{x["slug"]}"\n'
front_matter += f'date: {x["date"]}\n'
eyecatch = x.get('eyecatch')
if eyecatch:
front_matter += f'featured_image: {eyecatch["url"]}\n'
tag = x.get('tag')
if tag:
front_matter += f'tags: {str(tag)}\n'
data_map['front_matter'] = front_matter
data_map['body'] = x['body']
data_map['filepath'] = f'{x["id"]}.md'
result.append(data_map)
return result
def write(self, data):
for x in data:
fullpath = os.path.join(HUGO_CONTENT_DIR, x['filepath'])
os.makedirs(os.path.dirname(fullpath), exist_ok=True)
with open(fullpath, 'w') as f:
text = f'---\n{x["front_matter"]}---\n{x["body"]}'
f.write(text)
def main():
endpoint = os.getenv('GRAPHCMS_ENDPOINT', 'http://localhost')
token = os.getenv('GRAPHCMS_TOKEN', 'my-token')
G = GraphcmsManager(endpoint=endpoint, token=token)
status_code, payload = G.query()
if status_code != 200:
print(payload)
return
data = G.gen_hugo_contents(payload)
G.write(data)
if __name__ == "__main__":
main()
クエリー部分はgen_hugo_contentsという関数で定義しているが、定数でも構わない。
ただ、今後動的にクエリーを作成したい場合を考慮して関数化している。
コンテンツ取得、ビルドおよび開発サーバ起動
python -m app
hugo server
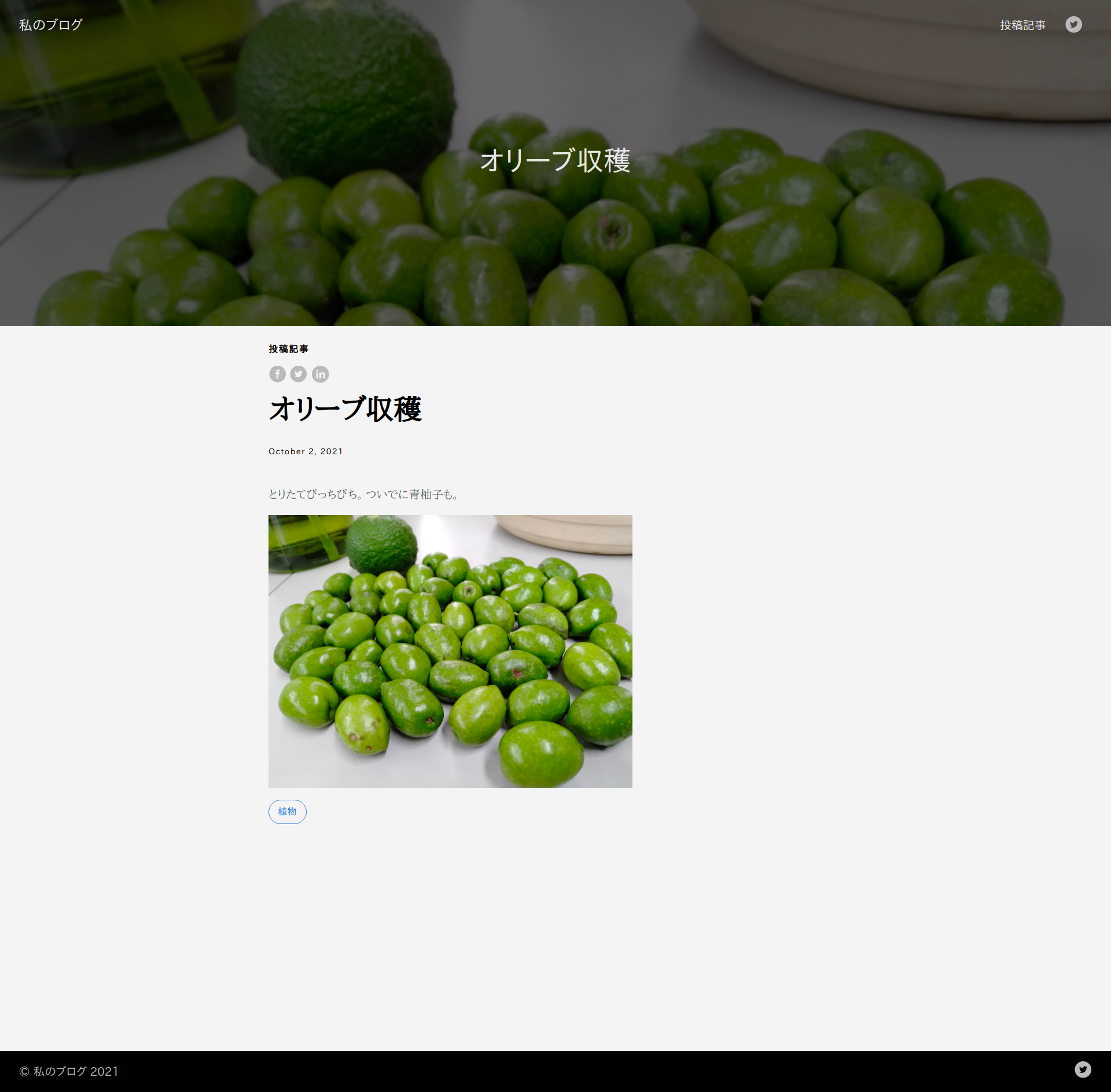
ここまでのソース → Release v1.2 · higebobo/hugo-graphcms-blog
まとめ
HugoがWEB-APIとお話する方法がわからないといってヘッドレスCMSとの連携を諦めてはいけない。
適切なフロントマターとMarkdown形式の本文を作成してcontentディレクトリに放り込む方法さえ提供すれば後はHugoが良きに計らってくれるのだ。
次回はGithub Actionsを利用してGraphCMSのコンテンツ更新とともにビルド、そしてGithub Pagesでの公開について解説する。
と、淡々と書いたが一筋縄ではいかない。。。乞うご期待。