JapanRにおけるHadley Wickham氏の発言の衝撃
Rは好きだけど学のない私は、2024年12月7日(土)開催のJapanRに参加して、世の中にはどえらい人たちがいることを再認識しました。衝撃的なことはいろいろありましたが、その中でも最高の衝撃は、Hadley Wickham神が示したこのスライド。

ぱあくえっとってなに??(追記:parquet(パルケ)は、フランス語で「寄せ木張り(床)」を意味します。また、英語では「パーケット」と読みます。ということをGeminiが教えてくれました)
このスライドで聴講者も笑っていたので、結構有名なファイル形式なんだろうけど、ということはみんなもはやcsvファイルは使っていないのか?
いろいろな疑問が出てきますが、今は生成AIに「parquetファイルの読み込み、書き出しを行うRコード教えて」と訊けばすぐに教えてくれるいい時代です。とりあえず
arrow::write_parquet()
arrow::read_parquet()
を使えば、なんとかなりそう。そこで、csvより100倍くらいparquetの方が速い(Hadley神のご託宣)のか、やってみましょう。ついでに、私がファイルサイズ低減のために使っているrdsファイルも相当いいと思っているので、この3種類について比較します。
なお、持っているPCがプアとは言いませんがものすごく高性能でもないので、とりあえず「まずまず大きい」くらいのデータを使ってやることにしました。
PCスペック、Rバージョン
- プロセッサ 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz
- 実装 RAM 8.00 GB (7.65 GB 使用可能)
- GPU Intel(R) iris(R) Xe Graphics 3.8GB
- システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
- エディション Windows 11 Home バージョン 23H2
- Rバージョン 4.4.2
- コードエディタ Positron 2024.12.0-96
使用データ
協会けんぽの「加入者基本情報、医療費基本情報」(https://www.kyoukaikenpo.or.jp/g7/cat740/sb7200/sbb7204/)
「加入者基本情報、医療費基本情報(令和5年度)」
「加入者基本情報、医療費基本情報(令和4年度)」
の2ヶ年度分のデータを結合した4,621,755行×11列のデータを使ってみました。なお、このデータは列名のみ日本語だったので、エラー回避のため列名を変更してあります。
> df
ym pref_code kubun sex age nyugai disease n n_days tensu ten_inc_medicine
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 202204 01 1 1 2 1 0505 1 25 33780 33780
2 202204 01 1 1 2 1 0606 1 2 10878 10878
3 202204 01 1 1 2 1 1011 4 20 269488 269488
4 202204 01 1 1 2 1 1113 1 4 53564 53564
5 202204 01 1 1 2 1 1901 1 11 62949 62949
6 202204 01 1 1 2 1 1904 1 5 73756 73756
7 202204 01 1 1 2 1 1905 1 7 20014 20014
8 202204 01 1 1 2 2 NA 1 1 410 410
9 202204 01 1 1 2 2 0101 21 25 28880 32577
10 202204 01 1 1 2 2 0103 1 1 198 198
# ℹ 4,621,745 more rows
# ℹ Use `print(n = ...)` to see more rows
比較ファイル形式とRの関数
readr::read_csv() #csvを高速で読みこむ定番関数
readr::write_csv() #csvを高速で書きこむ定番関数
data.table::fread() #csv読み出しがとても速いことで有名
readRDS() #Rでのみ使える?rdsファイルを読みこむ関数
writeRDS() #rdsファイルを書きこむ関数。ファイルサイズがcsvよりも小さくなる
arrow::write_parquet() #今回の主役paquetファイルを書きこむ関数
arrow::read_parquet() #今回の主役paquetファイルを読みこむ関数
各関数30回ずつ時間測定するRコード
今回行ったのは上記7つのR関数を使ってそれぞれの読み込み書き込み時間測定を30回繰り返し、その結果の箱ひげ図を作ることです。以下Rコードを示しますが、適宜皆様の持っているdataをdfとして読み込んでいただければそのまま使えると思います。
library(conflicted)
library(tidyverse)
library(arrow)
library(data.table)
library(plotly)
library(htmlwidgets)
conflict_prefer('filter', 'dplyr')
conflict_prefer('layout', 'plotly')
#df <- (read***("filename")でdfを適宜読み込んでください。
# 繰り返し計測回数
n_iterations <- 30
# 計測関数
measure_time <- function(func) {
replicate(n_iterations, {
start_time <- Sys.time()
func()
as.numeric(Sys.time() - start_time, units = "secs")
})
}
# ファイル操作の定義(入出力ファイル名は適宜変更してください。)
file_operations <- list(
csv_write = list(func = write_csv, args = list(x = df, file = "kyokai_kenpo_202204_202403.csv")),
csv_read = list(func = read_csv, args = list(file = "kyokai_kenpo_202204_202403.csv")),
csv_fread = list(func = fread, args = list(file = "kyokai_kenpo_202204_202403.csv")),
rds_write = list(func = saveRDS, args = list(object = df, file = "kyokai_kenpo_202204_202403.rds")),
rds_read = list(func = readRDS, args = list(file = "kyokai_kenpo_202204_202403.rds")),
parquet_write = list(func = write_parquet, args = list(x = df, sink = "kyokai_kenpo_202204_202403.parquet")),
parquet_read = list(func = read_parquet, args = list(file = "kyokai_kenpo_202204_202403.parquet"))
)
# 各操作の計測
results <- map(file_operations, ~measure_time(function() do.call(.x$func, .x$args)))
results_long <- map_dfr(results, ~tibble(time = .), .id = "operation") |>
mutate(iteration = rep(1:n_iterations, times = length(results)))
なお、plotlyで作った箱ひげ図をhtmlファイルに出力して掲載しようと思いましたが、qiitaにはhtmlファイルは直接貼れないので、この後の画像ではggplotで作った箱ひげ図を使用しています。
時間測定結果
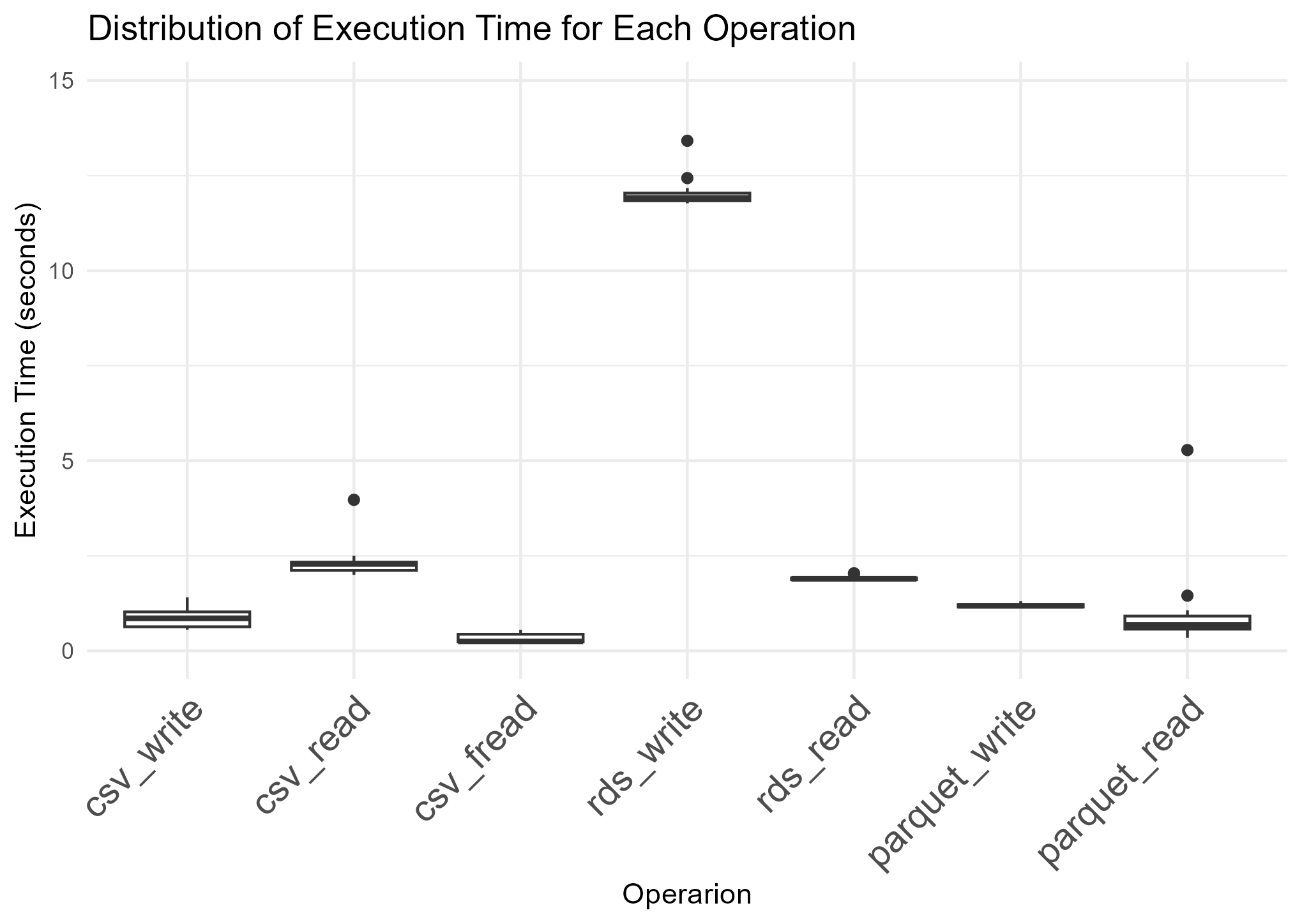
writeRDS()関数だけが極端に時間がかかっています。
read関数の読み込み時間比較
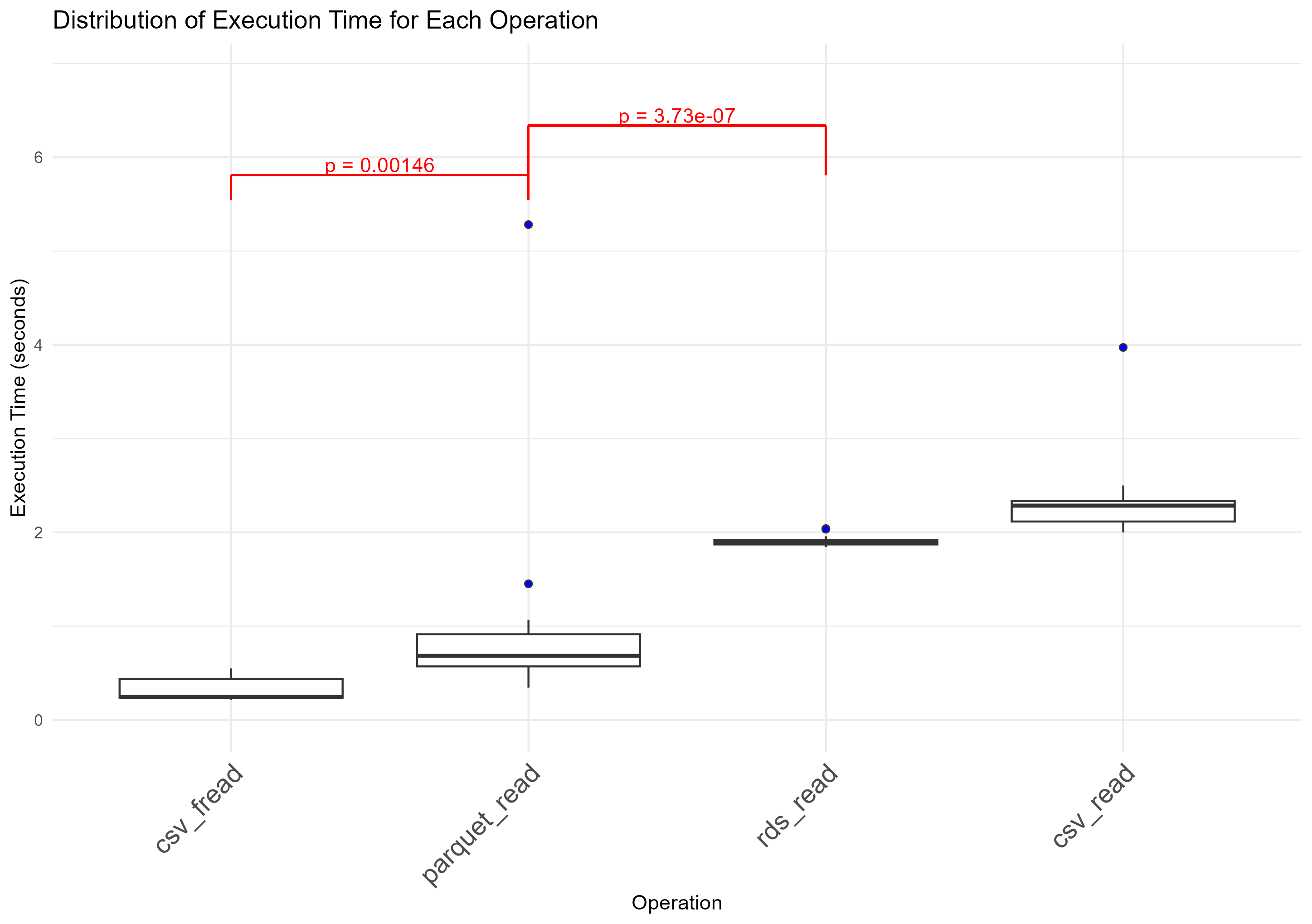
read_panquet() << readRDS() < read_csv()ではありますが、fread()の速さにはかないませんでした。また、read_panquet()の分散の大きさも気になるところです。
write関数の書き込み時間比較(writeRDS除く)
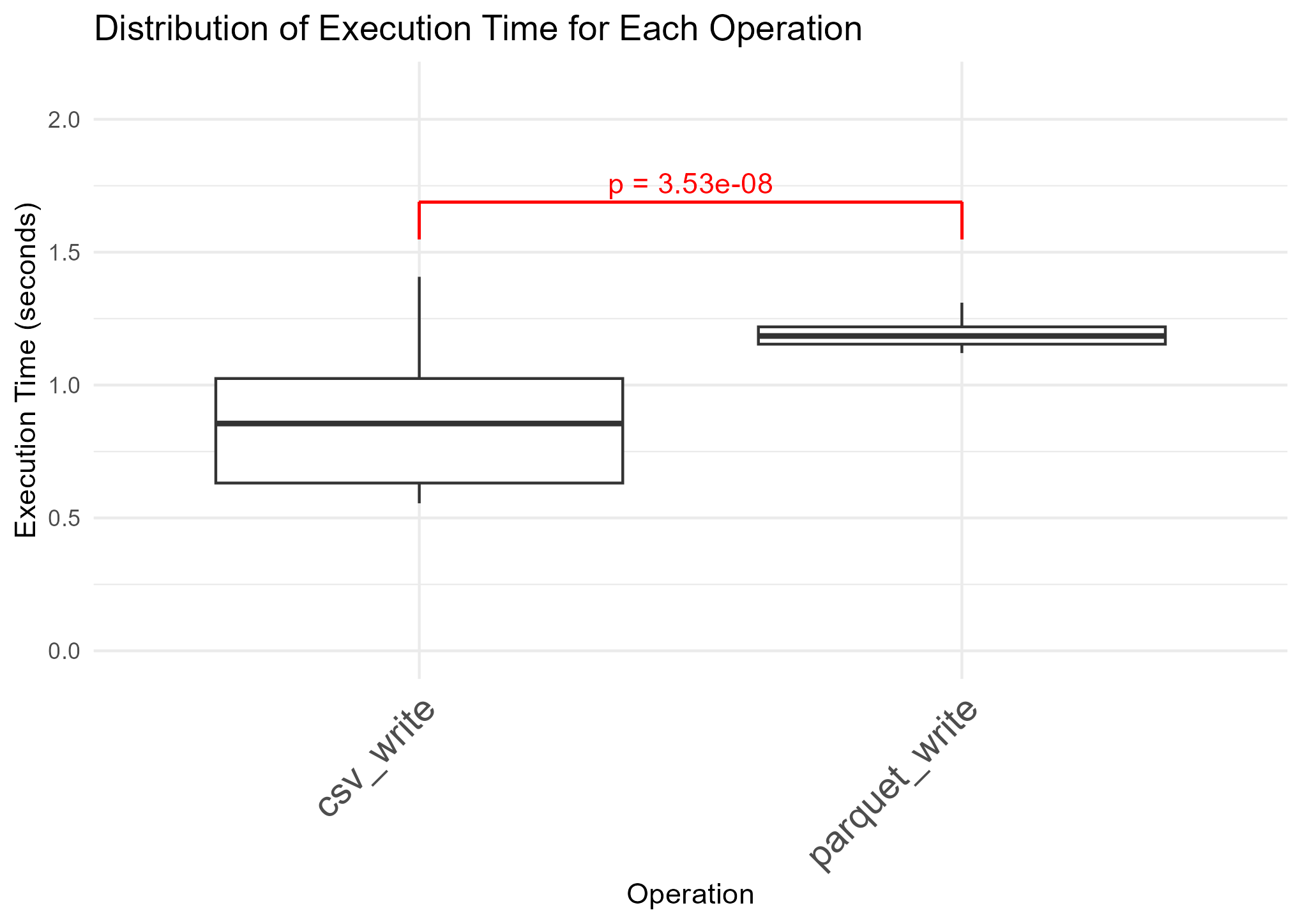
write_panquet()はwrite_csv()より明らかに劣勢です。ただ、read_panquet()は時間のばらつきが大きかったのに対し、write_paquet()の書き込み時間は安定しているのが美点です。
書き込んだファイルサイズの比較
| ファイル形式 | サイズ(バイト) | サイズ(MB) | csvからの低減率 |
|---|---|---|---|
| csv | 193,341,859 | 184.39 | - |
| parquet | 66,244,045 | 63.18 | -65.7% |
| rds | 53,541,175 | 51.06 | -72.3% |
ご覧のとおり、parquetファイルはcsvファイルの約3分の1くらいになりますが、それよりもrdsファイルの方がファイルサイズが小さい!rdsとparquetで比較すると約2割rdsの方が小さいというのは相当なメリットで、writeRDS()に時間がかかったとしてもRDSファイルにする、という方もいるかもしれません。
まとめ parquetに絶対的優位性はないが…
今回はかなり簡単な実験でした。データサイズがこれよりも大きいときにどうなるかはもう少し時間をかけて調べてみたいところです。ただ、今回の実験ではparquetが全ての面でcsvやRDSを上回っているわけでなかった、というのは厳然たる事実です。
だからといって「じゃあ今までどおりcsv使うか」というと、答えはNoです。やはり総合的にはparquetが最も使いやすそうと認めざるを得ません。ファイルサイズが3分の1になるのは大きなメリットですし、rdsのようにRに特化したファイル形式でもありません。やはりこれから私はparquetを使うことになると思うのでした。
最後に、Hadley Wickham氏、並びにJapanR発表者の皆様、スタッフの皆様に心より感謝申し上げる次第です。